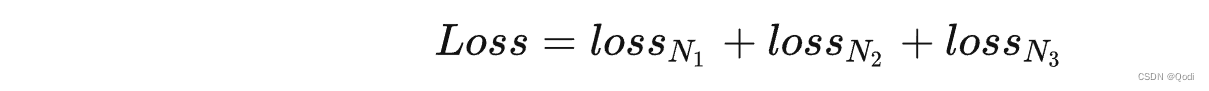PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
- 0. 前言
- 1. Fast R-CNN
- 1.1 模型架构
- 1.2 R-CNN 与 Fast R-CNN 对比
- 2. 实现 Fast R-CNN 目标检测
- 2.1 数据处理
- 2.2 模型构建
- 2.4 模型训练与测试
- 小结
- 系列链接
0. 前言
R-CNN 的主要缺点之一是生成预测结果需要较长时间,生成图像区域提议、调整区域尺寸以及提取与每个区域对应的特征是 R-CNN 目标检测模型的性能瓶颈。为了解决该问题,对 R-CNN 改进和优化后提出了 Fast R-CNN 算法,通过引入 RoI (Region of Interest) 池化层来极大地提高了检测速度和准确性,将整个图像输入到预训练模型以提取特征,并获取与原始图像的区域提议相对应的特征区域。在本节中,我们将介绍 Fast R-CNN 的工作原理,然后在自定义数据集上训练 Fast R-CNN 目标检测模型。
1. Fast R-CNN
1.1 模型架构
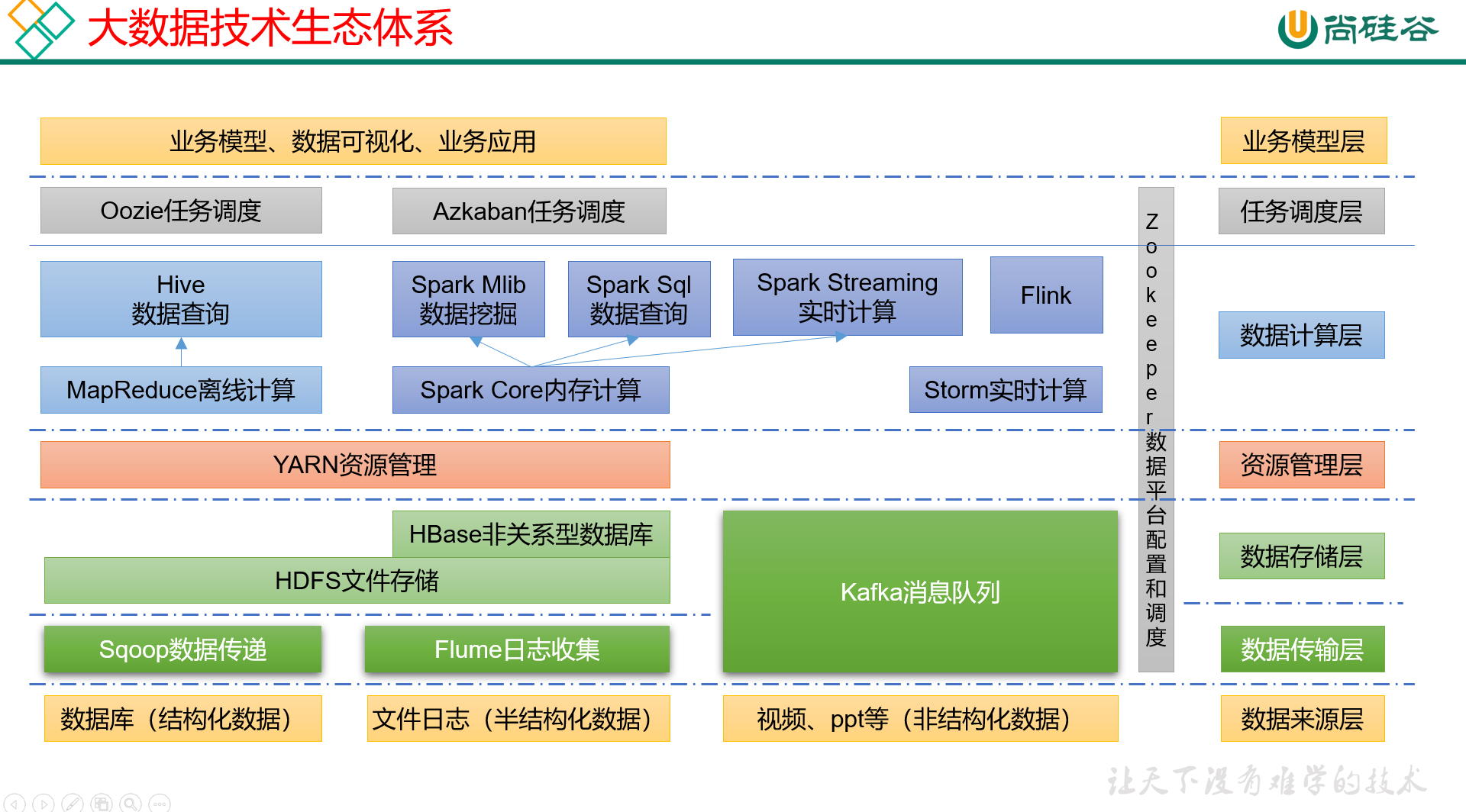
Fast R-CNN 是一种用于目标检测的深度学习模型,相比于传统的 R-CNN 模型的训练速度快 9 倍、测试时速度快 213 倍,通过下图可以了解 Fast R-CNN 原理:

通过上图,可以看到 Fast R-CNN 模型检测步骤如下:
- 将测试图像输入到预训练模型,在展平层之前提取图像特征,即特征图
- 提取图像对应的区域提议
- 提取对应于区域提议的特征图区域(使用
VGG16架构作为Fast R-RCNN主干网络时,由于执行了5次池化操作,图像的输出缩小了32倍,因此,如果在原始图像中存在一个边界框(40,32,200,240),那么在特征图中边界框(5,4,25,30)对应于原始图像的边界框(40,32,200,240)区域) - 将区域提议对应的特征图逐一通过感兴趣区域
RoI(Region of Interest) 池化层,使所有区域提议的特征图都具有相似的形状,RoIPool是一种区域池化操作,可以提取出固定大小的特征图,RoIPool内部会将RoI区域均匀地划分为k x k个部分,并针对每个小部分执行最大池化操作,最终将所有结果拼接在一起得到固定大小的输出特征图,RoIPool的输出大小是固定的,因此可以输入到后续网络中执行操作 - 通过全连接层传递
RoI池化层的输出值 - 训练模型预测每个区域提议对应的类别和偏移量
1.2 R-CNN 与 Fast R-CNN 对比
R-CNN 和 Fast R-CNN 的主要区别在于对象检测时特征图的生成方式不同,R-CNN 需要对每个区域提议执行卷积得到特征图,这一操作非常耗时,而 Fast R-CNN 则使用整张图像执行卷积得到特征图,之后对区域提议执行 RoIpooling 操作,从而避免了通过预训练模型传递所有(调整大小后的)区域提议,极大的减少了重复计算,提高了检测速度。
2. 实现 Fast R-CNN 目标检测
了解了 Fast R-CNN 的工作原理后,我们将使用与 R-CNN 一节中相同的数据集构建 Fast R-CNN 目标检测模型。
2.1 数据处理
(1) 导入所需库,并定义所需函数,大部分函数与 R-CNN 一节中相同:
import selectivesearch
from torchvision import transforms, models, datasets
from torchvision.ops import nms
import os
import torch
import numpy as np
from torch.utils.data import DataLoader, Dataset
from glob import glob
from random import randint
import cv2
from pathlib import Path
import torch.nn as nn
from torch import optim
from matplotlib import pyplot as plt
import pandas as pd
import matplotlib.patches as mpatches
device = 'cuda' if torch.cuda.is_available() else 'cpu'
IMAGE_ROOT = 'open-images-bus-trucks/images/images'
DF_RAW = pd.read_csv('open-images-bus-trucks/df.csv')
print(DF_RAW.head())
for i in range(20):
im, bbs, clss, _ = ds[i]
show_bbs(im, bbs, clss)
def extract_candidates(img):
img_lbl, regions = selectivesearch.selective_search(img, scale=200, min_size=100)
img_area = np.prod(img.shape[:2])
candidates = []
for r in regions:
if r['rect'] in candidates: continue
