参考代码:SparseBEV
动机与主要贡献:
BEV感知可以按照是否显式构建BEV特征进行划分,显式构建BEV特征的方法需要额外计算量用于特征构建,而类似query方案的方法则不需要这样做。比较两种类型的方法,前者需要更多计算资源但是效果好,后者需要的计算资源相对较少,但是性能相比起来不足。在这篇文章中从如下3个维度去分析和优化基于query的感知方法:
- 1)分析query之间的关联,在基于query的方法中往往使用self-attention的方式构建query之间的关联,但是对于3D空间中的物体它们是存在空间距离的,相隔较远的物体它们之间的关联性自然就弱
- 2)自身和目标的运动补偿,自动驾驶的场景是运动场景,则需要对自车和周围物体的运动状态建模,从而实现在特征维度的对齐和采样
- 3)不同时许的特征融合,提出一种channel-wise和spatial-wise attention的特征融合方法
算法流程结构:
算法的流程结构是CNN编解码+transformer解码的结构,见下图
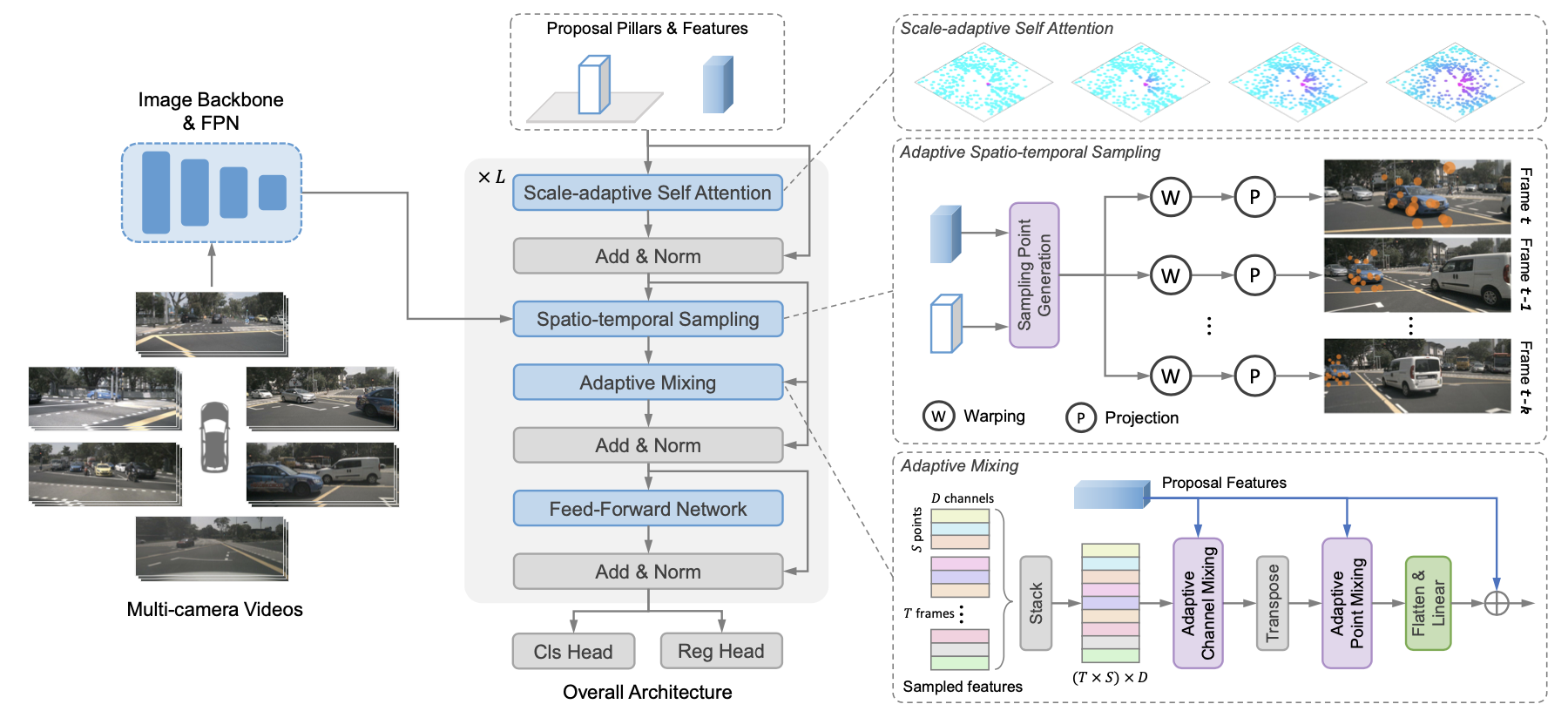
上图中左边的3个小框就分别代表了文章的3个主要工作:基于query距离的self-attention、自车和目标运动补偿、时序融合。
基于query距离的self-attention:
原本query之间的self-attention是global的,这就把相隔很远的物体也关联起来了,但按照直观理解这样是不太合理的,则需要考虑两个query之间的实际距离:
D
i
,
j
=
(
x
i
−
x
j
)
2
+
(
y
i
−
y
j
)
2
D_{i,j}=\sqrt{(x_i-x_j)^2+(y_i-y_j)^2}
Di,j=(xi−xj)2+(yi−yj)2
那么这个距离就通过如下方式添加到attention的计算过程中:
A
t
t
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
−
τ
D
)
V
Attn(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d}}-\tau D)V
Attn(Q,K,V)=softmax(dQKT−τD)V
其中,
τ
\tau
τ适用于控制距离作用的可学习因子,避免直接按照距离划分太过生硬,也让这个过程具有数据驱动的能力。对于这个
τ
\tau
τ其实是根据多头注意力的个数确定的,也就是对多头注意力的每个头预测一个距离因子。那么不同的距离因子对于实际query的感受野影响见下图所示:
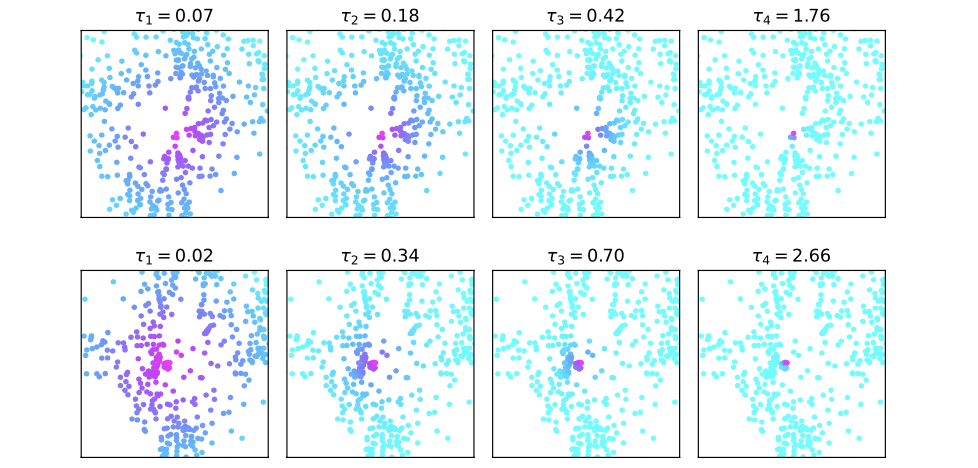
自然
τ
\tau
τ越大关注的距离也就越近了,同时对应的实验结果也显示了大的目标需要的感受野范围也就越大:
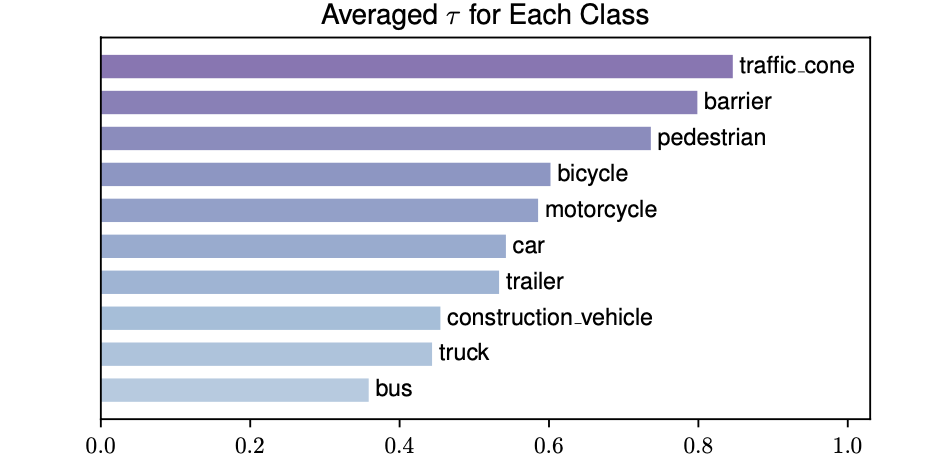
自车和目标运动补偿:
在Deformable Attention中已经存在基于query的采样offset预测,但是它与目标的实际大小不相关,完全由参与预测的MLP决定。则对于每个query这里分别预测相对物体长宽高的offset,从而使得offset的生成更加符合目标的空间实际,这是对offset生成部分的改动。相比传统的offset生成方式有mAP上1个点左右的提升:

确定offset生成方式之后之前需要对齐不同时序下的特征,自然需要依据自身pose变化对特征进行变换,并且对于场景中的运动目标还需要使用速度进行补偿。两种运动对齐的影响:

时序融合:
在实现多桢数据对齐之后便是需要对多桢数据进行融合,这里融合不是简单concat这类操作,而是使用channel-wise和spatial-wise attention的方式进行。不同的融合策略对于性能的影响:
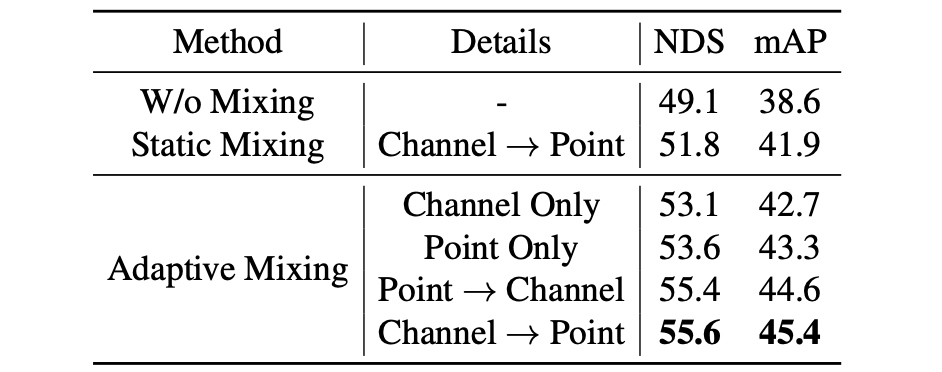
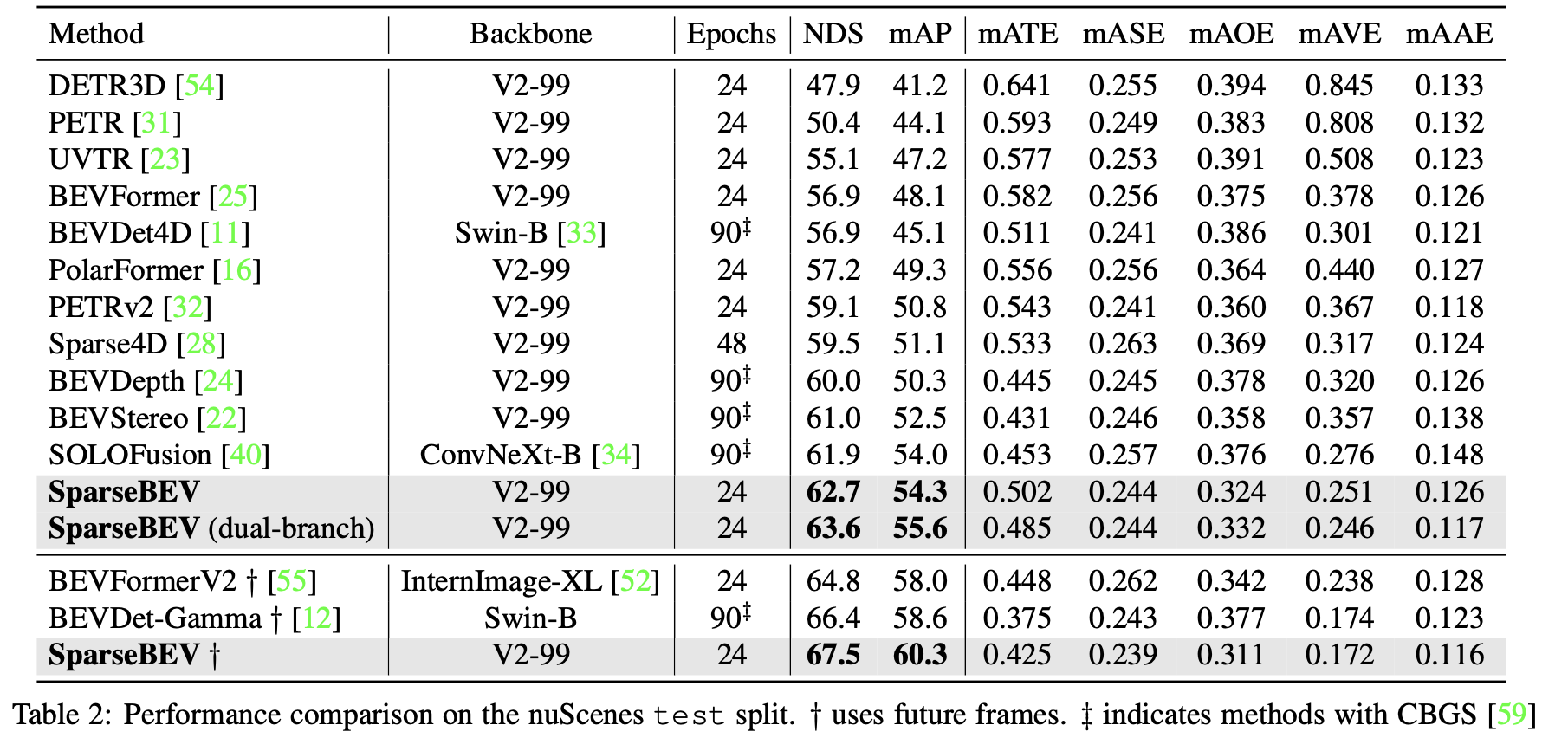
实验结果:
nuScenes test:
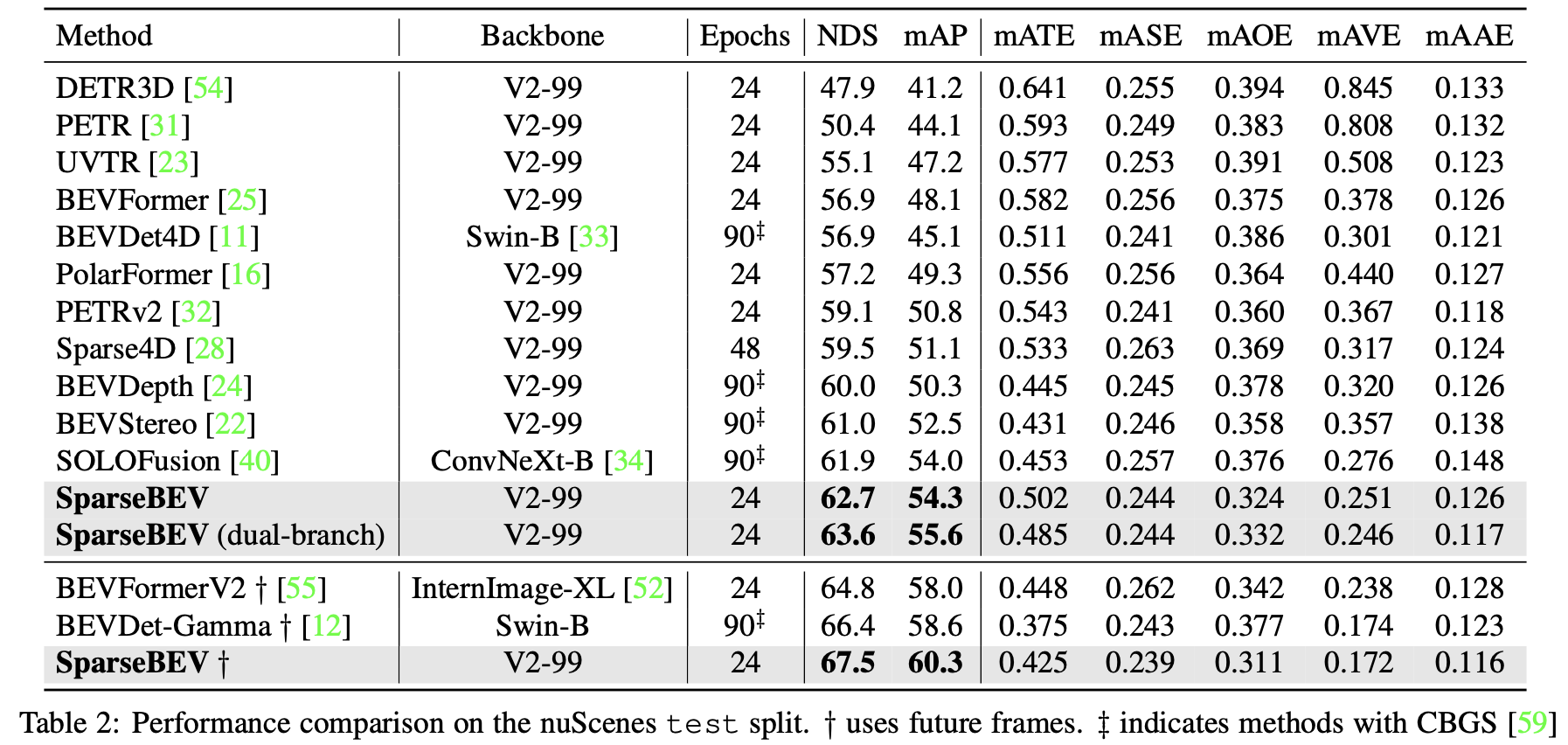
nuScenes val: