网页链接:
https://www.ptpress.com.cn/shopping/search?tag=search&orderstr=hot&leve11-75424c57-6dd7-4d1f-b6b9-8e95773c0593
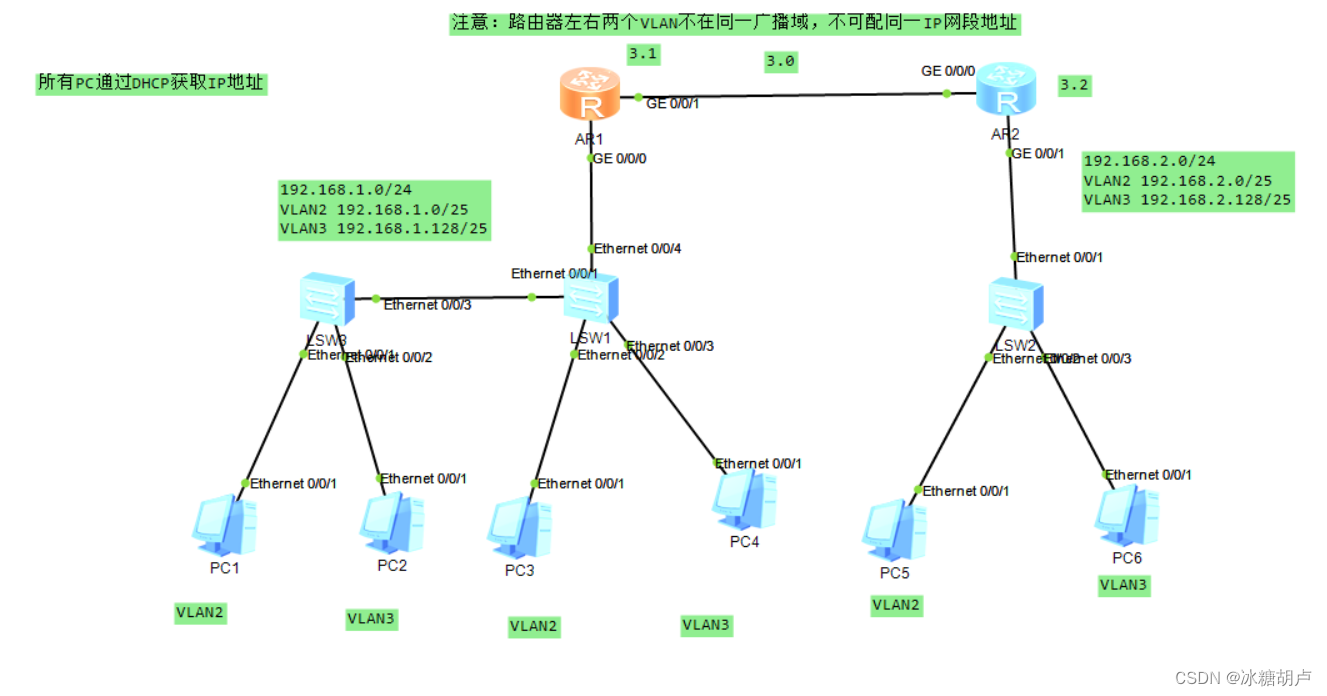
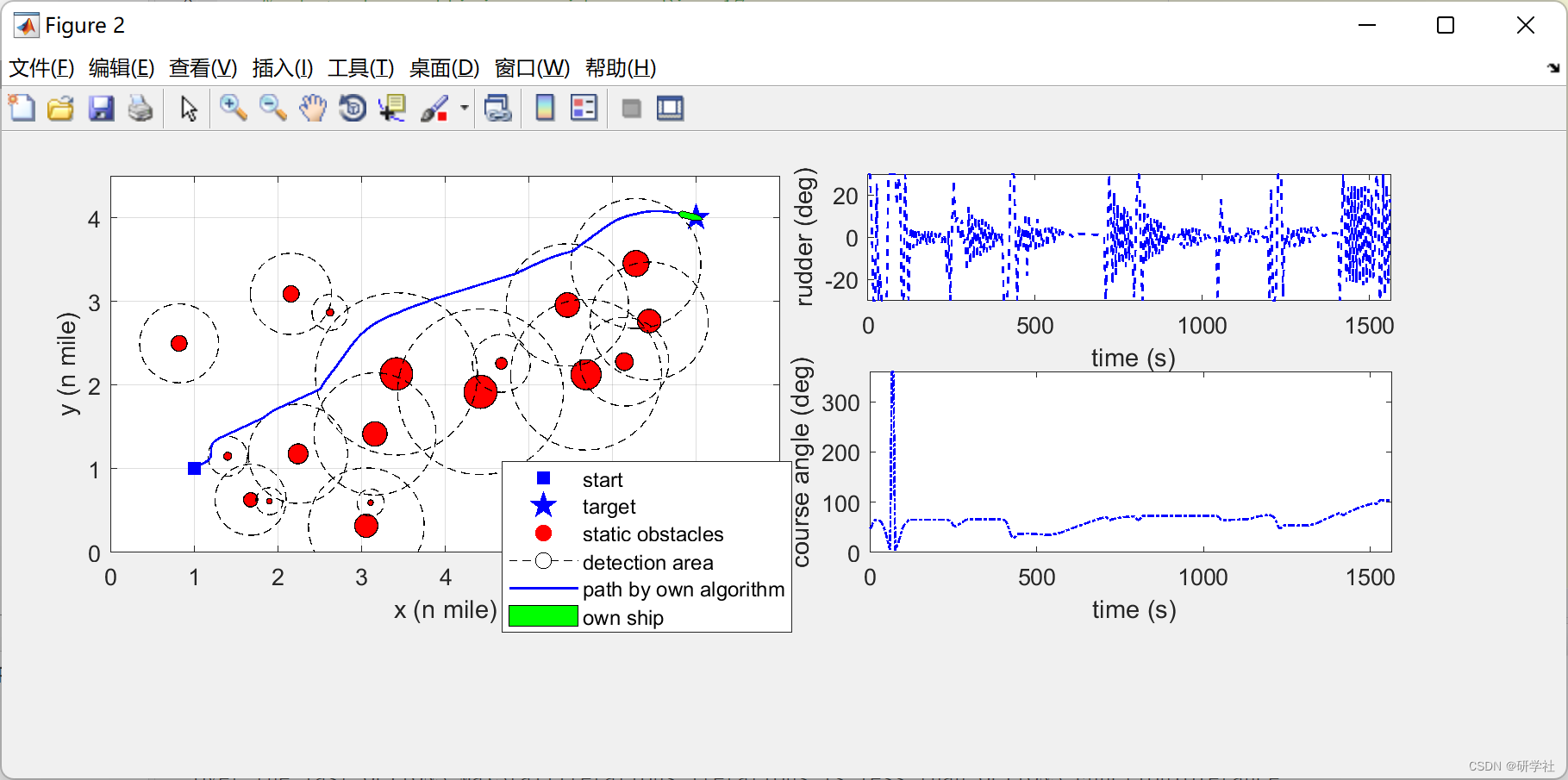
一、为了完成爬取数据,需要进行以下步骤
1.在浏览器中打开页面,选择"计算机"
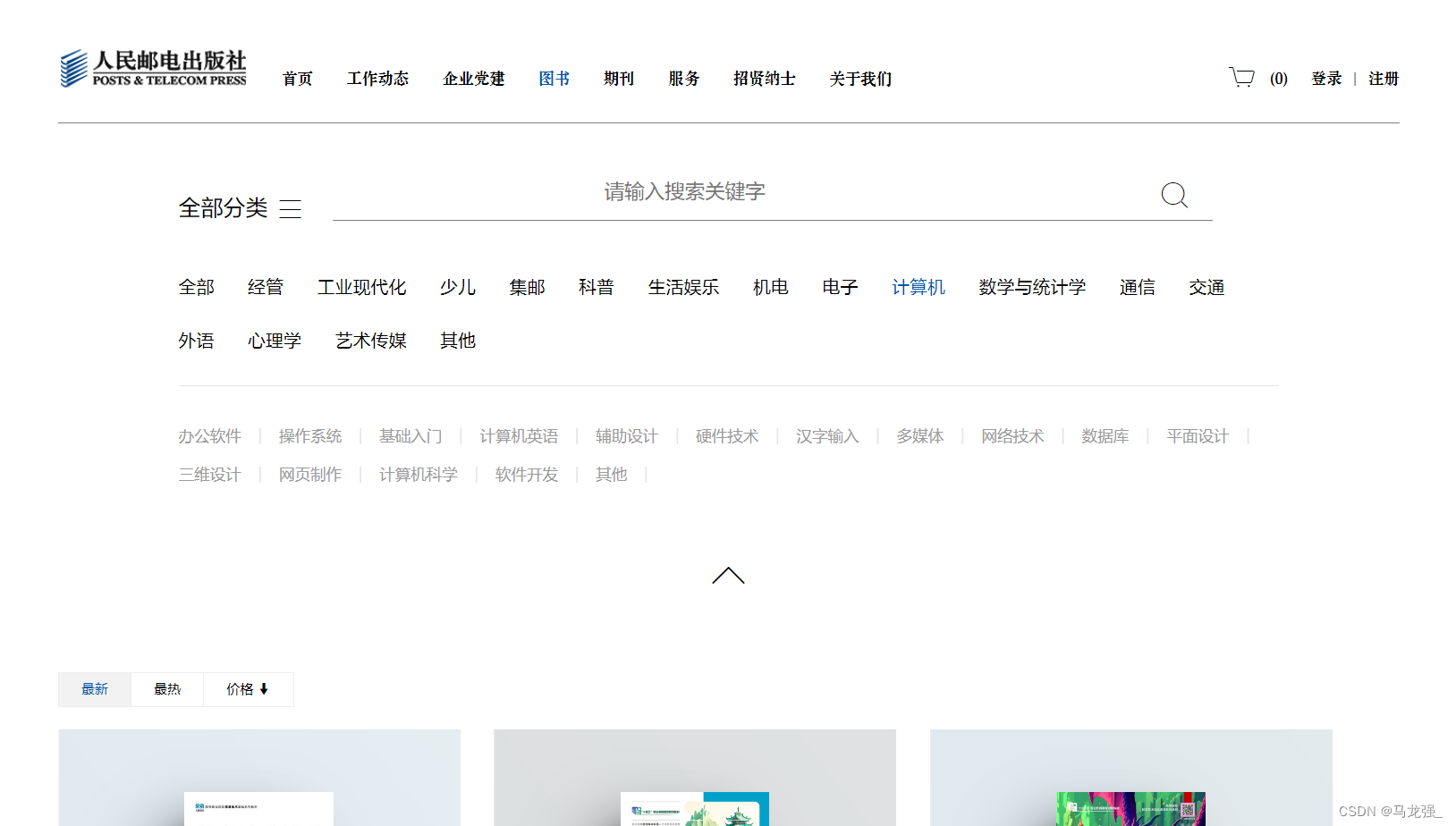
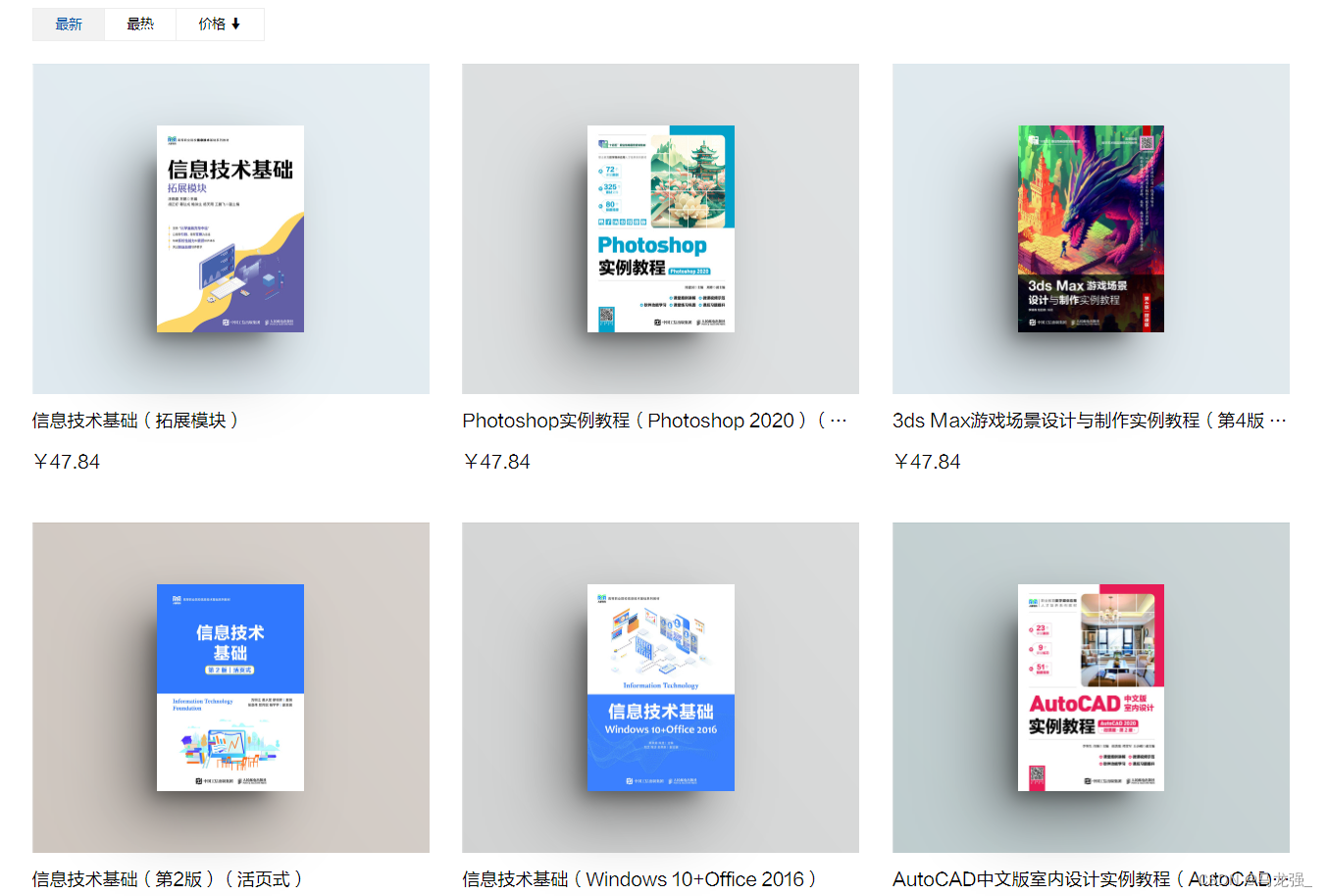
2.可以看到大量的"计算机"相关书籍,右键点击"检查"
3.刷新页面,点击下一页,查看url
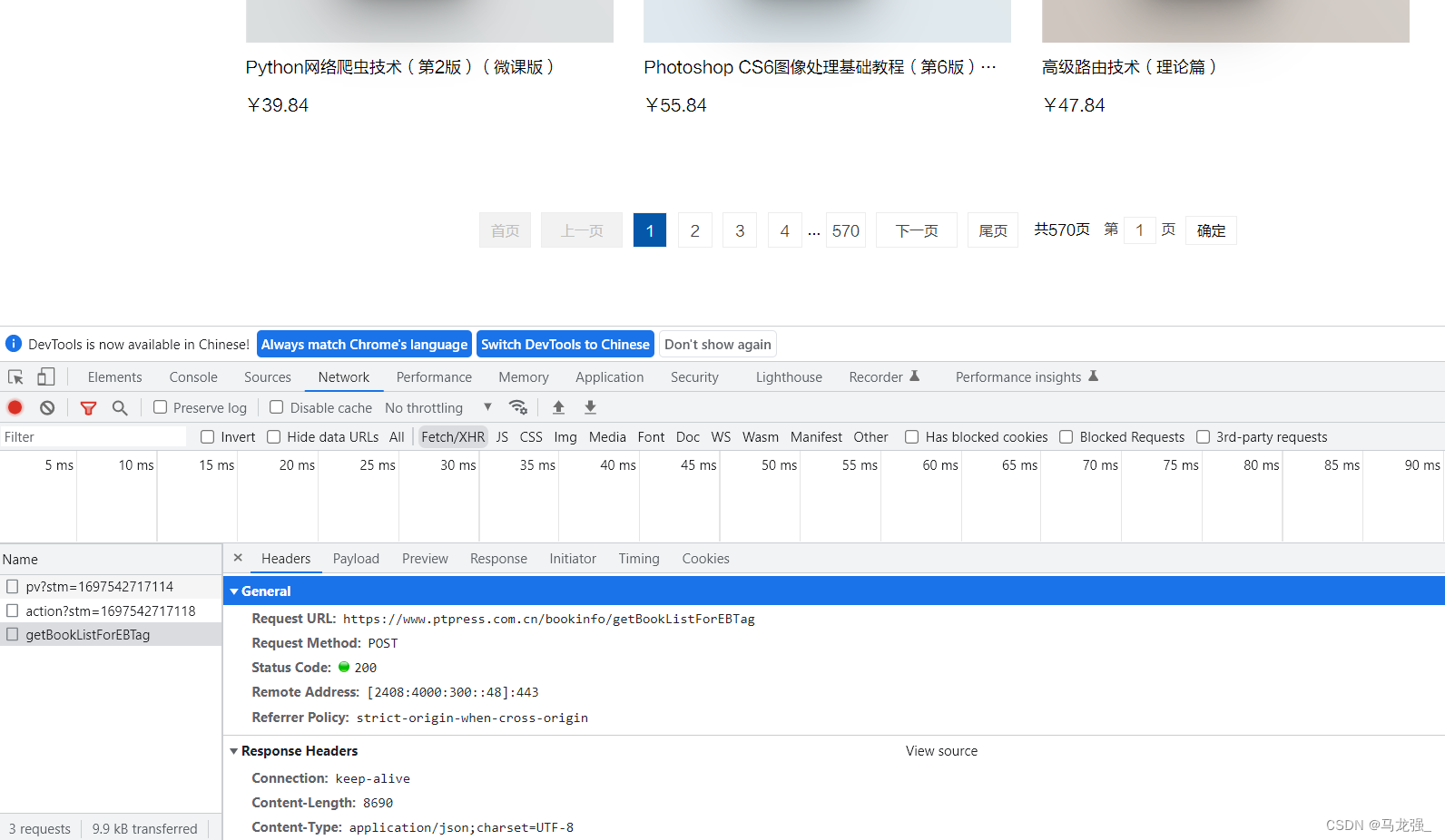
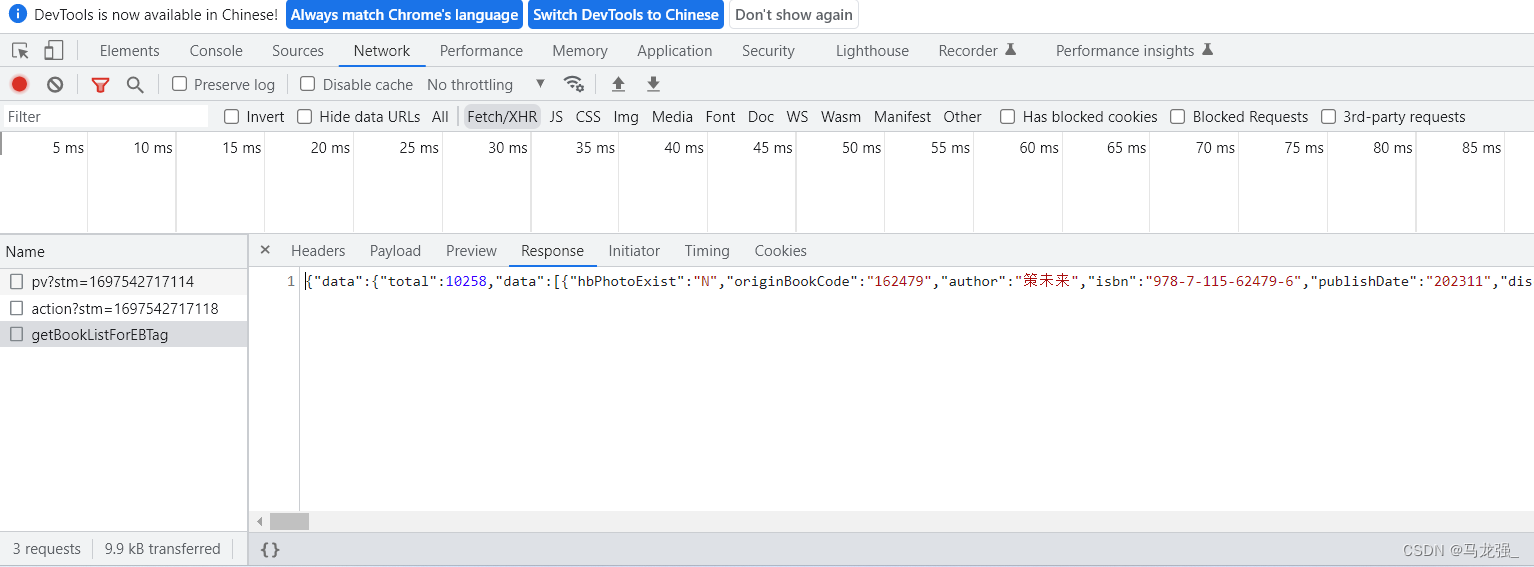
4.点击"Response",查看json格式中的信息,发现与要爬取的书籍信息一致
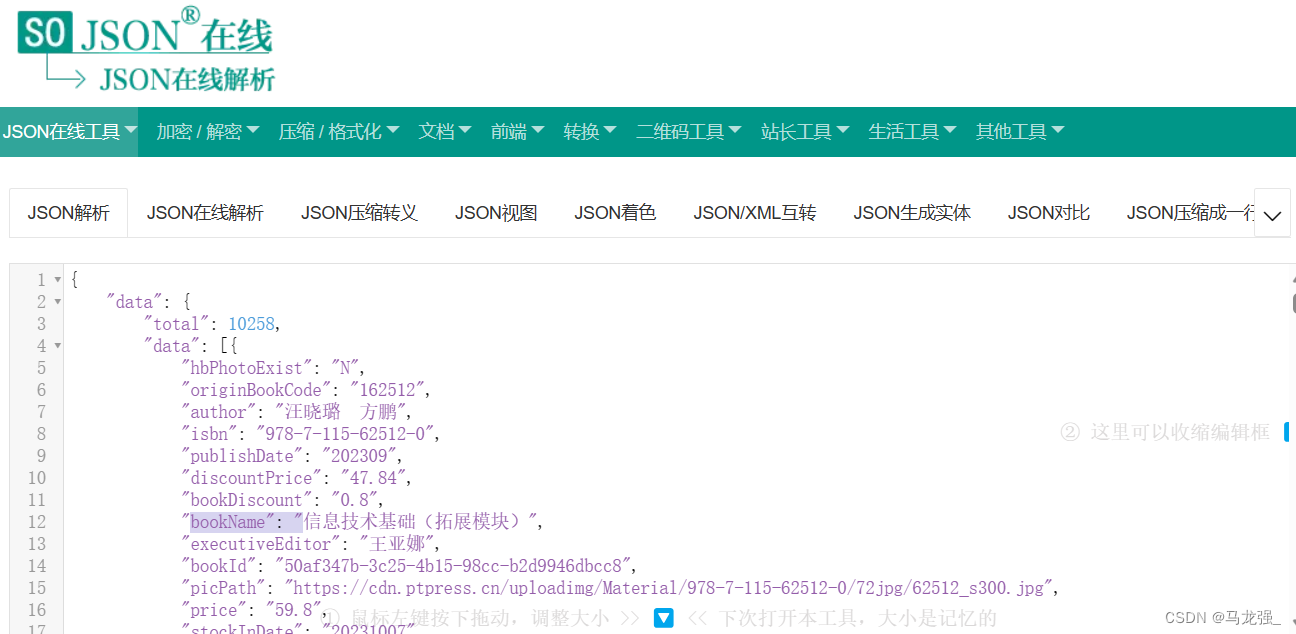
5.划到最低端可以发现计算机类图书查看页数(570页)

6.查看Date格式
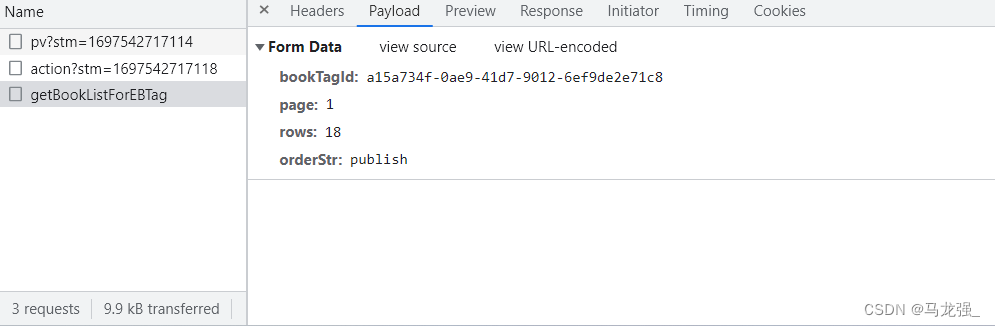
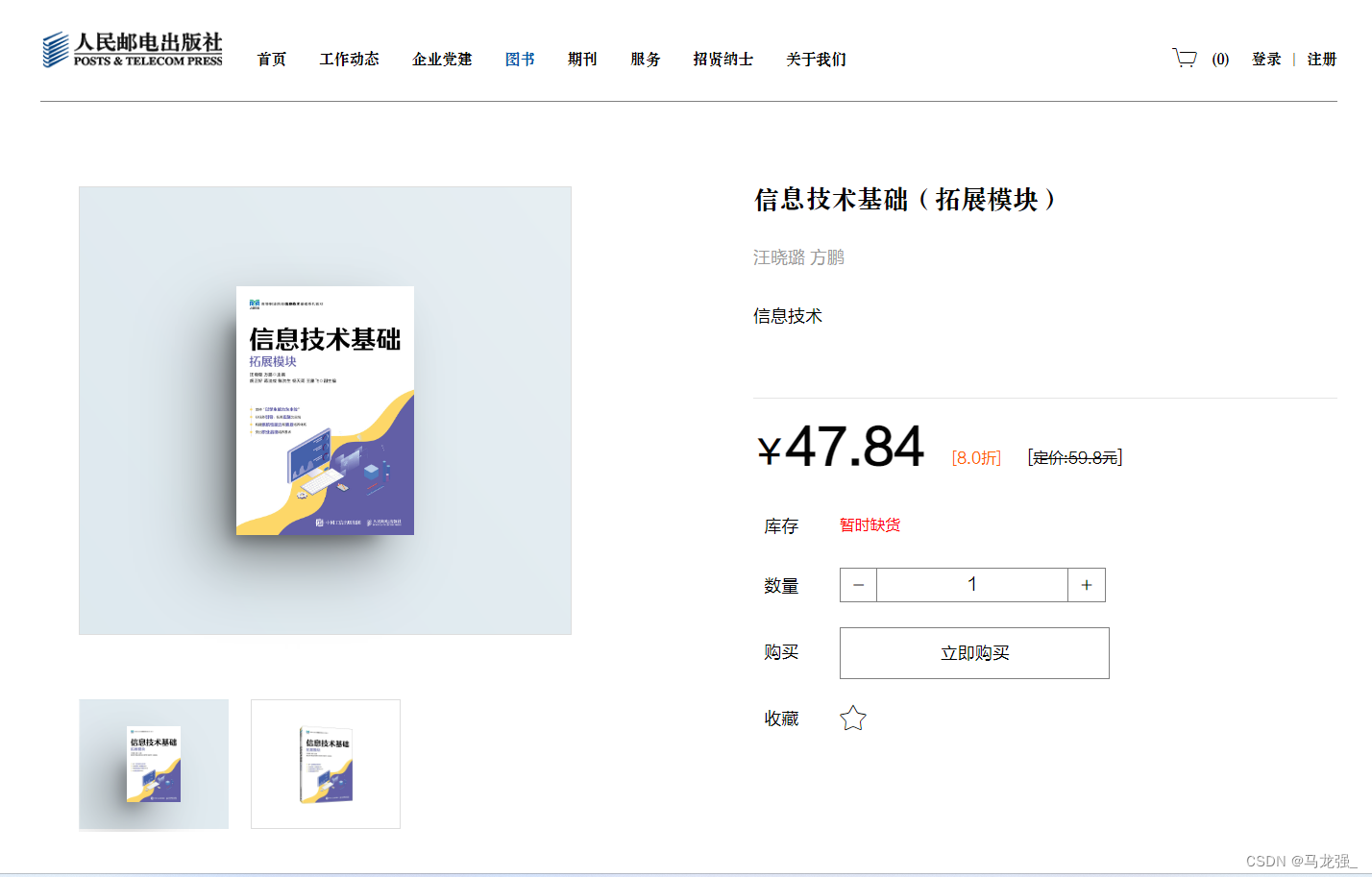
7.根据书籍详情来爬取相关信息
二、代码部分
1.将爬取内容放入打印并放入excel表格中
import requests
import re
import datetime
from time import sleep
import pandas as pd
S = "bookLink"
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44',
}
url = 'https://www.ptpress.com.cn/bookinfo/getBookListForEBTag'
book_info = []
for page in range(1,571):
data = {
'bookTagId':'a15a734f-0ae9-41d7-9012-6ef9de2e71c8',
'page':f'{page}',
'rows':'18',
'orderStr':'publish'
}
response = requests.post(url,data=data,headers=headers)
data = response.json()
author = data["data"]["data"][0]["author"]
isbn = data["data"]["data"][0]["isbn"]
publish = datetime.datetime.strptime(
data["data"]["data"][0]["publishDate"],"%Y%m"
)
discountPrice = data["data"]["data"][0]["discountPrice"]
bookDiscount = data["data"]["data"][0]["bookDiscount"]
price = data["data"]["data"][0]["price"]
bookId = data["data"]["data"][0]["bookId"]
executiveEditor = data["data"]["data"][0]["executiveEditor"]
bookName = data["data"]["data"][0]["bookName"]
picPath = data["data"]["data"][0]["picPath"]
bookLink = "https://www.ptpress.com.cn/shopping/buy?bookId=" + bookId
book_info.append({
"author":author,
"isbn":isbn,
"publish":publish,
"discountPrice":discountPrice,
"bookDiscount":bookDiscount,
"price":price,
"bookId":bookId,
"executiveEditor":executiveEditor,
"bookName":bookName,
"picPath":picPath,
"bookLink":bookLink
})
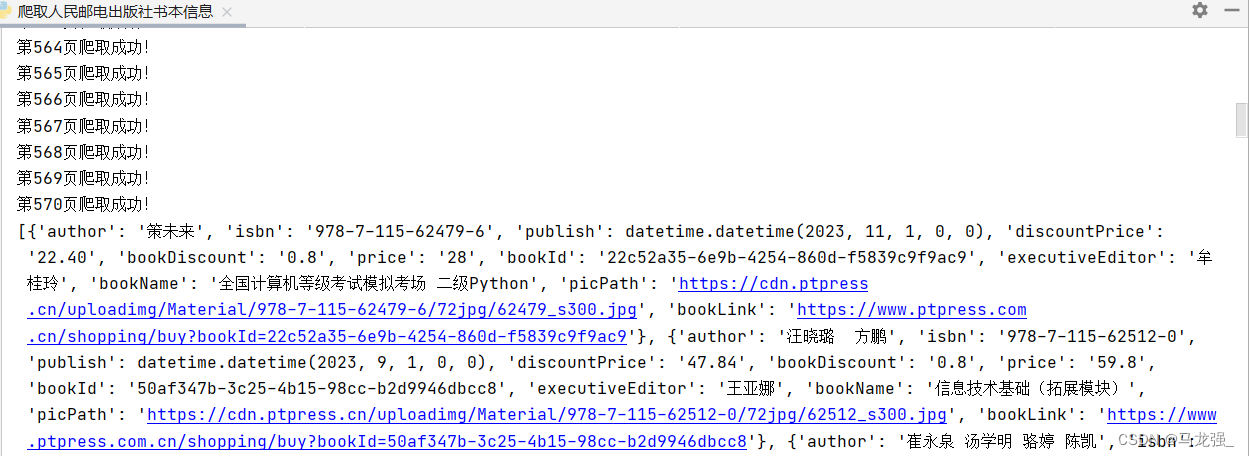
print(f"第{page}页爬取成功!")
sleep(1)
print(book_info)
# 将数据保存到Excel文件中
df = pd.DataFrame(book_info)
df.to_excel("book_info.xlsx", index=False)
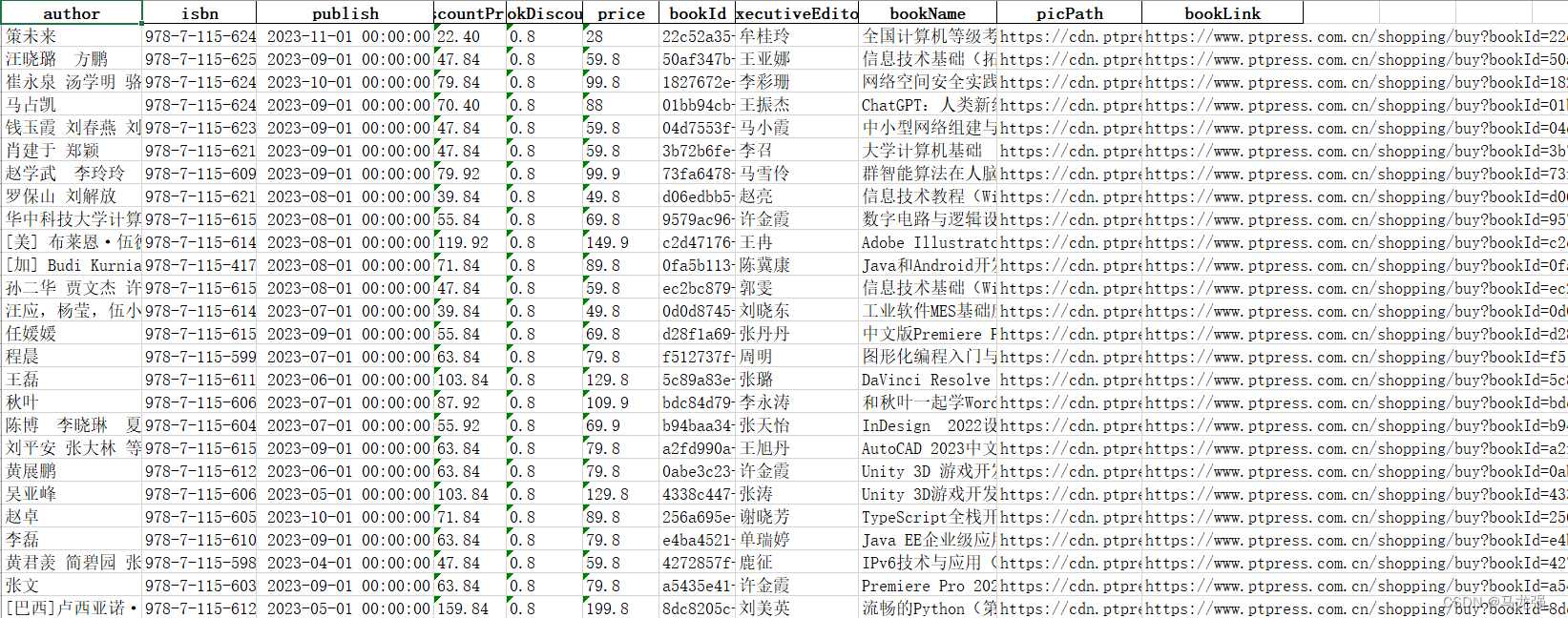
爬取结果:
2.将爬取内容放入打印并放入csv文件中
import requests
import re
import datetime
from time import sleep
import pandas as pd
import csv
S = "bookLink"
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44',
}
url = 'https://www.ptpress.com.cn/bookinfo/getBookListForEBTag'
book_info = []
for page in range(1,571):
data = {
'bookTagId':'a15a734f-0ae9-41d7-9012-6ef9de2e71c8',
'page':f'{page}',
'rows':'18',
'orderStr':'publish'
}
response = requests.post(url,data=data,headers=headers)
data = response.json()
author = data["data"]["data"][0]["author"]
isbn = data["data"]["data"][0]["isbn"]
publish = datetime.datetime.strptime(
data["data"]["data"][0]["publishDate"],"%Y%m"
)
discountPrice = data["data"]["data"][0]["discountPrice"]
bookDiscount = data["data"]["data"][0]["bookDiscount"]
price = data["data"]["data"][0]["price"]
bookId = data["data"]["data"][0]["bookId"]
executiveEditor = data["data"]["data"][0]["executiveEditor"]
bookName = data["data"]["data"][0]["bookName"]
picPath = data["data"]["data"][0]["picPath"]
bookLink = "https://www.ptpress.com.cn/shopping/buy?bookId=" + bookId
book_info.append({
"author":author,
"isbn":isbn,
"publish":publish,
"discountPrice":discountPrice,
"bookDiscount":bookDiscount,
"price":price,
"bookId":bookId,
"executiveEditor":executiveEditor,
"bookName":bookName,
"picPath":picPath,
"bookLink":bookLink
})
print(f"第{page}页爬取成功!")
sleep(1)
print(book_info)
# 将数据保存到csv文件中
df = pd.DataFrame(book_info)
df.to_csv("人民邮电计算机书本信息.csv", index=False)
爬取结果:

3.将爬取内容放入打印并放入MySQL数据库中
import requests
import re
import datetime
from time import sleep
import pandas as pd
import csv
import pymysql
S = "bookLink"
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44',
}
url = 'https://www.ptpress.com.cn/bookinfo/getBookListForEBTag'
book_info = []
for page in range(1,571):
data = {
'bookTagId':'a15a734f-0ae9-41d7-9012-6ef9de2e71c8',
'page':f'{page}',
'rows':'18',
'orderStr':'publish'
}
response = requests.post(url,data=data,headers=headers)
data = response.json()
author = data["data"]["data"][0]["author"]
isbn = data["data"]["data"][0]["isbn"]
publish = datetime.datetime.strptime(
data["data"]["data"][0]["publishDate"],"%Y%m"
)
discountPrice = data["data"]["data"][0]["discountPrice"]
bookDiscount = data["data"]["data"][0]["bookDiscount"]
price = data["data"]["data"][0]["price"]
bookId = data["data"]["data"][0]["bookId"]
executiveEditor = data["data"]["data"][0]["executiveEditor"]
bookName = data["data"]["data"][0]["bookName"]
picPath = data["data"]["data"][0]["picPath"]
bookLink = "https://www.ptpress.com.cn/shopping/buy?bookId=" + bookId
book_info.append({
"author":author,
"isbn":isbn,
"publish":publish,
"discountPrice":discountPrice,
"bookDiscount":bookDiscount,
"price":price,
"bookId":bookId,
"executiveEditor":executiveEditor,
"bookName":bookName,
"picPath":picPath,
"bookLink":bookLink
})
print(f"第{page}页爬取成功!")
sleep(1)
print(book_info)
# 将数据保存到MySQL数据库中
conn = pymysql.connect(host='localhost', user='root', password='your_password', db='your_database', charset='utf8')
cursor = conn.cursor()
# 创建表格booklist
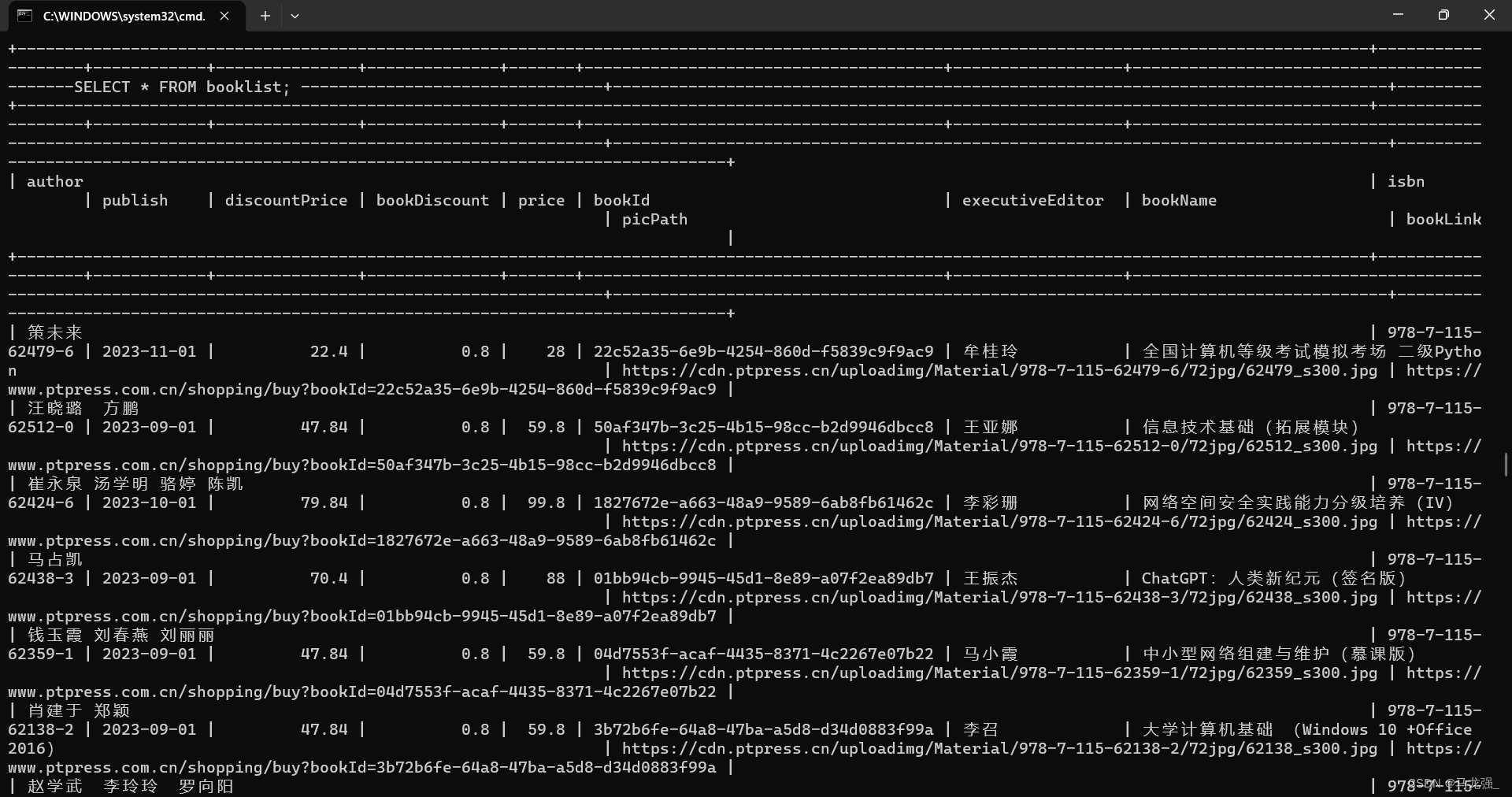
cursor.execute('CREATE TABLE IF NOT EXISTS booklist (author VARCHAR(255), isbn VARCHAR(255), publish DATE, discountPrice FLOAT, bookDiscount FLOAT, price FLOAT, bookId VARCHAR(255), executiveEditor VARCHAR(255), bookName VARCHAR(255), picPath VARCHAR(255), bookLink VARCHAR(255))')
# 将数据插入到表格booklist中
for book in book_info:
sql = f"INSERT INTO booklist (author, isbn, publish, discountPrice, bookDiscount, price, bookId, executiveEditor, bookName, picPath, bookLink) VALUES ('{book['author']}', '{book['isbn']}', '{book['publish'].strftime('%Y-%m-%d')}', {book['discountPrice']}, {book['bookDiscount']}, {book['price']}, '{book['bookId']}', '{book['executiveEditor']}', '{book['bookName']}', '{book['picPath']}', '{book['bookLink']}')"
cursor.execute(sql)
# 提交事务
conn.commit()
# 关闭连接
cursor.close()
conn.close()
爬取结果: