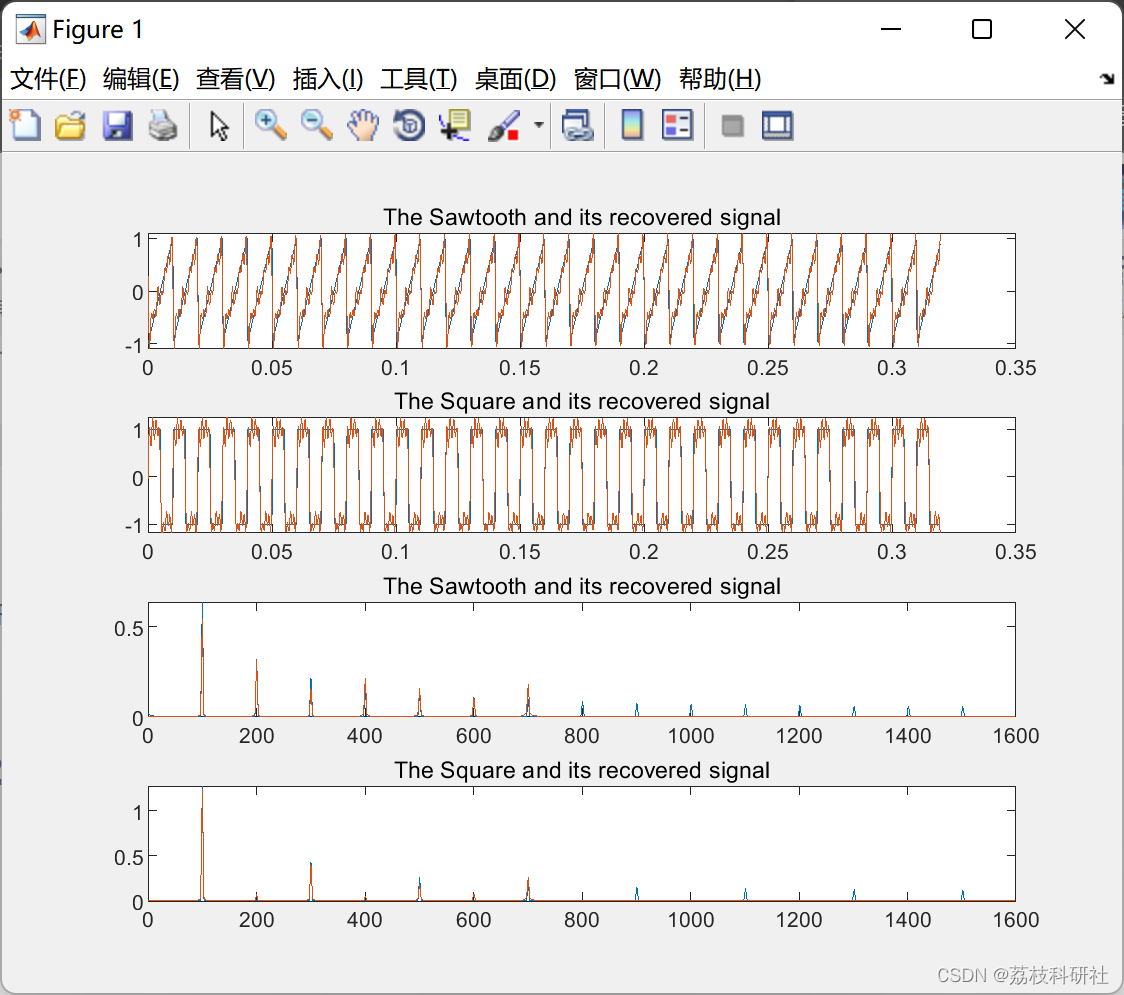
这是北美产险精算学会CAS网站上的一个案例,对案例略作修改后进行验证。
原始数据是一个简单的分组数据:
| Class | AOI | Terr | Exposure | Claims |
| 1 | Low | 1 | 7 | 6 |
| 2 | Medium | 1 | 108 | 44 |
| 3 | High | 1 | 179 | 105 |
| 4 | Low | 2 | 130 | 62 |
| 5 | Medium | 2 | 126 | 82 |
| 6 | High | 2 | 129 | 120 |
| 7 | Low | 3 | 143 | 84 |
| 8 | Medium | 3 | 126 | 101 |
| 9 | High | 3 | 40 | 46 |
(1)采用泊松分布拟合出险频率带有权重参数的结果如下:
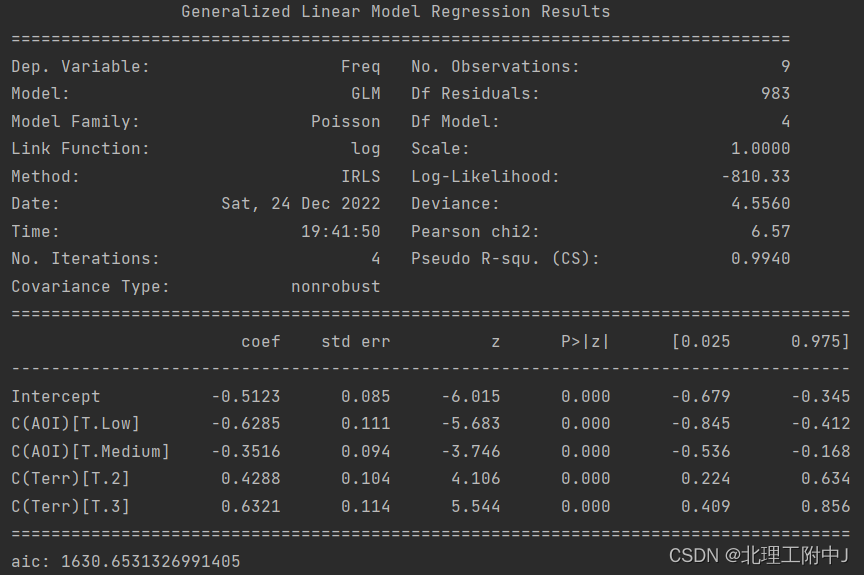

