大纲
- 公式推导
- 参数估计
- 高斯分布运算
- 高斯分布性质
- 高斯过程(Gaussian process)
概念区分
- 边缘分布(marginal distribution)和联合分布
- 概率密度函数和概率分布函数
1. 多元高斯分布公式推导
首先我们知道一元高斯分布是:
N
(
x
∣
u
,
σ
2
)
=
1
2
π
σ
2
e
x
p
[
−
1
2
σ
2
(
x
−
u
)
2
]
N(x|u,\sigma^2)=\frac{1}{\sqrt{2\pi \sigma^2}}exp[-\frac{1}{2\sigma^2}(x-u)^2]
N(x∣u,σ2)=2πσ21exp[−2σ21(x−u)2], 拓展到高维时:
N
(
x
‾
∣
u
‾
,
Σ
)
=
1
(
2
π
)
D
/
2
1
∣
Σ
∣
1
/
2
e
x
p
[
−
1
2
(
x
‾
−
u
‾
)
T
Σ
−
1
(
x
‾
−
u
‾
)
]
N(\overline x | \overline u, \Sigma)=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\Sigma|^{1/2}}exp[-\frac{1}{2}(\overline x-\overline u)^T\Sigma^{-1}(\overline x-\overline u)]
N(x∣u,Σ)=(2π)D/21∣Σ∣1/21exp[−21(x−u)TΣ−1(x−u)]其中,
x
‾
\overline x
x 表示维度为 D 的向量,
u
‾
\overline u
u 则是这些向量的平均值,
Σ
\Sigma
Σ 表示所有向量
x
‾
\overline x
x 的协方差矩阵。
现在进行推导。为了简单起见,假设所有变量都是相互独立的,即对于概率分布函数 f ( x 0 , x 1 , … , x n ) = f ( x 0 ) f ( x 1 ) . . . f ( x n ) f(x_0,x_1,…,x_n)=f(x_0)f(x_1)...f(x_n) f(x0,x1,…,xn)=f(x0)f(x1)...f(xn) 成立。
假设有很多变量 x ‾ = [ x 1 x 2 ] \overline x=\begin{bmatrix} x_1 \\ x_2 \end{bmatrix} x=[x1x2],它们的均值为 u ‾ = [ u 1 u 2 ] \overline u=\begin{bmatrix} u_1 \\ u_2 \end{bmatrix} u=[u1u2],方差为 σ ‾ = [ σ 1 σ 2 ] \overline \sigma=\begin{bmatrix} \sigma_1 \\ \sigma_2 \end{bmatrix} σ=[σ1σ2]。
由于
x
1
x_1
x1,
x
2
x_2
x2 是相互独立的,所以,
x
‾
\overline x
x 的高斯分布函数可以表示为:
f
(
x
‾
)
=
f
(
x
1
,
x
2
)
=
f
(
x
1
)
f
(
x
2
)
=
1
2
π
σ
1
2
e
x
p
(
−
1
2
(
x
1
−
u
1
σ
1
)
2
)
×
1
2
π
σ
2
2
e
x
p
(
−
1
2
(
x
2
−
u
2
σ
2
)
2
)
=
1
(
2
π
)
2
/
2
(
σ
1
2
σ
2
2
)
1
/
2
e
x
p
(
−
1
2
[
(
x
1
−
u
1
σ
1
)
2
+
(
x
2
−
u
2
σ
2
)
2
]
)
\begin{aligned} f(\overline x) &= f(x_1,x_2) \\ &= f(x_1)f(x_2) \\ &= \frac{1}{\sqrt{2\pi \sigma_1^2}}exp(-\frac{1}{2}(\frac{x_1-u_1}{\sigma_1})^2) \times \frac{1}{\sqrt{2\pi \sigma_2^2}}exp(-\frac{1}{2}(\frac{x_2-u_2}{\sigma_2})^2) \\ &=\frac{1}{(2\pi)^{2/2}(\sigma_1^2 \sigma_2^2)^{1/2}}exp(-\frac{1}{2}[(\frac{x_1-u_1}{\sigma_1})^2+(\frac{x_2-u_2}{\sigma_2})^2]) \end{aligned}
f(x)=f(x1,x2)=f(x1)f(x2)=2πσ121exp(−21(σ1x1−u1)2)×2πσ221exp(−21(σ2x2−u2)2)=(2π)2/2(σ12σ22)1/21exp(−21[(σ1x1−u1)2+(σ2x2−u2)2])接下来,为了推出文章开篇的高维公式,我们要想办法得到协方差矩阵
Σ
\Sigma
Σ。
对于二维的向量
x
‾
\overline x
x 而言,其协方差矩阵为:
Σ
=
[
σ
11
σ
12
σ
12
σ
22
]
=
[
σ
1
2
σ
12
σ
21
σ
2
2
]
\begin{aligned} \Sigma&=&\begin{bmatrix} \sigma_{11} & \sigma_{12} \\ \sigma_{12} & \sigma_{22} \end{bmatrix} \\ &=&\begin{bmatrix} \sigma_1^2 & \sigma_{12} \\ \sigma_{21} & \sigma_{2}^2 \end{bmatrix} \\ \end{aligned}
Σ==[σ11σ12σ12σ22][σ12σ21σ12σ22]
协方差(Covariance)在概率论和统计学中用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。简单来讲,协方差就是衡量两个变量相关性的变量。当协方差为正时,两个变量呈正相关关系(同增同减);当协方差为负时,两个变量呈负相关关系(一增一减)。 而协方差矩阵,只是将所有变量的协方差关系用矩阵的形式表现出来而已。通过矩阵这一工具,可以更方便地进行数学运算。协方差公式为:
C o v ( X , Y ) = E ( X , Y ) − E ( X ) E ( Y ) = ∑ i = 1 n ( x i − x ‾ ) ( y i − y ‾ ) n − 1 Cov(X,Y)=E(X,Y)-E(X)E(Y)=\frac{\sum_{i=1}^n{(x_i-\overline x)(y_i-\overline y)}}{n-1} Cov(X,Y)=E(X,Y)−E(X)E(Y)=n−1∑i=1n(xi−x)(yi−y) 这里的 X X X, Y Y Y表示两个变量空间。用机器学习的话讲,就是样本有 x x x 和 y y y 两种特征,而 X X X 就是包含所有样本的 x x x 特征的集合, Y Y Y就是包含所有样本的 y y y 特征的集合。 x ‾ \overline x x 和 y ‾ \overline y y 是 X X X, Y Y Y 两个特征空间的平均值。
那么假如 Z Z Z 是包含 X X X和 Y Y Y的矩阵,那么计算协方差矩阵时, C o v ( Z ) = E [ ( X − E [ X ] ) ( Y − E [ Y ] ) ⊤ ] = [ C o v ( X , X ) C o v ( X , Y ) C o v ( Y , X ) C o v ( Y , Y ) ] Cov(Z)=\mathrm{E}\left[ (X - \mathrm{E}[X]) (Y - \mathrm{E}[Y])^\top\right]=\begin{bmatrix} Cov(X,X) & Cov(X,Y) \\ Cov(Y,X) & Cov(Y,Y) \end{bmatrix} Cov(Z)=E[(X−E[X])(Y−E[Y])⊤]=[Cov(X,X)Cov(Y,X)Cov(X,Y)Cov(Y,Y)]
这样矩阵中之中每个元素 Σ i j = ( 样本矩阵第 i 列 − 第 i 列均值 ) T ( 样本矩阵第 j 列 − 第 j 列均值 ) 样本数 − 1 \Sigma_{ij}=\frac{(样本矩阵第i列-第i列均值)^T(样本矩阵第j列-第j列均值)}{样本数-1} Σij=样本数−1(样本矩阵第i列−第i列均值)T(样本矩阵第j列−第j列均值)
当 X X X, Y Y Y两个变量独立时, C o v ( X , Y ) Cov(X,Y) Cov(X,Y)为0:
E ( X Y ) = ∑ x ∑ y x × y × p ( x , y ) = ∑ x ∑ y x × y × p x ( x ) × p y ( y ) = ∑ x x × p x ( x ) ∑ y y × p y ( y ) = E ( X ) E ( Y ) \begin{aligned} E(XY) & = \sum_x \sum_y {x \times y \times p(x,y)} \notag \\ & = \sum_x \sum_y x \times y \times p_x(x) \times p_y(y) \notag \\ & = \sum_x{x \times p_x(x)}\sum_y{y \times p_y(y)} \notag \\ & = E(X)E(Y) \notag \end{aligned} E(XY)=x∑y∑x×y×p(x,y)=x∑y∑x×y×px(x)×py(y)=x∑x×px(x)y∑y×py(y)=E(X)E(Y)
由于
x
1
x_1
x1,
x
2
x_2
x2 是相互独立的,所以
σ
12
=
σ
21
=
0
\sigma_{12}=\sigma_{21}=0
σ12=σ21=0。这样,
Σ
\Sigma
Σ 退化成
[
σ
1
2
0
0
σ
2
2
]
\begin{bmatrix} \sigma_1^2 & 0 \\ 0 & \sigma_{2}^2 \end{bmatrix}
[σ1200σ22]。
则
Σ
\Sigma
Σ 的行列式
∣
Σ
∣
=
σ
1
2
σ
2
2
|\Sigma|=\sigma_1^2 \sigma_2^2
∣Σ∣=σ12σ22,代入公式 (4) 就可以得到:
f
(
x
‾
)
=
1
(
2
π
)
2
/
2
∣
Σ
∣
1
/
2
e
x
p
(
−
1
2
[
(
x
1
−
u
1
σ
1
)
2
+
(
x
2
−
u
2
σ
2
)
2
]
)
f(\overline x)=\frac{1}{(2\pi)^{2/2}|\Sigma|^{1/2}}exp(-\frac{1}{2}[(\frac{x_1-u_1}{\sigma_1})^2+(\frac{x_2-u_2}{\sigma_2})^2])
f(x)=(2π)2/2∣Σ∣1/21exp(−21[(σ1x1−u1)2+(σ2x2−u2)2])
这样一来,我们已经推出了公式的左半部分,下面,开始处理右面的 exp 函数。
原始的高维高斯函数的 exp 函数为:
e
x
p
[
−
1
2
(
x
‾
−
u
‾
)
T
Σ
−
1
(
x
‾
−
u
‾
)
]
exp[-\frac{1}{2}(\overline x-\overline u)^T\Sigma^{-1}(\overline x-\overline u)]
exp[−21(x−u)TΣ−1(x−u)],根据前面算出来的
Σ
\Sigma
Σ,我们可以求出它的逆:
Σ
−
1
=
1
σ
1
2
σ
2
2
[
σ
2
2
0
0
σ
1
2
]
\Sigma^{-1}=\frac{1}{\sigma_1^2 \sigma_2^2} \begin{bmatrix} \sigma_2^2 & 0 \\ 0 & \sigma_1^2 \end{bmatrix}
Σ−1=σ12σ221[σ2200σ12]。
接下来根据这个二维的例子,将原始的 exp() 展开:
e
x
p
[
−
1
2
(
x
‾
−
u
‾
)
T
Σ
−
1
(
x
‾
−
u
‾
)
]
=
e
x
p
[
−
1
2
[
x
1
−
u
1
x
2
−
u
2
]
1
σ
1
2
σ
2
2
[
σ
2
2
0
0
σ
1
2
]
[
x
1
−
u
1
x
2
−
u
2
]
]
=
e
x
p
[
−
1
2
[
x
1
−
u
1
x
2
−
u
2
]
1
σ
1
2
σ
2
2
[
σ
2
2
(
x
1
−
u
1
)
σ
1
2
(
x
2
−
u
2
)
]
]
=
e
x
p
[
−
1
2
σ
1
2
σ
2
2
[
σ
2
2
(
x
1
−
u
1
)
2
+
σ
1
2
(
x
2
−
u
2
)
2
]
]
=
e
x
p
[
−
1
2
[
(
x
1
−
u
1
)
2
σ
1
2
+
(
x
2
−
u
2
)
2
σ
2
2
]
]
\begin{aligned} exp[-\frac{1}{2}(\overline x-\overline u)^T\Sigma^{-1}(\overline x-\overline u)] &= exp[-\frac{1}{2} \begin{bmatrix} x_1-u_1 \ \ \ x_2-u_2 \end{bmatrix} \frac{1}{\sigma_1^2 \sigma_2^2} \begin{bmatrix} \sigma_2^2 & 0 \\ 0 & \sigma_1^2 \end{bmatrix} \begin{bmatrix} x_1-u_1 \\ x_2-u_2 \end{bmatrix}] \\ &= exp[-\frac{1}{2} \begin{bmatrix} x_1-u_1 \ \ \ x_2-u_2 \end{bmatrix} \frac{1}{\sigma_1^2 \sigma_2^2} \begin{bmatrix} \sigma_2^2(x_1-u_1) \\ \sigma_1^2(x_2-u_2) \end{bmatrix}] \\ &= exp[-\frac{1}{2\sigma_1^2 \sigma_2^2}[\sigma_2^2(x_1-u_1)^2+\sigma_1^2(x_2-u_2)^2]] \\ &= exp[-\frac{1}{2}[\frac{(x_1-u_1)^2}{\sigma_1^2}+\frac{(x_2-u_2)^2}{\sigma_2^2}]] \end{aligned}
exp[−21(x−u)TΣ−1(x−u)]=exp[−21[x1−u1 x2−u2]σ12σ221[σ2200σ12][x1−u1x2−u2]]=exp[−21[x1−u1 x2−u2]σ12σ221[σ22(x1−u1)σ12(x2−u2)]]=exp[−2σ12σ221[σ22(x1−u1)2+σ12(x2−u2)2]]=exp[−21[σ12(x1−u1)2+σ22(x2−u2)2]]
展开到最后,发现推出了原公式。说明原公式
N
(
x
‾
∣
u
‾
,
Σ
)
=
1
(
2
π
)
D
/
2
1
∣
Σ
∣
1
/
2
e
x
p
[
−
1
2
(
x
‾
−
u
‾
)
T
Σ
−
1
(
x
‾
−
u
‾
)
]
N(\overline x | \overline u, \Sigma)=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\Sigma|^{1/2}}exp[-\frac{1}{2}(\overline x-\overline u)^T\Sigma^{-1}(\overline x-\overline u)]
N(x∣u,Σ)=(2π)D/21∣Σ∣1/21exp[−21(x−u)TΣ−1(x−u)]是成立的。
2. 参数估计
如果给定了很多数据点,并且知道它们服从某个高斯分布,我们要求高斯分布的参数(
μ
μ
μ 和
Σ
Σ
Σ),估计模型参数的方法有很多,最常用的就是极大似然估计(MLE)。对于一维的高斯模型假如有m个数据点,则似然函数:
f
(
x
1
,
x
2
,
…
,
x
m
)
=
∏
i
=
1
m
1
2
π
σ
e
x
p
(
−
(
x
i
−
μ
~
)
2
2
σ
2
)
f(x_1, x_2, \dots, x_m)=\prod_{i=1}^{m}\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(x_i-\tilde \mu)^2}{2\sigma^2})
f(x1,x2,…,xm)=i=1∏m2πσ1exp(−2σ2(xi−μ~)2)取对数后求导,令导数为 0 得到似然方程。
∂
ln
f
∂
μ
‾
=
1
σ
2
∑
i
=
1
m
(
x
i
−
μ
~
)
=
0
\frac{\partial \ln f}{\partial \overline \mu}=\frac{1}{\sigma^2}\sum_{i=1}^{m}{(x_i-\tilde \mu)}=0
∂μ∂lnf=σ21i=1∑m(xi−μ~)=0
∂
ln
f
∂
σ
=
−
m
σ
+
1
σ
3
∑
i
=
1
m
(
x
i
−
μ
~
)
=
0
\frac{\partial \ln{f}}{\partial \sigma}=-\frac{m}{\sigma}+\frac{1}{\sigma^3}\sum_{i=1}^m{(x_i-\tilde \mu)}=0
∂σ∂lnf=−σm+σ31i=1∑m(xi−μ~)=0得到
μ
~
=
1
m
∑
i
=
1
m
x
i
\tilde \mu=\frac{1}{m}\sum_{i=1}^m{x_i}
μ~=m1∑i=1mxi,
σ
=
1
m
∑
i
=
1
m
(
x
i
−
μ
~
)
2
\sigma=\sqrt{\frac{1}{m}\sum_{i=1}^m{(x_i-\tilde \mu)^2}}
σ=m1∑i=1m(xi−μ~)2
多维高斯分布时,假如有m个p维向量
x
x
x,参数估计为: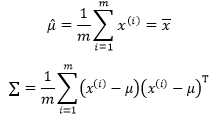
在计算样本协方差矩阵时,我们要使用无偏估计,即将分母由
m
m
m 改为
(
m
−
1
)
(m-1)
(m−1)。[^1]
3. 高斯分布运算
3.1 一元高斯分布相乘
假设
p
(
x
1
)
=
N
(
x
∣
μ
1
,
σ
1
)
,
p
(
x
2
)
=
N
(
x
∣
μ
2
,
σ
2
)
p(x_1)=\mathcal{N}(x\vert \mu_1,\sigma_1), \, p(x_2)=\mathcal{N}(x\vert \mu_2,\sigma_2)
p(x1)=N(x∣μ1,σ1),p(x2)=N(x∣μ2,σ2)均是关于变量
x
x
x的分布,得两个高斯分布相乘仍为缩放的高斯分布:
p
(
x
1
)
p
(
x
2
)
=
e
−
1
2
σ
1
2
(
x
−
μ
1
)
2
e
−
1
2
σ
2
2
(
x
−
μ
2
)
2
=
e
−
1
2
(
σ
1
2
+
σ
2
2
)
x
2
−
2
(
μ
1
σ
2
2
+
μ
2
σ
1
2
)
x
+
constant
σ
1
2
σ
2
2
\begin{align*} p(x_1)p(x_2) & = e^{-\frac{1}{2\sigma_1^2}\, (x-\mu_1)^2}e^{-\frac{1}{2\sigma_2^2}\, (x-\mu_2)^2} \\ & =e^{-\frac{1}{2}\frac{(\sigma_1^2\, +\sigma_2^2\, )\, x^2-2(\mu_1\, \sigma_2^2+\mu_2\, \sigma_1^2)x+\text{constant}}{\sigma_1^2\sigma_2^2}}\end{align*}
p(x1)p(x2)=e−2σ121(x−μ1)2e−2σ221(x−μ2)2=e−21σ12σ22(σ12+σ22)x2−2(μ1σ22+μ2σ12)x+constant则高斯分布的参数:
μ
=
μ
1
σ
2
2
+
μ
2
σ
1
2
σ
1
2
+
σ
2
2
,
σ
=
σ
1
2
σ
2
2
σ
1
2
+
σ
2
2
\begin{align*} \mu & = \frac{\mu_1\sigma_2^2+\mu_2\sigma_1^2}{\sigma_1^2+\sigma_2^2} \ ,\ \ \sigma = \sqrt{\frac{\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2}} \end{align*}
μ=σ12+σ22μ1σ22+μ2σ12 , σ=σ12+σ22σ12σ22上式可写为如下形式,从而推广至
n
n
n个一维高斯分布相乘:
μ
=
(
μ
1
σ
1
2
+
μ
2
σ
2
2
)
σ
2
,
1
σ
2
=
1
σ
1
2
+
1
σ
2
2
\begin{align*} \mu &= (\frac{\mu_1}{\sigma_1^2}+\frac{\mu_2}{\sigma_2^2})\sigma^2 \ ,\ \ \frac{1}{\sigma^2} = \frac{1}{\sigma_1^2} + \frac{1}{\sigma_2^2} \end{align*}
μ=(σ12μ1+σ22μ2)σ2 , σ21=σ121+σ221
新函数等价于正态分布
N
(
μ
,
σ
2
)
N(\mu,\sigma^2)
N(μ,σ2) 的概率密度函数乘以缩放因子
A
A
A 。其中,缩放因子
A
=
e
−
(
μ
1
−
μ
2
)
2
2
(
σ
1
2
+
σ
2
2
)
2
π
(
σ
1
2
+
σ
2
2
)
A=\frac{e^{-\frac{\left(\mu_1-\mu_2\right)^2}{2(\sigma_1^2+\sigma_2^2)}}}{\sqrt{2\pi\left( \sigma_1^2+\sigma_2^2\right)}}
A=2π(σ12+σ22)e−2(σ12+σ22)(μ1−μ2)2
3.2 多元高斯分布相乘
μ = Σ ( Σ 1 − 1 μ 1 + Σ 2 − 1 μ 2 ) Σ = ( Σ 1 − 1 + Σ 2 − 1 ) − 1 \begin{aligned} \boldsymbol \mu & = \boldsymbol{\varSigma }\left( \boldsymbol{\varSigma }_{1}^{-1}\boldsymbol{\mu }_1+\boldsymbol{\varSigma }_{2}^{-1}\boldsymbol{\mu }_2 \right) \\ \boldsymbol \Sigma &= { \left (\boldsymbol \Sigma^{-1}_1 + \boldsymbol \Sigma^{-1}_2 \right )}^{-1} \end{aligned} μΣ=Σ(Σ1−1μ1+Σ2−1μ2)=(Σ1−1+Σ2−1)−1
3.3 高斯分布相加
两个高斯分布函数直接相加,很明显不是一个高斯函数。如果两个满足高斯分布的随机变量相加,那么他们的和还是一个高斯分布。具体的,如果 X ∼ N ( μ X , σ X 2 ) X\sim N(\mu _{X},\sigma _{X}^{2}) X∼N(μX,σX2), Y ∼ N ( μ Y , σ Y 2 ) Y\sim N(\mu _{Y},\sigma _{Y}^{2}) Y∼N(μY,σY2), Z = X + Y Z=X+Y Z=X+Y 那么 Z ∼ N ( μ X + μ Y , σ X 2 + σ Y 2 ) Z\sim N(\mu _{X}+\mu _{Y},\sigma _{X}^{2}+\sigma _{Y}^{2}) Z∼N(μX+μY,σX2+σY2)
需要用到卷积运算: ( f ∗ g ) ( n ) = ∫ − ∞ ∞ f ( τ ) g ( n − τ ) d τ \displaystyle (f*g)(n)=\int_{-\infty}^{\infty}f(\tau)g(n-\tau)d\tau (f∗g)(n)=∫−∞∞f(τ)g(n−τ)dτ
F
Z
(
z
)
=
P
(
Z
≤
z
)
=
P
(
X
+
Y
≤
z
)
=
∬
x
+
y
≤
z
f
(
x
,
y
)
d
x
d
y
=
∫
−
∞
∞
d
x
∫
−
∞
z
−
x
f
(
x
,
y
)
d
y
=
令u=y+x
∫
−
∞
∞
d
x
∫
−
∞
z
f
(
x
,
u
−
x
)
d
u
=
∫
−
∞
z
d
u
∫
−
∞
∞
f
(
x
,
u
−
x
)
d
x
\begin{aligned} F_{Z}(z) &=P(Z\leq z)=P(X+Y\leq z)\\ &=\iint_{x+y\leq z}f(x,y)dxdy\\ &=\int_{-\infty}^{\infty}dx\int_{-\infty}^{z-x}f(x,y)dy\\ &\overset{\text{令u=y+x}}{=}\int_{-\infty}^{\infty}dx\int_{-\infty}^{z}f(x,u-x)du\\ &=\int_{-\infty}^{z}du\int_{-\infty}^{\infty}f(x,u-x)dx\\ \end{aligned}
FZ(z)=P(Z≤z)=P(X+Y≤z)=∬x+y≤zf(x,y)dxdy=∫−∞∞dx∫−∞z−xf(x,y)dy=令u=y+x∫−∞∞dx∫−∞zf(x,u−x)du=∫−∞zdu∫−∞∞f(x,u−x)dx 所以,Z的概率密度函数为:
f
Z
(
z
)
=
∫
−
∞
∞
f
(
x
,
z
−
x
)
d
x
f_Z(z) = \int_{-\infty}^{\infty}f(x,z-x)dx
fZ(z)=∫−∞∞f(x,z−x)dx当
X
,
Y
X,Y
X,Y为独立随机变量时,
Z
Z
Z的概率密度为
f
Z
(
z
)
=
∫
−
∞
∞
f
Y
(
z
−
x
)
f
X
(
x
)
d
x
{\displaystyle f_{Z}(z)=\int _{-\infty }^{\infty }f_{Y}(z-x)f_{X}(x)\,dx}
fZ(z)=∫−∞∞fY(z−x)fX(x)dx
法二:使用特征函数证明
高斯分布的特征函数为:
φ
(
t
)
=
exp
(
i
t
μ
−
σ
2
t
2
2
)
\varphi (t)=\exp \left(it\mu -{\sigma ^{2}t^{2} \over 2}\right)
φ(t)=exp(itμ−2σ2t2)所以,
φ
X
+
Y
(
t
)
=
E
(
e
i
t
(
X
+
Y
)
)
=
φ
X
(
t
)
φ
Y
(
t
)
=
exp
(
i
t
μ
X
−
σ
X
2
t
2
2
)
exp
(
i
t
μ
Y
−
σ
Y
2
t
2
2
)
=
exp
(
i
t
(
μ
X
+
μ
Y
)
−
(
σ
X
2
+
σ
Y
2
)
t
2
2
)
.
{\displaystyle {\begin{aligned}\varphi _{X+Y}(t)=\operatorname {E} \left(e^{it(X+Y)}\right)= \varphi _{X}(t)\varphi _{Y}(t)&=\exp \left(it\mu _{X}-{\sigma _{X}^{2}t^{2} \over 2}\right)\exp \left(it\mu _{Y}-{\sigma _{Y}^{2}t^{2} \over 2}\right)\\[6pt]&=\exp \left(it(\mu _{X}+\mu _{Y})-{(\sigma _{X}^{2}+\sigma _{Y}^{2})t^{2} \over 2}\right).\end{aligned}}}
φX+Y(t)=E(eit(X+Y))=φX(t)φY(t)=exp(itμX−2σX2t2)exp(itμY−2σY2t2)=exp(it(μX+μY)−2(σX2+σY2)t2).
3.4 高斯线性模型
p ( x ) = N ( μ 0 , Σ 0 ) p ( y ∣ x ) = N ( A x + b , Σ y ) \begin{align*} p(x)=\mathcal{N}(\mathbf{\mu_0,\Sigma_0})\\ p(y\vert x)=\mathcal{N}(A\mathcal{x}+b,\Sigma_y) \end{align*} p(x)=N(μ0,Σ0)p(y∣x)=N(Ax+b,Σy)
4. 高斯分布性质
多元正态分布有4种等价的定义。
定义1–由标准正态随机向量线性组合得到
设 U = ( U 1 , U 2 , ⋯ , U q ) ′ U=\left(U_{1}, U_{2}, \cdots, U_{q}\right)^{\prime} U=(U1,U2,⋯,Uq)′ 为随机向量, U 1 , ⋯ , U q U_{1}, \cdots, U_{q} U1,⋯,Uq 独立服从标准正态。设 μ \mu μ 为 p p p 维常数向量, A A A 为 p × q p \times q p×q 维常数矩阵,则称 X = A U + μ X=A U+\mu X=AU+μ 的分布为 p p p 元正态分布,或称 X X X 为 p p p 维正态随机向量,记作 X ∼ N p ( μ , A A ′ ) X \sim N_{p}\left(\mu, A A^{\prime}\right) X∼Np(μ,AA′)
性质1–特征函数
在概率论中,任何随机变量的特征函数(ch.f)完全定义了它的概率分布。在实直线上,它由以下公式给出,其中X是任何具有该分布的随机变量: φ X ( t ) = E [ e i t X ] \varphi _ X(t) = E[e^{itX}] φX(t)=E[eitX]
φ X ( t ) = E [ e i t X ] = ⏞ 泰勒展开 E ( 1 + i t X 1 − t 2 X 2 2 ! + ⋯ + ( i t ) n X n n ! ) = E ( 1 ) + E ( i t X 1 ) − E ( t 2 X 2 2 ! ) + ⋯ + E ( ( i t ) n X n n ! ) = 1 + i t E [ X ] ⏞ 一阶矩 1 − t 2 E [ X 2 ] ⏞ 二阶矩 2 ! + ⋯ + ( i t ) n E [ X n ] ⏞ n阶矩 n ! ) \begin{aligned} \varphi_X(t) &= E[e^{itX}]\\ &\overbrace{=}^{\text{泰勒展开}} E(1 + \frac{it X}{1} - \frac{t^2 X^2}{2!} + \cdots + \frac{(it)^n X^n}{n!})\\ &= E(1) + E(\frac{it X}{1}) - E(\frac{t^2 X^2}{2!}) + \cdots + E(\frac{(it)^n X^n}{n!})\\ &= 1 + \frac{it \overbrace{E[X]}^{\text{一阶矩}}}{1} - \frac{t^2 \overbrace{E[X^2]}^{\text{二阶矩}}}{2!} + \cdots + \frac{(it)^n \overbrace{E[X^n]}^{\text{n阶矩}}}{n!}) \end{aligned} φX(t)=E[eitX]= 泰勒展开E(1+1itX−2!t2X2+⋯+n!(it)nXn)=E(1)+E(1itX)−E(2!t2X2)+⋯+E(n!(it)nXn)=1+1itE[X] 一阶矩−2!t2E[X2] 二阶矩+⋯+n!(it)nE[Xn] n阶矩)k k k阶原点矩: E [ X k ] 或 A k = 1 n ∑ i = 1 n X i k , k = 1 , 2 , ⋯ E[X^k] \ 或 \ A_k=\frac{1}{n}\sum_{i=1}^{n}X_i^k,\quad k=1,2,\cdots E[Xk] 或 Ak=n1∑i=1nXik,k=1,2,⋯
k k k阶中心矩: E [ ( X − E ( X ) ) k ] 或 A k = 1 n ∑ i = 1 n ( X i − X ˉ ) k , k = 2 , 3 , ⋯ E[(X-E(X))^k] \ 或 \ A_k=\frac{1}{n}\sum_{i=1}^{n}(X_i-\bar{X})^k,\quad k=2,3,\cdots E[(X−E(X))k] 或 Ak=n1∑i=1n(Xi−Xˉ)k,k=2,3,⋯可见特征函数包含了分布函数的所有矩(moment),也就是包含了分布函数的所有特征。
所以,特征函数其实是随机变量 X X X 的分布的另外一种描述方式。
假设某连续随机变量 X X X的概率密度函数为 f ( x ) f(x) f(x),那么可知: E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x E(X)=\int _{-\infty }^{+\infty }xf(x)dx E(X)=∫−∞+∞xf(x)dx,特征函数为:
φ X ( t ) = E [ e i t X ] = ∫ − ∞ + ∞ e i t x f ( x ) d x \begin{aligned} \varphi _ X(t) = E[e^{itX}] = \int _{-\infty }^{+\infty }e^{itx}f(x)dx \end{aligned} φX(t)=E[eitX]=∫−∞+∞eitxf(x)dx 特征函数把分布函数换到另外一个坐标系,也可以获得一些计算的好处:
- 假如我们不知道分布函数,但是通过实验算出了期望、方差、偏度、峰度等,那么可以用特征函数去代替分布函数
- 两个分布函数的卷积 f ∗ g f*g f∗g 通过特征函数更换坐标系后,可以变为更容易计算的乘法: φ ( f ∗ g ) = φ ( f ) φ ( g ) \varphi (f*g)=\varphi (f)\varphi (g) φ(f∗g)=φ(f)φ(g)
- 通过对 t t t 求导,可以简单求出各阶矩: φ X ( k ) ( 0 ) = i k E [ X k ] \varphi _{X}^{(k)}(0)=i^{k}E[X^{k}] φX(k)(0)=ikE[Xk]
由定义1得到的随机向量
X
X
X 的特征函数为
Φ
X
(
t
)
=
exp
[
i
t
′
μ
−
1
2
t
′
A
A
′
t
]
\Phi_{X}(t)=\exp \left[i t^{\prime} \mu-\frac{1}{2} t^{\prime} A A^{\prime} t\right]
ΦX(t)=exp[it′μ−21t′AA′t]其中
t
=
(
t
1
,
⋯
,
t
p
)
′
∈
R
p
t=\left(t_{1}, \cdots, t_{p}\right)^{\prime} \in \mathbb{R}^{p}
t=(t1,⋯,tp)′∈Rp
证明:首先考虑一维标准正态分布的特征函数为
Φ
U
i
(
t
i
)
=
exp
[
−
1
2
t
i
2
]
\Phi_{U_{i}}\left(t_{i}\right)=\exp \left[-\frac{1}{2} t_{i}^{2}\right]
ΦUi(ti)=exp[−21ti2]
根据独立性有
Φ
U
(
t
)
=
exp
[
−
1
2
∑
i
=
1
q
t
i
2
]
=
exp
[
−
1
2
t
′
t
]
\Phi_{U}(t)=\exp \left[-\frac{1}{2} \sum_{i=1}^{q} t_{i}^{2}\right]=\exp \left[-\frac{1}{2} t^{\prime} t\right]
ΦU(t)=exp[−21i=1∑qti2]=exp[−21t′t]进而根据 X 的定义得到
Φ
X
(
t
)
=
E
[
exp
{
i
t
′
X
}
]
=
E
[
exp
{
i
t
′
(
A
U
+
μ
)
}
]
=
E
[
exp
{
i
t
′
μ
}
]
E
[
exp
{
i
t
′
A
U
}
]
=
E
[
exp
{
i
t
′
μ
}
]
E
[
exp
{
i
(
A
′
t
)
′
U
}
]
\begin{aligned} \Phi_{X}(t) &=E[\exp\left\{i t^{\prime} X\right\}]=E[\exp \left\{i t^{\prime}(A U+\mu)\right\}] \\ &=E[\exp \left\{i t^{\prime} \mu\right\}] E[\exp \left\{i t^{\prime} A U\right\}]=E[\exp \left\{i t^{\prime} \mu\right\}]E [\exp \left\{i\left(A^{\prime} t\right)^{\prime} U\right\}] \end{aligned}
ΦX(t)=E[exp{it′X}]=E[exp{it′(AU+μ)}]=E[exp{it′μ}]E[exp{it′AU}]=E[exp{it′μ}]E[exp{i(A′t)′U}]其中
E
[
exp
{
i
(
A
′
t
)
′
U
}
]
E[\exp \left\{i\left(A^{\prime} t\right)^{\prime} U\right\}]
E[exp{i(A′t)′U}] 即
Φ
U
(
A
′
t
)
\Phi_{U}(A^{\prime}t)
ΦU(A′t) ,代入即得结论.
定义2–由特征函数定义
如果随机向量 X 的特征函数具有如下形式 Φ X ( t ) = exp [ i t ′ μ − 1 2 t ′ Σ t ] \Phi_{X}(t)=\exp \left[i t^{\prime} \mu-\frac{1}{2} t^{\prime} \Sigma t\right] ΦX(t)=exp[it′μ−21t′Σt], 则称 X X X 服从 p p p 维正态分布,记作 X ∼ N p ( μ , Σ ) X \sim N_{p}(\mu, \Sigma) X∼Np(μ,Σ)
性质2–正态随机向量任意线性变换仍服从正态分布
设 X ∼ N p ( μ , Σ ) X \sim N_{p}(\mu, \Sigma) X∼Np(μ,Σ),令 Z = B X + d Z=B X+d Z=BX+d ,则 Z ∼ N s ( B μ + d , B Σ B ′ ) Z \sim N_{s}\left(B \mu+d, B \Sigma B^{\prime}\right) Z∼Ns(Bμ+d,BΣB′) ,其中 B B B 为 s × q s \times q s×q 维矩阵, d d d 为 s s s 维向量.
