文章目录
- 1. JVM进程缓存
- 2. Lua语法
- 3. 实现多级缓存
- 3.1 反向代理流程
- 3.2 OpenResty快速入门
- 4. 查询Tomcat
- 4.1 发送http请求的API
- 4.2 封装http工具
- 4.3 基于ID负载均衡
- 4.4 流程小结
- 5. Redis缓存预热
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,如图: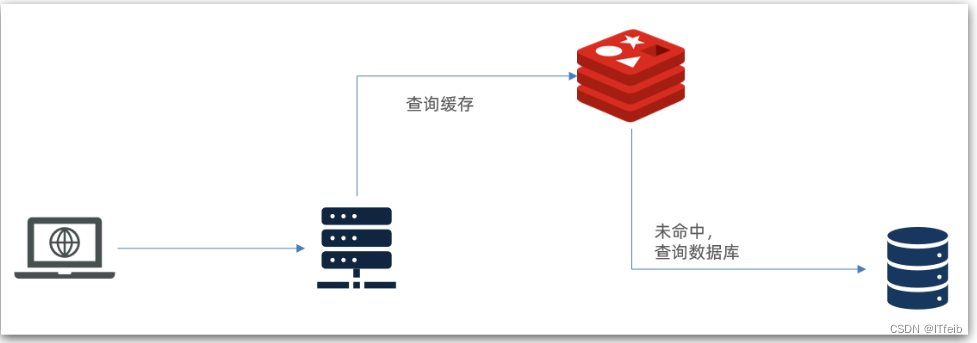
存在下面的问题:
-
请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
-
Redis缓存失效时,会对数据库产生冲击
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能
在多级缓存架构中,Nginx内部需要编写本地缓存查询、Redis查询、Tomcat查询的业务逻辑,因此这样的nginx服务不再是一个反向代理服务器,而是一个编写业务的Web服务器了。

可见,多级缓存的关键有两个:
- 一个是在nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询
- 另一个就是在Tomcat中实现JVM进程缓存