if r['size'] < (0.05*img_area): continue
if r['size'] > (1*img_area): continue
x, y, w, h = r['rect']
candidates.append(list(r['rect']))
return candidates
def extract_iou(boxA, boxB, epsilon=1e-5):
x1 = max(boxA[0], boxB[0])
y1 = max(boxA[1], boxB[1])
x2 = min(boxA[2], boxB[2])
y2 = min(boxA[3], boxB[3])
width = (x2 - x1)
height = (y2 - y1)
if (width<0) or (height <0):
return 0.0
area_overlap = width * height
area_a = (boxA[2] - boxA[0]) * (boxA[3] - boxA[1])
area_b = (boxB[2] - boxB[0]) * (boxB[3] - boxB[1])
area_combined = area_a + area_b - area_overlap
iou = area_overlap / (area_combined+epsilon)
return iou
FPATHS, GTBBS, CLSS, DELTAS, ROIS, IOUS = [], [], [], [], [], []
N = 2000
for ix, (im, bbs, labels, fpath) in enumerate(ds):
if(ix==N):
break
H, W, _ = im.shape
candidates = extract_candidates(im)
candidates = np.array([(x,y,x+w,y+h) for x,y,w,h in candidates])
ious, rois, clss, deltas = [], [], [], []
ious = np.array([[extract_iou(candidate, _bb_) for candidate in candidates] for _bb_ in bbs]).T
for jx, candidate in enumerate(candidates):
cx,cy,cX,cY = candidate
candidate_ious = ious[jx]
best_iou_at = np.argmax(candidate_ious)
best_iou = candidate_ious[best_iou_at]
best_bb = _x,_y,_X,_Y = bbs[best_iou_at]
if best_iou > 0.3:
clss.append(labels[best_iou_at])
else:
clss.append('background')
delta = np.array([_x-cx, _y-cy, _X-cX, _Y-cY]) / np.array([W,H,W,H])
deltas.append(delta)
rois.append(candidate / np.array([W,H,W,H]))
FPATHS.append(fpath)
IOUS.append(ious)
ROIS.append(rois)
CLSS.append(clss)
DELTAS.append(deltas)
GTBBS.append(bbs)
FPATHS, GTBBS, CLSS, DELTAS, ROIS = [item for item in [FPATHS, GTBBS, CLSS, DELTAS, ROIS]]
targets = pd.DataFrame([clss for l in CLSS for clss in l], columns=['label'])
label2target = {l:t for t,l in enumerate(targets['label'].unique())}
target2label = {t:l for l,t in label2target.items()}
background_class = label2target['background']
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
def preprocess_image(img):
img = torch.tensor(img).permute(2,0,1)
img = normalize(img)
return img.to(device).float()
def decode(_y):
_, preds = _y.max(-1)
return preds
(2) 创建 FRCNNDataset 类,该类返回图像、类别标签、真实边界框、区域提议和每个区域提议对应的偏移量:
class FRCNNDataset(Dataset):
def __init__(self, fpaths, rois, labels, deltas, gtbbs):
self.fpaths = fpaths
self.gtbbs = gtbbs
self.rois = rois
self.labels = labels
self.deltas = deltas
def __len__(self):
return len(self.fpaths)