从拟合优度指标来看,模型的整体拟合效果和参数的显著性都还可以。
从拟合结果来看,除了第1组之外,其它组的拟合值还算不错。第1组的拟合值与观测值的差别较大,主要是因为第1组的风险数量太少,可能会有很大的不稳定性造成的。
(2)如果采用泊松分布拟合出险频率、但是不带有权重参数,那么模型的结果如下:
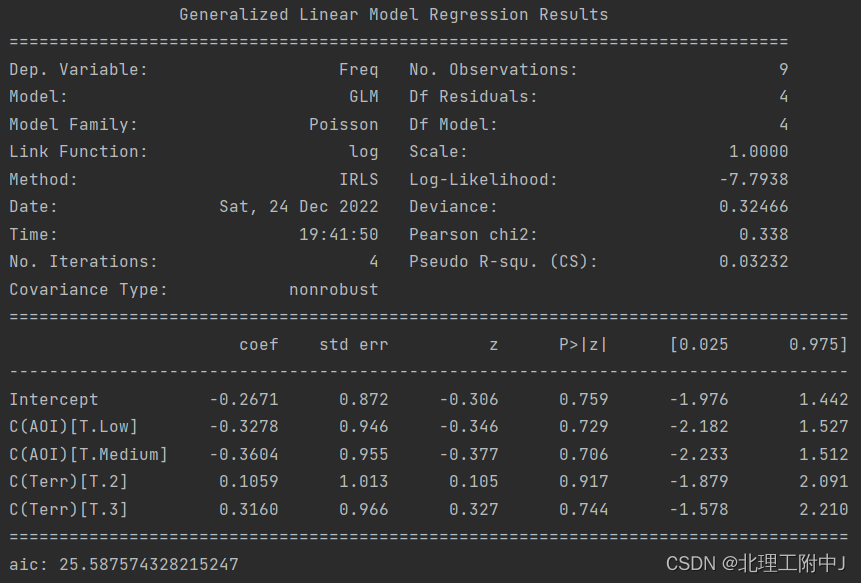

可以看到,如果不带有权重,模型的整体拟合效果很差,伪R方只有0.03232,比前面的0.9940相差很大。而且,各个参数的显著性检验都没有通过。从拟合结果来看,各个组的拟合值与观测值也差别很大。
从这个案例可以看到,模型含有权重是非常重要的。
(3)建模时必须对2个分组特征采用分类变量的形式,尽管原始数据地区特征看似数值型。如果直接用数值型的分组特征做建模,那么模型的结果如下:
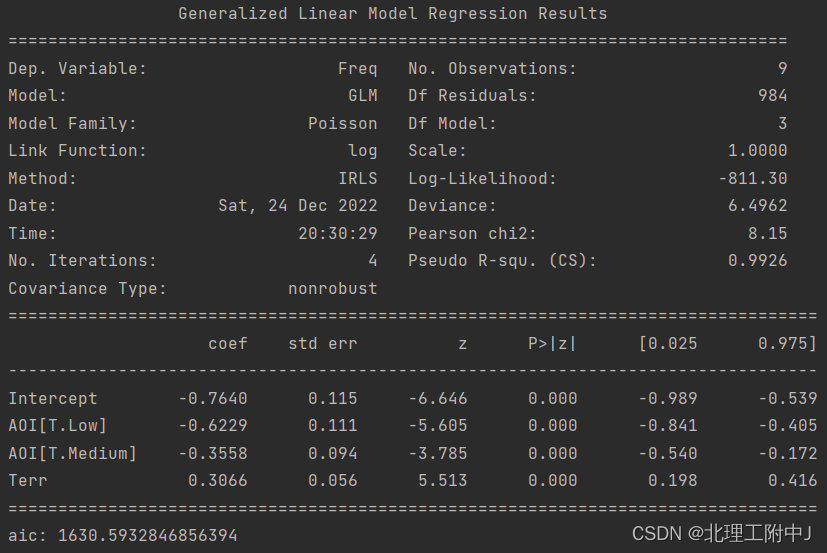

从模型的拟合优度指标来看,其实指标值都还不错,伪R方高达0.9926。但是,从拟合值与观测值的差距来看, 拟合结果与第一个模型结果相比,差距大了一些。
从这个案例可以看到,模型对分类特征采用分类变量进行建模是非常必要的。
(精算部落)










![[思维模式-14]:《复盘》-2- “知”篇 - 复盘之道](https://img-blog.csdnimg.cn/d6f56334e34b49ffb508aa30c0e12337.png)