- Nginx编程则会用到OpenResty框架结合Lua这样的语言。
1. JVM进程缓存
案例:
需求:利用Caffeine实现下列需求:
- 给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
- 给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库
- 缓存初始大小为100
- 缓存上限为10000
首先,我们需要定义两个Caffeine的缓存对象,分别保存商品、库存的缓存数据。
在item-service的com.heima.item.config包下定义CaffeineConfig类:

然后,修改item-service中的com.heima.item.web包下的ItemController类,添加缓存逻辑:

2. Lua语法
Nginx编程需要用到Lua语言,因此学习Lua的基本语法。
Lua中支持的常见数据类型包括:

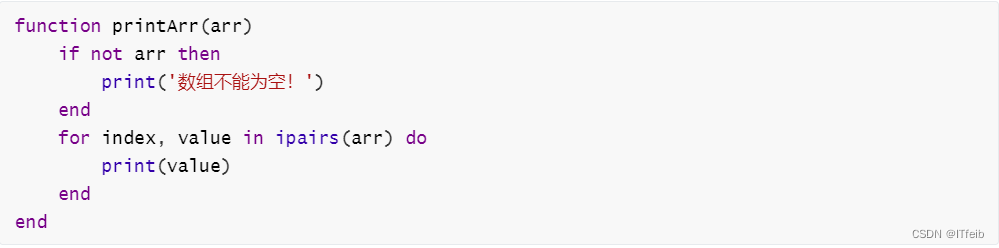
需求:自定义一个函数,可以打印table,当参数为nil时,打印错误信息
3. 实现多级缓存
多级缓存的实现离不开Nginx编程,而Nginx编程又离不开OpenResty。
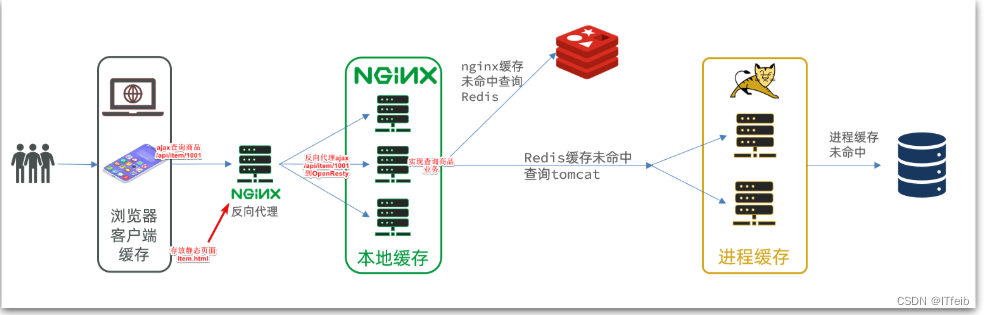
- windows上的nginx用来做反向代理服务,将前端的查询商品的ajax请求代理到OpenResty集群
- OpenResty集群用来编写多级缓存业务
3.1 反向代理流程
现在,商品详情页使用的是假的商品数据。不过在浏览器中,可以看到页面有发起ajax请求查询真实商品数据。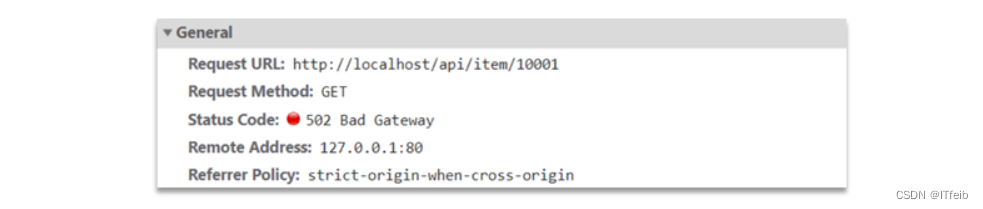
请求地址是localhost,端口是80,就被windows上安装的Nginx服务给接收到了。然后代理给了OpenResty集群:
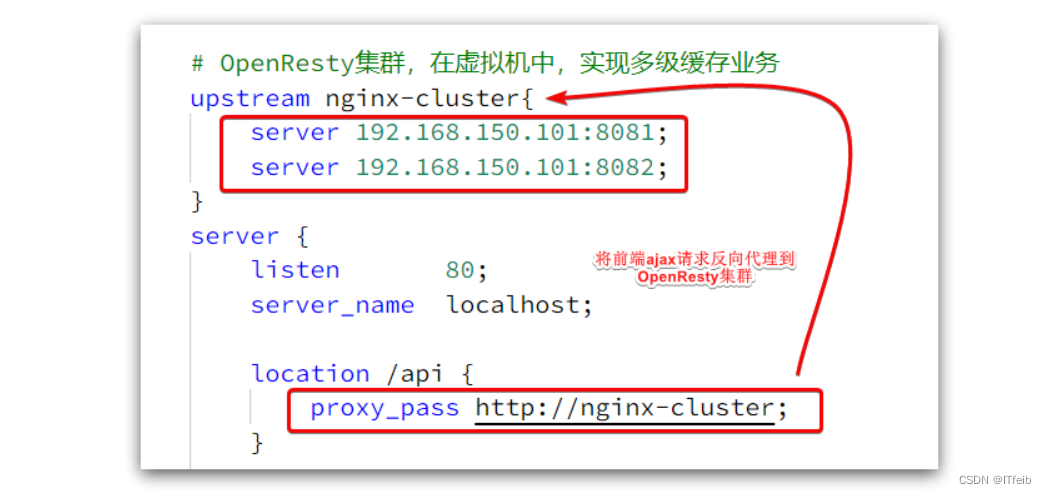
3.2 OpenResty快速入门
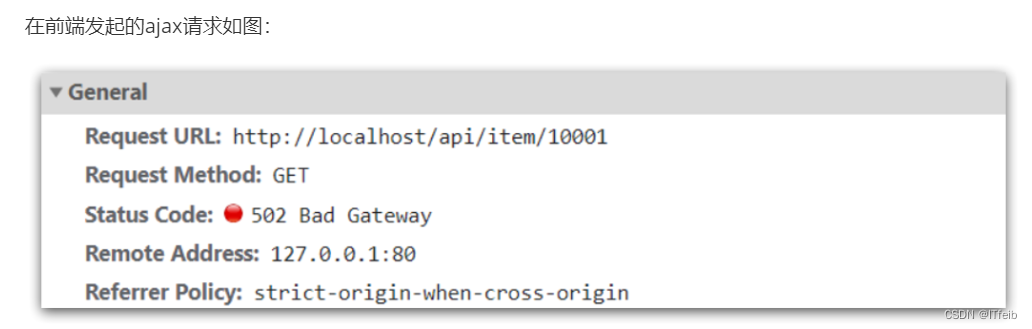
可以看到商品id是以路径占位符方式传递的,因此可以利用正则表达式匹配的方式来获取ID
OpenResty的很多功能都依赖于其目录下的Lua库,需要在nginx.conf中指定依赖库的目录,并导入依赖:
1)添加对OpenResty的Lua模块的加载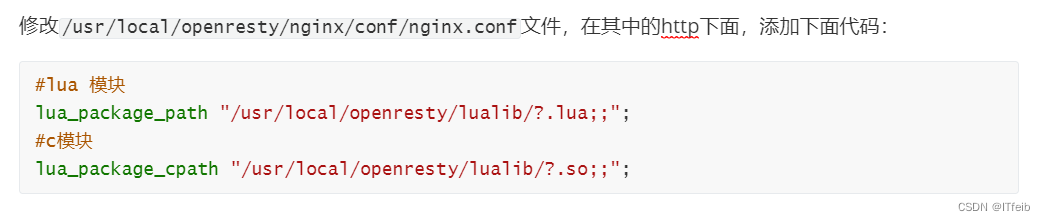
2)获取商品id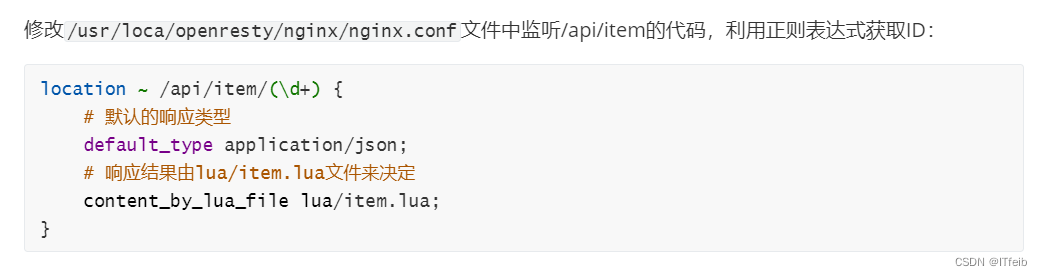
3)编写item.lua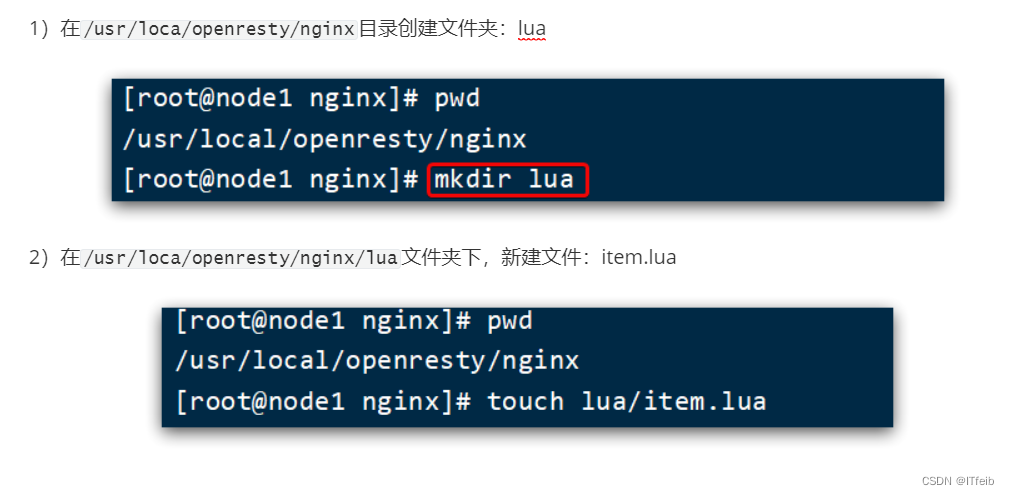

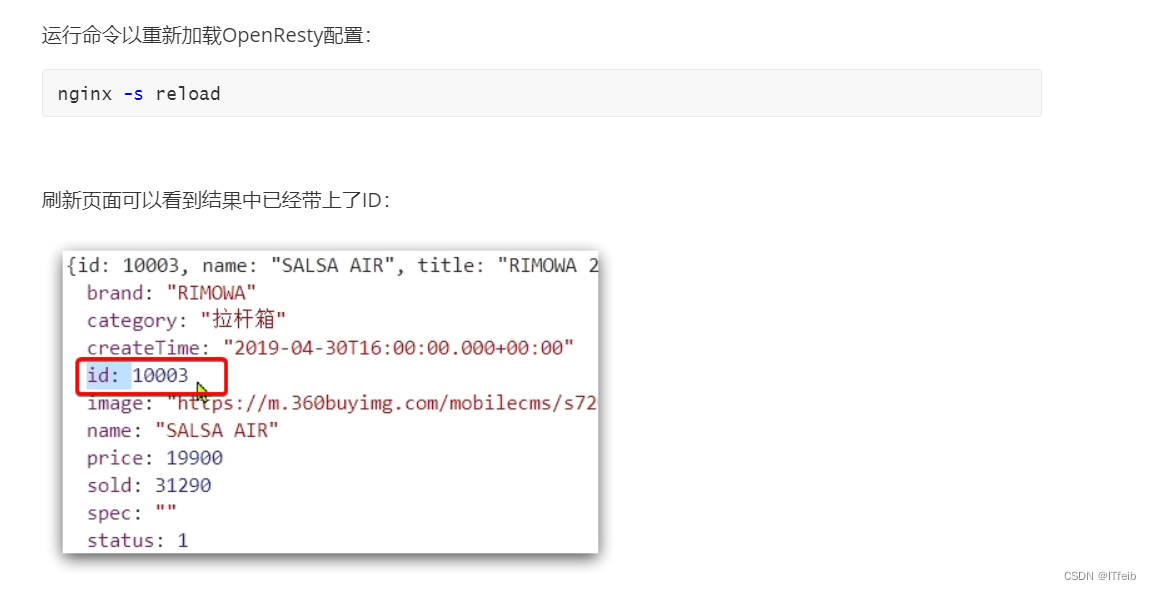
4. 查询Tomcat
4.1 发送http请求的API
nginx提供了内部API用以发送http请求:
返回的响应内容包括:
- resp.status:响应状态码
- resp.header:响应头,是一个table
- resp.body:响应体,就是响应数据
注意:这里的path是路径,并不包含IP和端口。这个请求会被nginx内部的server监听并处理。但是我们希望这个请求发送到Tomcat服务器,所以还需要编写一个server来对这个路径做反向代理: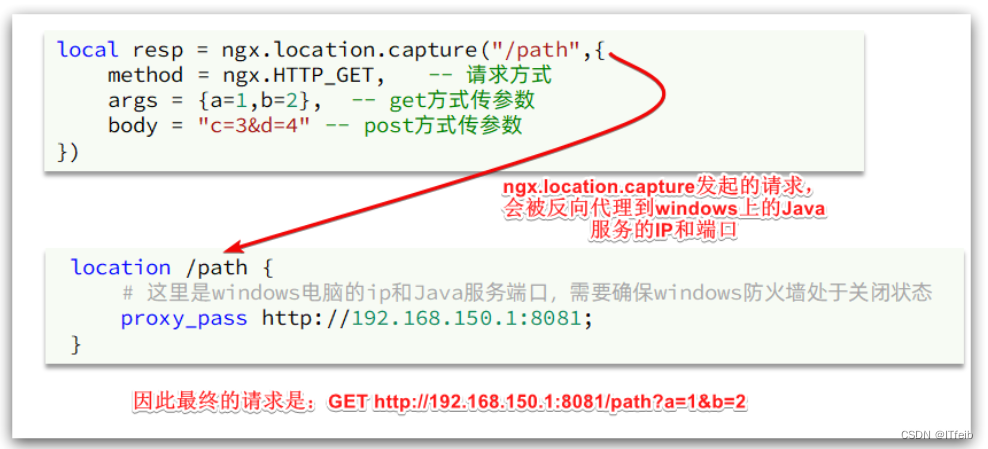
4.2 封装http工具
1)添加反向代理,到windows的Java服务
因为item-service中的接口都是/item开头,所以我们监听/item路径,代理到windows上的tomcat服务。
以后,只要我们调用ngx.location.capture("/item"),就一定能发送请求到windows的tomcat服务。
2)封装工具类
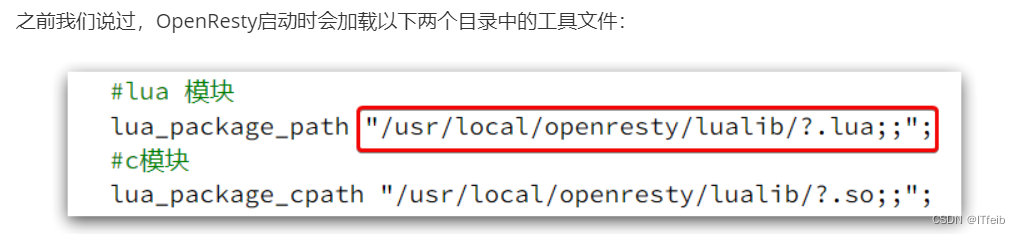
所以,自定义的http工具也需要放到这个目录下。
在/usr/local/openresty/lualib目录下,新建一个common.lua文件:内容如下:

这个工具将read_http函数封装到_M这个table类型的变量中,并且返回,这类似于导出。
使用的时候,可以利用require('common')来导入该函数库,这里的common是函数库的文件名。
3)实现商品查询
最后,我们修改/usr/local/openresty/lua/item.lua文件,利用刚刚封装的函数库实现对tomcat的查询:
这里查询到的结果是json字符串,并且包含商品、库存两个json字符串,页面最终需要的是把两个json拼接为一个json:
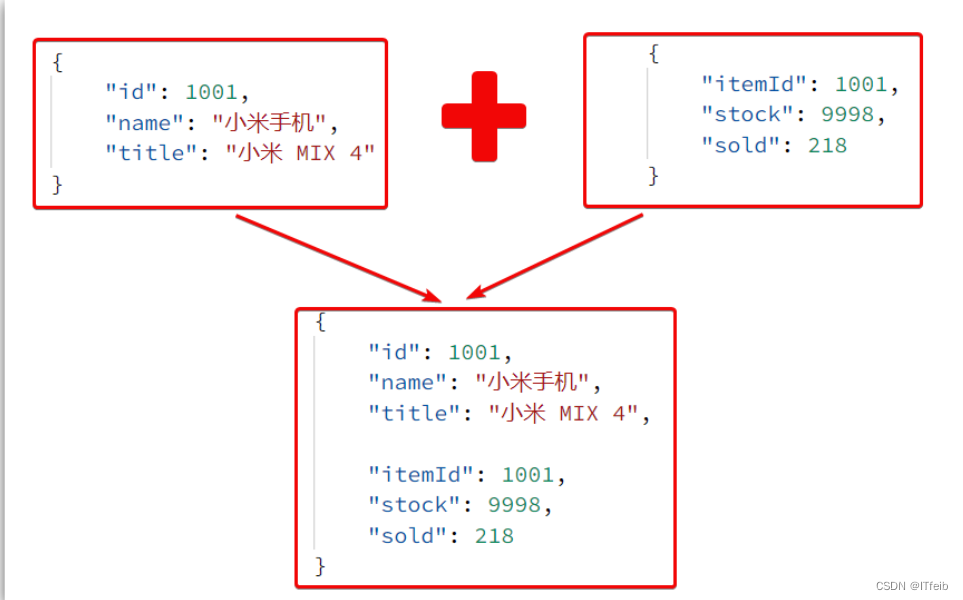
这就需要我们先把JSON变为lua的table,完成数据整合后,再转为JSON。
OpenResty提供了一个cjson的模块用来处理JSON的序列化和反序列化。
下面,我们修改之前的item.lua中的业务,添加json处理功能:
4.3 基于ID负载均衡
刚才的代码中,我们的tomcat是单机部署。而实际开发中,tomcat一定是集群模式:
因此,OpenResty需要对tomcat集群做负载均衡。
而默认的负载均衡规则是轮询模式,当我们查询/item/10001时:
- 第一次会访问8081端口的tomcat服务,在该服务内部就形成了JVM进程缓存
- 第二次会访问8082端口的tomcat服务,该服务内部没有JVM缓存(因为JVM缓存无法共享),会查询数据库
如果能让同一个商品,每次查询时都访问同一个tomcat服务,那么JVM缓存就一定能生效了。
也就是说,我们需要根据商品id做负载均衡,而不是轮询。
nginx根据请求路径做hash运算,把得到的数值对tomcat服务的数量取余,余数是几,就访问第几个服务,实现负载均衡。
实现:
修改/usr/local/openresty/nginx/conf/nginx.conf文件,实现基于ID做负载均衡。
首先,定义tomcat集群,并设置基于路径做负载均衡: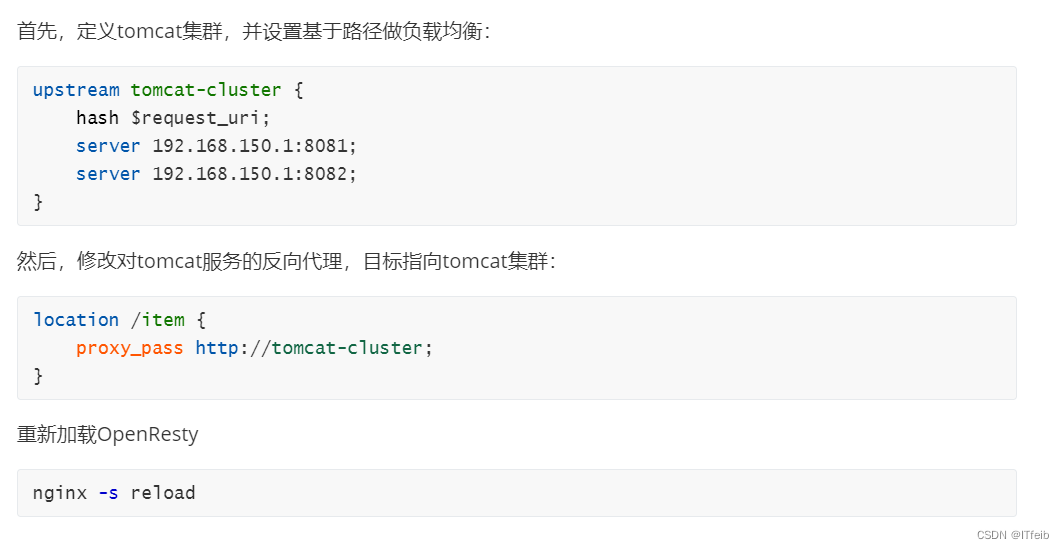
4.4 流程小结
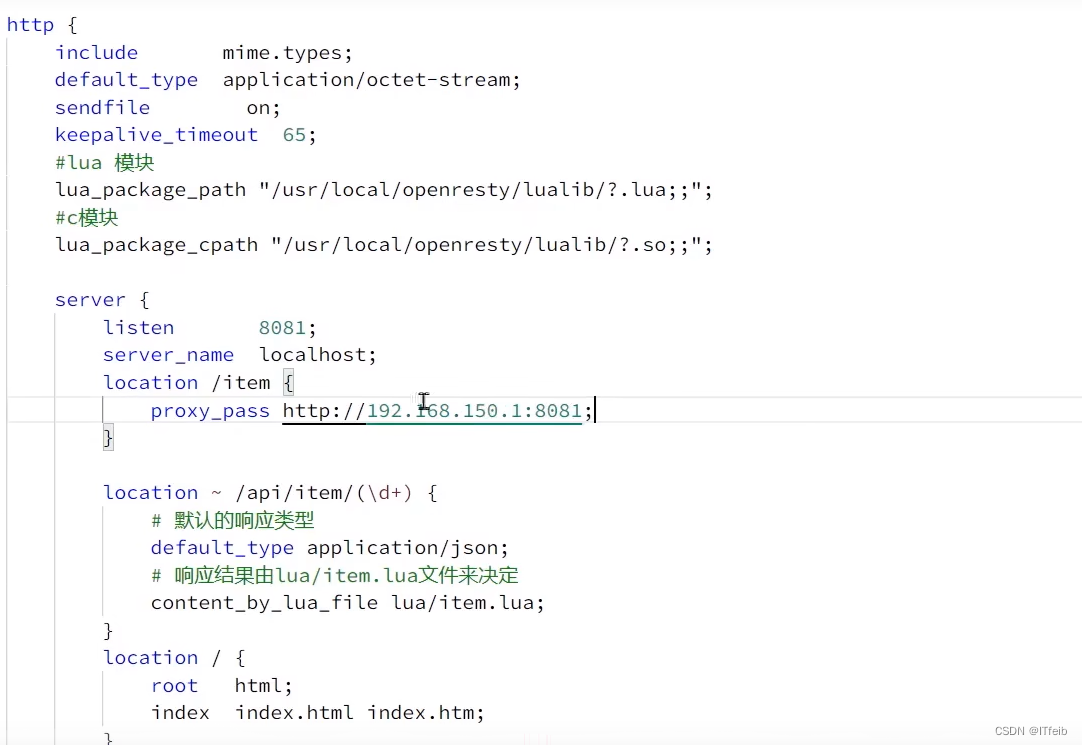
首先进来的localhost:80会由Nginx拦截代理到openresty,openresty会将路径为/api/item/(***)这样的路径解析出访问的商品id,之后通过将/item这样的路径代理发送到windows电脑中的Tomcat服务器查询,当tomcat中线程缓存有则返回,没有则去数据库查询。