def __getitem__(self, ix):
fpath = str(self.fpaths[ix])
image = cv2.imread(fpath, 1)[...,::-1]
gtbbs = self.gtbbs[ix]
rois = self.rois[ix]
labels = self.labels[ix]
deltas = self.deltas[ix]
assert len(rois) == len(labels) == len(deltas), f'{len(rois)}, {len(labels)}, {len(deltas)}'
return image, rois, labels, deltas, gtbbs, fpath
def collate_fn(self, batch):
input, rois, rixs, labels, deltas = [], [], [], [], []
for ix in range(len(batch)):
image, image_rois, image_labels, image_deltas, image_gt_bbs, image_fpath = batch[ix]
image = cv2.resize(image, (224,224))
input.append(preprocess_image(image/255.)[None])
rois.extend(image_rois)
rixs.extend([ix]*len(image_rois))
labels.extend([label2target[c] for c in image_labels])
deltas.extend(image_deltas)
input = torch.cat(input).to(device)
rois = torch.Tensor(rois).float().to(device)
rixs = torch.Tensor(rixs).float().to(device)
labels = torch.Tensor(labels).long().to(device)
deltas = torch.Tensor(deltas).float().to(device)
return input, rois, rixs, labels, deltas
以上代码与 R-CNN 一节的数据集类非常相似,但其返回了更多信息,包括 rois 和 rixs,其中 rois 矩阵是一个 Nx5 的矩阵,N 表示共有 N 个 RoI 区域。每个 RoI 区域由 (batch_index, x_min, y_min, x_max, y_max) 五个值组成,表示该 RoI 区域是来自于 batch 中的哪个图像,以及在该图像中对应的位置坐标,输入包含多个图像,而 rois 是包含所有边界框的列表,我们无法确认有多少 rois 属于第一个图像,有多少属于第二个图像…,而使用 ridx 就可以进行确认,ridx 是一个索引列表,列表中的每个整数都与相应的图像相关联,例如,如果 ridx 为 [0,0,0,1,1,2,3,3,3],那么前三个边界框属于批数据中的第一个图像,接下来的两个边界框属于批数据中的第二张图片,以此类推。
(3) 创建训练和测试数据集:
n_train = 9*len(FPATHS)//10
train_ds = FRCNNDataset(FPATHS[:n_train], ROIS[:n_train], CLSS[:n_train], DELTAS[:n_train], GTBBS[:n_train])
test_ds = FRCNNDataset(FPATHS[n_train:], ROIS[n_train:], CLSS[n_train:], DELTAS[n_train:], GTBBS[n_train:])
print(len(test_ds))
from torch.utils.data import TensorDataset, DataLoader
train_loader = DataLoader(train_ds, batch_size=2, collate_fn=train_ds.collate_fn, drop_last=True)
test_loader = DataLoader(test_ds, batch_size=2, collate_fn=test_ds.collate_fn, drop_last=True)
2.2 模型构建
(1) 定义模型。
首先,导入 torchvision.ops 类中的 RoIPool 方法:
from torchvision.ops import RoIPool
import torchvision
定义 FRCNN 网络模块:
class FRCNN(nn.Module):
def __init__(self):
super().__init__()
加载预训练模型并冻结参数:
rawnet = torchvision.models.vgg16_bn(pretrained=True)
for param in rawnet.features.parameters():
param.requires_grad = True
提取特征直到最后一层:
self.seq = nn.Sequential(*list(rawnet.features.children())[:-1])
指定 RoIPool 提取 7 x 7 输出,spatial_scale 是提议(来自原始图像)缩放因子,以便每个输出在通过展平层之前具有相同的形状。图像大小为 224 x 224,而特征图大小为 14 x 14:
self.roipool = RoIPool(7, spatial_scale=14/224)
定义网络输出头,cls_score 和 bbox:
feature_dim = 512*7*7
self.cls_score = nn.Linear(feature_dim, len(label2target))
self.bbox = nn.Sequential(
nn.Linear(feature_dim, 512),
nn.ReLU(),
nn.Linear(512, 4),
nn.Tanh(),
)
定义损失函数:
self.cel = nn.CrossEntropyLoss()
self.sl1 = nn.L1Loss()
定义 forward 方法,使用图像、区域提议和区域提议的索引作为网络输入:
def forward(self, input, rois, ridx):
通过预训练模型传递输入图像:
res = input
res = self.seq(res)
创建 rois 矩阵作为 self.roipool 的输入,首先将 ridx 拼接作为第一列,接下来的四列是区域提议边界框的坐标值:
rois = torch.cat([ridx.unsqueeze(-1), rois*224], dim=-1)
res = self.roipool(res, rois)
feat = res.view(len(res), -1)
cls_score = self.cls_score(feat)
bbox = self.bbox(feat) # .view(-1, len(label2target), 4)
return cls_score, bbox
定义损失值计算函数 calc_loss:
def calc_loss(self, probs, _deltas, labels, deltas):
detection_loss = self.cel(probs, labels)
ixs, = torch.where(labels != background_class)
_deltas = _deltas[ixs]
deltas = deltas[ixs]
self.lmb = 10.0
if len(ixs) > 0:
regression_loss = self.sl1(_deltas, deltas)
return detection_loss + self.lmb * regression_loss, detection_loss.detach(), regression_loss.detach()
else:
regression_loss = 0
return detection_loss + self.lmb * regression_loss, detection_loss.detach(), regression_loss
(2) 定义训练和验证的函数:
def train_batch(inputs, model, optimizer, criterion):
input, rois, rixs, clss, deltas = inputs
model.train()
optimizer.zero_grad()
_clss, _deltas = model(input, rois, rixs)
loss, loc_loss, regr_loss = criterion(_clss, _deltas, clss, deltas)
accs = clss == decode(_clss)
loss.backward()
optimizer.step()
return loss.detach(), loc_loss, regr_loss, accs.cpu().numpy()
def validate_batch(inputs, model, criterion):
input, rois, rixs, clss, deltas = inputs
with torch.no_grad():
model.eval()
_clss,_deltas = model(input, rois, rixs)
loss, loc_loss, regr_loss = criterion(_clss, _deltas, clss, deltas)
_clss = decode(_clss)
accs = clss == _clss
return _clss, _deltas, loss.detach(), loc_loss, regr_loss, accs.cpu().numpy()
2.4 模型训练与测试
(1) 训练模型:
frcnn = FRCNN().to(device)
criterion = frcnn.calc_loss
optimizer = optim.SGD(frcnn.parameters(), lr=1e-3)
n_epochs = 10
train_loss_epochs = []
train_loc_loss_epochs = []
train_regr_loss_epochs = []
train_acc_epochs = []
val_loc_loss_epochs = []
val_regr_loss_epochs = []
val_loss_epochs = []
val_acc_epochs = []
for epoch in range(n_epochs):
train_loss = []
train_loc_loss = []
train_regr_loss = []
train_acc = []
val_loc_loss = []
val_regr_loss = []
val_loss = []
val_acc = []
_n = len(train_loader)
for ix, inputs in enumerate(train_loader):
loss, loc_loss, regr_loss, accs = train_batch(inputs, frcnn,
optimizer, criterion)
pos = (epoch + (ix+1)/_n)
train_loss.append(loss.item())
if loc_loss != 0:
train_loc_loss.append(loc_loss.item())
print(loc_loss)
if regr_loss != 0:
train_regr_loss.append(regr_loss.item())
train_acc.append(accs.mean())
train_loss_epochs.append(np.average(train_loss))
train_loc_loss_epochs.append(np.average(train_loc_loss))
train_regr_loss_epochs.append(np.average(train_regr_loss))
train_acc_epochs.append(np.average(train_acc))
_n = len(test_loader)
for ix,inputs in enumerate(test_loader):
_clss, _deltas, loss, \
loc_loss, regr_loss, accs = validate_batch(inputs,
frcnn, criterion)
pos = (epoch + (ix+1)/_n)
val_loss.append(loss.item())
if loc_loss != 0:
val_loc_loss.append(loc_loss.item())
# print(val_regr_loss)
# val_regr_loss.append(regr_loss)
if regr_loss != 0:
val_regr_loss.append(regr_loss.item())
val_acc.append(accs.mean())
val_loss_epochs.append(np.average(val_loss))
val_loc_loss_epochs.append(np.average(val_loc_loss))
val_regr_loss_epochs.append(np.average(val_regr_loss))
val_acc_epochs.append(np.average(val_acc))
(2) 损失的变化如下:
epochs = np.arange(n_epochs)+1
plt.subplot(121)
plt.plot(epochs, train_acc_epochs, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc_epochs, 'r', label='Test accuracy')
plt.title('Training and Test accuracy over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.grid('off')
plt.subplot(122)
plt.plot(epochs, train_loss_epochs, 'bo', label='Training loss')
plt.plot(epochs, val_loss_epochs, 'r', label='Test loss')
plt.title('Training and Test loss over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid('off')
plt.show()

(3) 修改 show_bbs() 函数用于可视化 Fast R-CNN 检测结果:
def show_bbs(im, bbs, clss, ax):
# fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))
ax.imshow(im)
for ix, (xmin, ymin, xmax, ymax) in enumerate(bbs):
rect = mpatches.Rectangle(
(xmin, ymin), xmax-xmin, ymax-ymin,
fill=False,
edgecolor='red',
linewidth=1)
ax.add_patch(rect)
centerx = xmin # + new_w/2
centery = ymin + 20# + new_h - 10
plt.text(centerx, centery, clss[ix],fontsize = 20,color='red')
(4) 定义函数预测测试图像。
将文件名作为输入,然后读取文件并将其缩放为 224 x 224:
from PIL import Image
def test_predictions(filename):
img = cv2.resize(np.array(Image.open(filename)), (224,224))
获取区域提议并将其转换为 (x1,y1,x2,y2) 格式(左上像素和右下像素坐标),然将边界框左上角和右下角的像素坐标转换为相对于图像宽度和高度的比例,以图像的比例表示。具体做法是,将左上角和右下角的坐标值除以图像对应的宽度和高度,即可得到相应的比例:
candidates = extract_candidates(img)
candidates = [(x,y,x+w,y+h) for x,y,w,h in candidates]
预处理图像并缩放感兴趣区域 rois:
input = preprocess_image(img/255.)[None]
rois = [[x/224,y/224,X/224,Y/224] for x,y,X,Y in candidates]
由于所有区域提议都属于同一图像,因此 rixs 为零值列表(列表长度与区域提议数量相同):
rixs = np.array([0]*len(rois))
通过训练后的模型前向传播输入图像和 rois,并获得每个区域提议的置信度和类别分数:
rois, rixs = [torch.Tensor(item).to(device) for item in [rois, rixs]]
with torch.no_grad():
frcnn.eval()
probs, deltas = frcnn(input, rois, rixs)
confs, clss = torch.max(probs, -1)
过滤掉背景类别:
candidates = np.array(candidates)
confs, clss, probs, deltas = [tensor.detach().cpu().numpy() for tensor in [confs, clss, probs, deltas]]
ixs = clss!=background_class
confs, clss, probs, deltas, candidates = [tensor[ixs] for tensor in [confs, clss, probs, deltas, candidates]]
bbs = candidates + deltas
使用非极大值抑制 (non-maximum suppression, NMS) 删除重复的边界框,并获得以高置信度预测为目标对象的区域提议的索引:
ixs = nms(torch.tensor(bbs.astype(np.float32)), torch.tensor(confs), 0.05)
confs, clss, probs, deltas, candidates, bbs = [tensor[ixs] for tensor in [confs, clss, probs, deltas, candidates, bbs]]
if len(ixs) == 1:
confs, clss, probs, deltas, candidates, bbs = [tensor[None] for tensor in [confs, clss, probs, deltas, candidates, bbs]]
bbs = bbs.astype(np.uint16)
绘制预测边界框:
_, ax = plt.subplots(1, 2, figsize=(20,10))
ax[0].imshow(img)
ax[0].grid(False)
ax[0].set_title(filename.split('/')[-1])
if len(confs) == 0:
ax[1].imshow(img)
ax[1].set_title('No objects')
plt.show()
return
else:
show_bbs(img, bbs=bbs.tolist(), clss=[target2label[c] for c in clss.tolist()], ax=ax[1])
ax[1].set_title('predicted bounding box and class')
plt.show()
(5) 在测试图像上进行预测:
for i in range(50):
# image, crops, bbs, labels, deltas, gtbbs, fpath = test_ds[i]
test_predictions(test_ds[i][-1])

上述代码执行时间为 0.5 秒,明显优于 R-CNN,但其仍然无法满足实时任务的需求。这主要是因为我们仍在使用两种不同的模型,一种用于生成区域提议,另一种用于预测类别和偏移量。
小结
Fast R-CNN 改进了 R-CNN,引入 RoI (Region of Interest) 池化层极大地提高了检测速度和准确性。Fast R-CNN 极大地推动了目标检测领域的发展,为后续的一系列算法奠定了基础,在准确性和速度之间取得了良好的平衡,成为了目标检测算法的重要里程碑。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测








![[Error]在Swift项目Build Settings的Preprocessor Macros中定义的宏无效的问题](https://img-blog.csdnimg.cn/82261f16048145588f3c6d8e49f2e919.png#pic_left)