推论–子向量的均值与协方差:
设
X
=
[
X
(
1
)
X
(
2
)
]
r
p
−
r
∼
N
p
(
μ
,
Σ
)
X=\left[\begin{array}{c} X^{(1)} \\ X^{(2)} \end{array}\right] \quad \begin{array}{c} r \\ p-r \end{array} \sim N_{p}(\mu, \Sigma)
X=[X(1)X(2)]rp−r∼Np(μ,Σ) ,将
μ
\mu
μ,
Σ
\Sigma
Σ 分为
μ
=
[
μ
(
1
)
μ
(
2
)
]
r
p
−
r
,
Σ
=
[
Σ
11
Σ
12
Σ
21
Σ
22
]
r
p
−
r
\mu=\left[\begin{array}{c} \mu^{(1)} \\ \mu^{(2)} \end{array}\right] \begin{array}{c} r \\ p-r \end{array}, \Sigma=\left[\begin{array}{cc} \Sigma_{11} & \Sigma_{12} \\ \Sigma_{21} & \Sigma_{22} \end{array}\right] \begin{array}{c} r \\ p-r \end{array}
μ=[μ(1)μ(2)]rp−r,Σ=[Σ11Σ21Σ12Σ22]rp−r 则有
X
(
1
)
∼
N
r
(
μ
(
1
)
,
Σ
11
)
,
X
(
2
)
∼
N
p
−
r
(
μ
(
2
)
,
Σ
22
)
X^{(1)} \sim N_{r}\left(\mu^{(1)}, \Sigma_{11}\right), X^{(2)} \sim N_{p-r}\left(\mu^{(2)}, \Sigma_{22}\right)
X(1)∼Nr(μ(1),Σ11),X(2)∼Np−r(μ(2),Σ22)
注意:
Σ
12
≠
Σ
21
\Sigma_{12} \neq \Sigma_{21}
Σ12=Σ21 ,两者互为转置
性质3–多元正态 ⇔ \Leftrightarrow ⇔ 任意线性组合为一元正态
设
X
=
(
X
1
,
X
2
,
⋯
,
X
p
)
′
X=\left(X_{1}, X_{2}, \cdots, X_{p}\right)^{\prime}
X=(X1,X2,⋯,Xp)′ 为
p
p
p 维随机向量,则
X
X
X 服从
p
p
p 元正态分布等价于对任意
p
p
p 维实向量,
ξ
=
a
′
X
\xi=a^{\prime} X
ξ=a′X 是一维正态随机变量.
证明:
当 X 为 p 元正态分布,由性质2知
ξ
\xi
ξ 为一维正态随机变量。
反之,如果对任意
a
a
a 有
ξ
=
a
′
X
\xi=a^{\prime} X
ξ=a′X 为一维正态随机变量,则
ξ
\xi
ξ 各阶矩存在,进而
X
X
X 的均值和协方差存在,分别设为
μ
,
Σ
\mu,\Sigma
μ,Σ ,则
ξ
=
a
′
X
∼
N
(
a
′
μ
,
a
′
Σ
a
)
\xi=a^{\prime} X \sim N\left(a^{\prime} \mu, a^{\prime} \Sigma a\right)
ξ=a′X∼N(a′μ,a′Σa) 进而考察 X 的特征函数得到
Φ
X
(
a
)
=
exp
[
i
a
′
X
]
=
exp
[
i
ξ
]
=
Φ
ξ
(
1
)
=
exp
[
i
a
′
μ
−
1
2
a
′
Σ
a
]
\Phi_{X}(a)=\exp \left[i a^{\prime} X\right]=\exp [i \xi]=\Phi_{\xi}(1)=\exp \left[\mathrm{i} a^{\prime} \mu-\frac{1}{2} a^{\prime} \Sigma a\right]
ΦX(a)=exp[ia′X]=exp[iξ]=Φξ(1)=exp[ia′μ−21a′Σa] 刚好等于多元正态的特征函数,由特征函数与分布的一一对应得到结论.
定义3–任意线性组合为正态
如果 p p p 维随机向量 X X X 的任意线性组合均服从一元正态分布,则称 X X X 为 p p p 维正态随机向量.
性质4–联合密度函数
如果
X
∼
N
p
(
μ
,
Σ
)
X \sim N_{p}(\mu, \Sigma)
X∼Np(μ,Σ) 且
Σ
>
0
\Sigma>0
Σ>0 ,则
X
X
X 的联合密度函数为
f
(
x
)
=
1
(
2
π
)
p
/
2
∣
Σ
∣
1
/
2
exp
[
−
1
2
(
x
−
μ
)
′
Σ
−
1
(
x
−
μ
)
]
f(x)=\frac{1}{(2 \pi)^{p / 2}|\Sigma|^{1 / 2}} \exp \left[-\frac{1}{2}(x-\mu)^{\prime} \Sigma^{-1}(x-\mu)\right]
f(x)=(2π)p/2∣Σ∣1/21exp[−21(x−μ)′Σ−1(x−μ)]
定义4–密度函数
如果
p
p
p 维随机向量
X
X
X 的联合密度函数为
f
(
x
)
=
1
(
2
π
)
p
/
2
∣
Σ
∣
1
/
2
exp
[
−
1
2
(
x
−
μ
)
′
Σ
−
1
(
x
−
μ
)
]
f(x)=\frac{1}{(2 \pi)^{p / 2}|\Sigma|^{1 / 2}} \exp \left[-\frac{1}{2}(x-\mu)^{\prime} \Sigma^{-1}(x-\mu)\right]
f(x)=(2π)p/2∣Σ∣1/21exp[−21(x−μ)′Σ−1(x−μ)] 则称
X
X
X 为
p
p
p 维正态随机向量.
注意:定义4要求
Σ
>
0
\Sigma>0
Σ>0 ,其他三个只要求
Σ
≥
0
\Sigma \geq0
Σ≥0 ,一般也不考虑
X
X
X 为退化随机向量的情况.
4. 高斯条件分布和独立性
仅讨论 Σ ≥ 0 \Sigma \geq0 Σ≥0 (即半正定) 的情形
定理1–正态随机向量的独立性等价于协方差为0矩阵
定理2–条件分布
设
X
=
[
X
(
1
)
X
(
2
)
]
r
p
−
r
∼
N
p
(
μ
,
Σ
)
(
Σ
>
0
)
X=\left[\begin{array}{c}X^{(1)} \\ X^{(2)}\end{array}\right] \begin{array}{c}r \\ p-r\end{array} \sim N_{p}(\mu, \Sigma)(\Sigma>0)
X=[X(1)X(2)]rp−r∼Np(μ,Σ)(Σ>0) ,则当
X
(
2
)
=
x
(
2
)
X^{(2)}=x^{(2)}
X(2)=x(2) 给定时,
X
(
1
)
X^{(1)}
X(1) 的条件分布为
(
X
(
1
)
∣
X
(
2
)
=
x
(
2
)
)
∼
N
r
(
μ
1
⋅
2
,
Σ
11
⋅
2
)
\left(X^{(1)} \mid X^{(2)}=x^{(2)}\right) \sim N_{r}\left(\mu_{1 \cdot 2}, \Sigma_{11 \cdot 2}\right)
(X(1)∣X(2)=x(2))∼Nr(μ1⋅2,Σ11⋅2)其中
μ
1
⋅
2
=
μ
(
1
)
+
Σ
12
Σ
22
−
1
(
x
(
2
)
−
μ
(
2
)
)
Σ
11
⋅
2
=
Σ
11
−
Σ
12
Σ
22
−
1
Σ
21
\begin{aligned} \mu_{1 \cdot 2} &=\mu^{(1)}+\Sigma_{12} \Sigma_{22}^{-1}\left(x^{(2)}-\mu^{(2)}\right) \\ \Sigma_{11 \cdot 2} &=\Sigma_{11}-\Sigma_{12} \Sigma_{22}^{-1} \Sigma_{21} \end{aligned}
μ1⋅2Σ11⋅2=μ(1)+Σ12Σ22−1(x(2)−μ(2))=Σ11−Σ12Σ22−1Σ21
证明:从回归的角度会比较容易理解,理论依据是,在均方意义下,线性回归的结果就是条件期望。将 X 中心化后做回归
X
(
1
)
−
μ
(
1
)
=
β
′
(
X
(
2
)
−
μ
(
2
)
)
+
ε
X^{(1)}-\mu^{(1)}=\beta^{\prime}\left(X^{(2)}-\mu^{(2)}\right)+\varepsilon
X(1)−μ(1)=β′(X(2)−μ(2))+ε
那么
β
′
(
x
(
2
)
−
μ
(
2
)
)
\beta^{\prime}\left(x^{(2)}-\mu^{(2)}\right)
β′(x(2)−μ(2)) 就是
X
(
1
)
−
μ
(
1
)
X^{(1)}-\mu^{(1)}
X(1)−μ(1) 的条件期望。现在假设对于每个变量,都有
n
n
n 个观测数据,并将回归形式改写为
Z
t
=
β
′
R
t
+
ε
Z_t=\beta^{\prime}R_t+\varepsilon
Zt=β′Rt+ε ,那么利用最小二乘估计可以得到参数的估计量为
β
=
(
R
′
R
)
−
1
R
′
Z
\beta=\left(R^{\prime} R\right)^{-1} R^{\prime} Z
β=(R′R)−1R′Z 。考虑当
n
n
n 充分大的情况下,
(
R
′
R
)
−
1
\left(R^{\prime} R\right)^{-1}
(R′R)−1 对应了
Σ
22
−
1
,
R
′
Z
\Sigma_{22}^{-1} , R^{\prime} Z
Σ22−1,R′Z 对应了
Σ
21
\Sigma_{21}
Σ21 进而对
β
\beta
β 求转置后得到
X
(
1
)
=
μ
(
1
)
+
Σ
12
Σ
22
−
1
(
X
(
2
)
−
μ
(
2
)
)
+
ε
X^{(1)}=\mu^{(1)}+\Sigma_{12}\Sigma_{22}^{-1}\left(X^{(2)}-\mu^{(2)}\right)+\varepsilon
X(1)=μ(1)+Σ12Σ22−1(X(2)−μ(2))+ε
因此条件期望就是 μ 1 ⋅ 2 = μ ( 1 ) + Σ 12 Σ 22 − 1 ( x ( 2 ) − μ ( 2 ) ) \mu_{1 \cdot 2}=\mu^{(1)}+\Sigma_{12}\Sigma_{22}^{-1} \left(x^{(2)}-\mu^{(2)}\right) μ1⋅2=μ(1)+Σ12Σ22−1(x(2)−μ(2))
下面考虑条件方差的计算。做回归后得到的误差项
ε
\varepsilon
ε 是从
X
(
1
)
X^{(1)}
X(1) 中剔除了
X
(
2
)
X^{(2)}
X(2) 对其的影响,那么条件方差就应该等于误差项的方差,即
Σ
11.2
=
Var
ε
=
Var
(
X
(
1
)
−
μ
(
1
)
)
−
Var
[
Σ
12
Σ
22
−
1
(
X
(
2
)
−
μ
(
2
)
)
]
=
Σ
11
−
Σ
12
Σ
22
−
1
Σ
22
(
Σ
12
Σ
22
−
1
)
′
=
Σ
11
−
Σ
12
Σ
22
−
1
Σ
21
\begin{aligned} \Sigma_{11.2} &=\operatorname{Var} \varepsilon=\operatorname{Var}\left(X^{(1)}-\mu^{(1)}\right)-\operatorname{Var}\left[\Sigma_{12} \Sigma_{22}^{-1}\left(X^{(2)}-\mu^{(2)}\right)\right] \\ &=\Sigma_{11}-\Sigma_{12} \Sigma_{22}^{-1} \Sigma_{22}\left(\Sigma_{12}\Sigma_{22}^{-1}\right)^{\prime}=\Sigma_{11}-\Sigma_{12} \Sigma_{22}^{-1} \Sigma_{21} \end{aligned}
Σ11.2=Varε=Var(X(1)−μ(1))−Var[Σ12Σ22−1(X(2)−μ(2))]=Σ11−Σ12Σ22−1Σ22(Σ12Σ22−1)′=Σ11−Σ12Σ22−1Σ21
由此可以自然地得到下面的推论:
X
(
2
)
与
X
(
1
)
−
Σ
12
Σ
22
−
1
X
(
2
)
X^{(2)} 与 X^{(1)}-\Sigma_{12} \Sigma_{22}^{-1} X^{(2)}
X(2)与X(1)−Σ12Σ22−1X(2) 相互独立
X
(
1
)
与
X
(
2
)
−
Σ
21
Σ
11
−
1
X
(
1
)
X^{(1)} 与 X^{(2)}-\Sigma_{21} \Sigma_{11}^{-1} X^{(1)}
X(1)与X(2)−Σ21Σ11−1X(1) 相互独立
X
(
2
)
∣
X
(
1
)
∼
N
p
−
r
(
μ
2
⋅
1
,
Σ
22
⋅
1
)
X^{(2)} \mid X^{(1)} \sim N_{p-r}\left(\mu_{2 \cdot 1}, \Sigma_{22 \cdot 1}\right)
X(2)∣X(1)∼Np−r(μ2⋅1,Σ22⋅1), 其中
μ
2
⋅
1
=
μ
(
2
)
+
Σ
21
Σ
11
−
1
(
x
(
1
)
−
μ
(
1
)
)
Σ
22
⋅
1
=
Σ
22
−
Σ
21
Σ
11
−
1
Σ
12
\begin{array}{c} \mu_{2 \cdot 1}=\mu^{(2)}+\Sigma_{21} \Sigma_{11}^{-1}\left(x^{(1)}-\mu^{(1)}\right) \\ \Sigma_{22 \cdot 1}=\Sigma_{22}-\Sigma_{21} \Sigma_{11}^{-1} \Sigma_{12} \end{array}
μ2⋅1=μ(2)+Σ21Σ11−1(x(1)−μ(1))Σ22⋅1=Σ22−Σ21Σ11−1Σ12
问:如果是三个子向量,给定其中两个,求另一个的条件分布呢?
