es
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/getting-started.html
倒排索引:
正排–>从目录到文章内容
倒排–>内容到目录文章标题
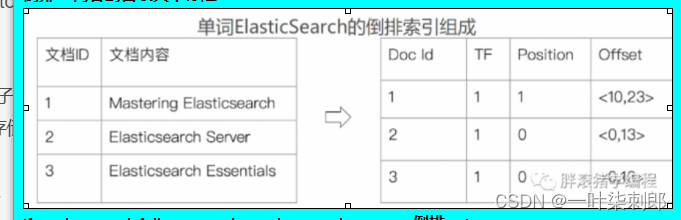
if we dont need full text search ,we dont need to create 倒排 using text type
分词:
(1)Analyzer 组件对文档执行一些操作并将具体子句拆分为 token/term,简单说就是分词,然后将这些术语作为倒排索引存储在磁盘中,
(2)analyzer 三部分:
character Filter 剔除html标签,Tokenizer 分词,英文中按照空格分词,Token Filter分词过滤 过滤调stopwords
https://zhuanlan.zhihu.com/p/137916758
核心: 单词词典,所有document的单词,比较大 文档ID, TF词频 单词在文中出现的频率 Position 单词出现的位置, 偏移offset 出现的开始和结束
中文分词器,常用IK 支持自定义词库热更新分词词典
ik_max_word:粒度最细,穷尽所有组合 , ik_smart 粗粒度
分词器调优:
mapping
Mapping is the process of defining how a document, and the fields it contains, are stored and indexed.
dynamic mapping is enabled, es can automatically index the new added data by mapping boolean string and so on to es datatypes; ofcourse wed better control our data
index principle
wed better index the same field(same data) in deffifrent way for different purpose
es aggregations enable u to analyze your data
create a table, index_api like storing data to a table
mapping is to set the tyepe of table column
document like a row
SEARCH
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/getting-started-search.html
Query DSL: https://www.elastic.co/guide/en/elasticsearch/reference/6.8/query-dsl.html#query-dsl
数据类型:
Text :索引全文值字段,字段需要被分词
Keyword: 索引结构化内容,通常用于排序。过滤和聚合
其他常见date,number等
document API
index api add/update a json document in a specified index making it searchable, automatically created if not exist (default)
update/delete/reindex/get
docvalue_fields: use Doc fileds structure stored on disk to accelerate the speed of sorting and aggregation of non-text filed, dont need to use 倒排索引
aggeration
“size”:0, #最外围的size表示不返回文档包括元数据, “_source”:false 还返回元数据
“terms” 是 表示对keyword的精确查询,在聚合中表示分组
所有带bucket_前缀的aggs都只能用于桶分组计算
index.max_result_window 的值表示from+size的最大值,默认为1w,而非表示结果集数量,如果分页要往后,则需要search_after 和 scroll
向量空间模型
https://www.zhihu.com/search?type=content&q=%E5%90%91%E9%87%8F%E7%A9%BA%E9%97%B4%E6%A8%A1%E5%9E%8B
分词
2 高维向量表示doc (1w1,1w2,1*w3,0),1表示词出现,w表示词的权重,0表示未出现,权重由TF和IDF决定
计算查询和文档向量的相似度
score
评分影响因素: TF词频,IDF逆词频(关键词在collection中的重要程度,若很多问doc中都出现了则IDC比较低,不太重要),
字段长度越短评分越高,文档级别boost, 某个子查询的boost,会让查询结果doc评分更高