答:把给定的两个看做一个子向量就可以。
条件数字特征
就是刚刚推导的东西的定义
(1)条件期望,回归系数,偏相关系数
设
X
=
[
X
(
1
)
X
(
2
)
]
∼
N
p
(
[
μ
(
1
)
μ
(
2
)
]
,
[
Σ
11
Σ
12
Σ
21
Σ
22
]
)
X=\left[\begin{array}{c} X^{(1)} \\ X^{(2)} \end{array}\right] \sim N_{p}\left(\left[\begin{array}{c} \mu^{(1)} \\ \mu^{(2)} \end{array}\right],\left[\begin{array}{cc} \Sigma_{11} & \Sigma_{12} \\ \Sigma_{21} & \Sigma_{22} \end{array}\right]\right)
X=[X(1)X(2)]∼Np([μ(1)μ(2)],[Σ11Σ21Σ12Σ22])
根据定理2有
(
X
(
1
)
∣
X
(
2
)
=
x
(
2
)
)
∼
N
r
(
μ
1
⋅
2
,
Σ
11
⋅
2
)
\left(X^{(1)} \mid X^{(2)}=x^{(2)}\right) \sim N_{r}\left(\mu_{1 \cdot 2}, \Sigma_{11 \cdot 2}\right)
(X(1)∣X(2)=x(2))∼Nr(μ1⋅2,Σ11⋅2),我们把
μ
1
⋅
2
=
μ
(
1
)
+
Σ
12
Σ
22
−
1
(
x
(
2
)
−
μ
(
2
)
)
\mu_{1 \cdot 2}=\mu^{(1)}+\Sigma_{12} \Sigma_{22}^{-1}\left(x^{(2)}-\mu^{(2)}\right)
μ1⋅2=μ(1)+Σ12Σ22−1(x(2)−μ(2))
称为条件期望,记作 E ( X ( 1 ) ∣ X ( 2 ) = x ( 2 ) ) \mathrm{E}\left(X^{(1)} \mid X^{(2)}=x^{(2)}\right) E(X(1)∣X(2)=x(2)) ;把 Σ 12 Σ 22 − 1 = def B \Sigma_{12} \Sigma_{22}^{-1} \stackrel{\text {def}}{=} B Σ12Σ22−1=defB 称为回归系数.
为了定义偏回归系数,将条件方差矩阵的元素具体表示为
Σ
11
⋅
2
=
(
σ
i
j
)
r
×
r
(
i
,
j
=
1
,
⋯
,
r
)
\Sigma_{11 \cdot 2}=\left(\sigma_{i j }\right)_{r \times r}(i, j=1, \cdots, r)
Σ11⋅2=(σij)r×r(i,j=1,⋯,r)
称 ρ i j ⋅ r + 1 , ⋯ , p = σ i j σ i i σ j j \rho_{i j \cdot r+1, \cdots, p}=\frac{\sigma_{i j }}{\sqrt{\sigma_{i i }} \sqrt{\sigma_{j j }}} ρij⋅r+1,⋯,p=σiiσjjσij 为偏相关系数,即为 X ( 2 ) = ( X r + 1 , ⋯ , X p ) ′ X^{(2)}=\left(X_{r+1}, \cdots, X_{p}\right)^{\prime} X(2)=(Xr+1,⋯,Xp)′ 给定的条件下, X i , X j X_{i},X_{j} Xi,Xj 的相关系数.
(2)全相关系数(了解)
设
Z
=
[
X
Y
]
p
1
∼
N
p
+
1
(
[
μ
X
μ
y
]
,
[
Σ
X
X
Σ
X
y
Σ
y
X
σ
y
y
]
)
Z=\left[\begin{array}{l} X \\ Y \end{array}\right] \begin{array}{l} p \\ 1 \end{array} \sim N_{p+1}\left(\left[\begin{array}{c} \mu_{X} \\ \mu_{y} \end{array}\right],\left[\begin{array}{cc} \Sigma_{X X} & \Sigma_{X y} \\ \Sigma_{y X} & \sigma_{y y} \end{array}\right]\right)
Z=[XY]p1∼Np+1([μXμy],[ΣXXΣyXΣXyσyy]),则称
R
=
(
∑
y
X
Σ
X
X
−
1
Σ
X
y
σ
y
y
)
1
/
2
R=\left(\frac{\sum_{y X} \Sigma_{X X}^{-1} \Sigma_{X y}}{\sigma_{y y}}\right)^{1 / 2}
R=(σyy∑yXΣXX−1ΣXy)1/2
为 Y Y Y 与 X = ( X 1 , ⋯ , X p ) ′ X=\left(X_{1}, \cdots, X_{p}\right)^{\prime} X=(X1,⋯,Xp)′ 的全相关系数.
(3)最佳预测
记
X
(
1
)
=
Y
,
g
(
x
(
2
)
)
=
E
(
Y
∣
X
(
2
)
=
x
(
2
)
)
X^{(1)}=Y, g\left(x^{(2)}\right)=E\left(Y \mid X^{(2)}=x^{(2)}\right)
X(1)=Y,g(x(2))=E(Y∣X(2)=x(2)) ,则对任意函数
ϕ
(
⋅
)
\phi(\cdot)
ϕ(⋅) ,可以证明
E
[
(
Y
−
g
(
x
(
2
)
)
)
2
]
≤
E
[
(
Y
−
ϕ
(
x
(
2
)
)
)
2
]
E\left[\left(Y-g\left(x^{(2)}\right)\right)^{2}\right] \leq E\left[\left(Y-\phi\left(x^{(2)}\right)\right)^{2}\right]
E[(Y−g(x(2)))2]≤E[(Y−ϕ(x(2)))2]
也就是在均方准则下,条件期望是最优预测,证明方法就是加一项减一项,往证交叉项为0.
5. 高斯过程
高斯过程(Gaussian process, GP) 是一个概率统计学上的概念,更确切的说应该是随机过程(Stochastic process)中一个特殊例子。
在高斯过程中,连续输入空间中每个点都是与一个正态分布的随机变量相关联。此外,这些随机变量的每个有限集合都有一个多元正态分布。高斯过程的分布是所有那些(无限多个)随机变量的联合分布,正因如此,它是连续域(例如时间或空间)的分布。
GP可以被mean和covariance function共同唯一决定其表达式。因为我们知道一个高斯分布可以被mean和variance共同唯一决定,一个多元高斯分布可以对mean vector和covariance matrix共同唯一决定。covariance function被称为核函数kernel,原因就是它捕捉了不同输入点之间的关系,并且反映在了之后样本的位置上。这样的话,就可以做到,利用点与点之间关系,以从输入的训练数据预测未知点的值。
References
多元高斯分布完全解析 -知乎
高斯分布相乘、积分整理
多维高斯分布 -博客园
多维正态分布的最大似然估计 -博客园
高斯性质:多元统计分析第01讲–多元正态分布及参数估计(随机向量,多元正态分布定义,条件分布和独立性)-知乎
高斯条件分布:多元统计分析第02讲(条件分布,随机阵的正态分布,参数估计)
高斯过程通俗理解: 什么是Gaussian process? —— 说说高斯过程与高斯分布的关系
从贝叶斯的角度理解高斯过程回归 -知乎
Sum of normally distributed random variables
第三章·随机向量 ----概率论与数理统计
汇总型:
prml -gitbook



![[SQL开发笔记]SELECT 语句:读取数据表的信息](https://img-blog.csdnimg.cn/ad4002024ccb464cb599450024c23078.png)