目录
一、概述
二、国外Chiplet历史与现状
2.1 AMD
2.1.1 EPYC(Naples)
2.1.2 EPYC(Rome)
2.1.3 EPYC(Milan-X )
2.1.4 Ryzen(Matisse)
2.2 苹果
2.3 Intel
2.3.1 Altera Stratix 10 FPGA
2.3.2 Lakefield SoC
2.4 Xlinix
2.5 Marvell Mochi
2.6 HBM
三、国内Chiplet历史与现状
3.1 华为海思
3.1.1 Hi16xx和晟腾910
3.1.2 基于 Chiplet 技术的 7nm 鲲鹏 920 处理器
3.2 芯原股份
3.3 芯动科技
3.4 寒武纪
3.5 摩尔精英
一、概述
Chiplet模式将芯片的不同功能分区制作成裸芯片,再通过先进封装的形式以类似搭积木的方式实现组合,通过使用基于异构集成的高级封装技术,使得芯片可以绕过先进制程工艺,通过算力拓展来提高性能同时减少成本、缩短生产周期。
事实上,Chiplet并非是一个新的概念,其概念最早源于1970年代诞生的多芯片模组(MCM),即由多个同质或异质的较小芯片组成大芯片,也就是从原来设计在同一个SoC中的芯片,被分拆成许多不同的小芯片分开制造再加以封装或组装,故称此分拆之芯片为“小芯片”(Chiplet)。
- 2014年,华为海思与台积电合作的64位Arm架构服务器处理器Hi16xx,采用台积电异构CoWoS 3D IC封装工艺。
- 2015年,Marvell创始人周秀文博士在ISSCC 2015上提出MoChi(Modular Chip,模块化芯片)概念,这是Chiplet最早的雏形。近年来,这个概念开花结果,AMD、英特尔、台积电、英伟达等国际芯片巨头均开始纷纷入局Chiplet。同时,随着入局的企业越来越多,设计样本也越来越多,开发成本也开始下降,大大加速了Chiplet生态发展。
- 2017年AMD推出 EPYC系列采用Chiplet技术实现弯道超车intel。
- 苹果 2022 年 3 月发布的 M1 Ultra 芯片采用了独特的 UltraFusion 芯片架构,借助台积电的 CoWos-S 技术,通过两枚 M1 Max 晶粒的内部互连,实现了性能的飞跃。
但并不是所有芯片都适合使用Chiplet,不少情况下单颗集成的系统芯片会更有价值。相较之下,AI芯片对于芯片的设计规模要求最高,且需整合高频宽记忆体,高速I/O、高速网络等模组。Chiplet架构一般采用3D集成方案,减小了芯片面积,扩展了空间,是对AI芯片最佳、最具经济效益的设计。
Chiplet也非常适合汽车自动驾驶芯片。由于汽车自动驾驶芯片对于算力要求非常高,芯片的面积很大,成本很高,车规级的认证周期又很长,采用Chiplet设计,不仅可以降低设计难度、提升良率、降低设计和制造成本,更为关键的是还能够提供更高的安全性和快速迭代。
高性能服务器/数据中心、自动驾驶、笔记本/台式电脑、高端智能手机等将在未来几年成为Chiplet的主要应用场景,引领该市场增长。
二、国外Chiplet历史与现状
2.1 AMD
2.1.1 EPYC(Naples)
EPYC(Naples)是 EPYC 系列的第一代芯片产品,是针对企业服务器市场设计的,具有高性能、高可靠性和高能效的特。EPYC 是AMD 在服务器CPU 市场上的翻身帐开始,在发布会上,AMD 明晃晃的提出打破摩尔定律的限制,这个来自fab 的说法。
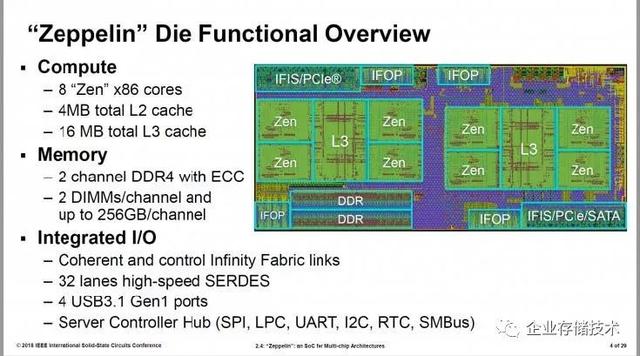
每个EPYC 处理包括4 个Zeppelin die,使用的还是2D 的 MCM (Multi-chip module)封装。
AMD 的革命性 the Infinity Fabric,不仅仅是die-to-die 的互联总线,还是processor-to-processor 的互联总线。从这里也可以看出来,cache coherent 互联总线设计,和CPU 的设计关系紧密,凡是 cache coherent 互联总线的标准背后都有家CPU的设计公司。
Zeppelin die 是Zen 架构的核心处理器模块,包含了处理器的内核、缓存和 I/O 功能。Zeppelin die 包含2 个CCX(Core Complex),每个CCX包含了四个 CPU 内核。1个Zeppelin die 做桌面产品,2个Zeppelin die 做高端桌面产品, 4 个Zeppelin die 就是服务器产品。
2.1.2 EPYC(Rome)
Rome 的设计,甚至比Naples 还难做决定。要提高IPC,要双倍性能,而且不能再一个die,同时兼顾服务器和PC 市场。AMD 试图在一个chiplet 上加倍核数(就是说要设计一个400+mm^2),然后保持4 个die 的设计,然而向现实妥协的结果是9个die 的设计。
而且从一个chiplet 上包含内存控制器,I/O 和Infinity 互联的接口, 转变为有一个中央集中式I/O 和内存控制器die,而且这个集中IOD 仍然有14nm 工艺,CCD 仍然保持8 个核的设计。8 个CCD die, 一个IOD,最高核数为64 个。
每个CCD 上的核数,可以根据良率变化,每个SKU 上的chiplet 数目也可以选择,因此真正最终产品的核数,有多种组合。
好消息是Rome 的下一代Milan 仍然是9 die 的设计,有点tock 的意思。而且I/O die 看起来变化不大,不知道是不是重用旧设计,仅仅升级工艺,但是Milan 的CCD 的设计有增强。这也是chiplet 设计的好处,不同的die 可以分离演进。服务器的IOD 和Client 的IOD 也演进为两个设计。
Rome 的CCD 的面积是74mm2,包括了3.9B 的transistors。对比Zepplin 的CCX面积大约是88mm2,2.8B 的transistors,感觉改进还是巨大的,7nm 的工艺进步也是显著的。Rome 的IOD 有125mm2。

EPYC(Naples)与 EPYC (Rome)

2.1.3 EPYC(Milan-X )
AMD 于 2021 年 6 月发布了基于 3D Chiplet 技术的 3D V-Cache,该技术使用的是台积电的 3D Fabric 先进封装技术,将包含 64MB L3Cache 的 Chiplet 以 3D 堆叠的形式与处理器进行了封装。2022 年 3 月 AMD 推出了 Milan-X 霄龙处理器,该处理器是基于 Milan 的第三代处理器 EPYC 7003 的升级版本,通 过使用 AMD 的 3D V-Cache 堆叠技术实现了 768 MB 的 L3 缓存。Milan-X 是一个包含 9 个小芯片的 MCM,其中包括 8 个 CCD 裸片和 1 个大型 I/O 裸片2.1.3
2.1.4 Ryzen(Matisse)
我这里并不想过多的分析Ryzen,只是想指出,Ryzen 产品线重用了 EYPC Rome 的CCD。只是单独配了一个Client IOD。
对于产品线复杂的公司,chiplet 设计,极好的降低了总研发费用。

2.2 苹果
2.2.1 采用台积电 CoWos-S 桥接工艺的 M1 Ultra 芯片
苹果 2022 年 3 月发布的 M1 Ultra 芯片采用了独特的 UltraFusion 芯片架构,借助台积电的 CoWos-S 技术,通过两枚 M1 Max 晶粒的内部互连,实现了性能的飞跃。M1 Ultra 在新架构下,晶体管数量达到 了 M1 的 7 倍多,同时两颗 Max 之间的互连频宽可达 2.5TB/s。M1 Ultra 内部集成内存 128GB,包含 8 个 16 层堆叠的 HBM(高带宽内存)堆栈的内存部件,核心传输速率达 3200M,实际传输带宽超过 800GB/s。这款产品实现了 Apple 芯片与 Mac 系列电脑的又一次重大飞跃,具有里程碑意义
2.3 Intel
Intel 真是一个复杂的公司,首先,它可不是fabless,它是唯一一家有fab 的半导体设计公司。真心想知道,它的这种超强商业模式,在这轮chiplet 浪潮中,会不会受影响呢。
前面有说, chiplet 是fab 主导开始的,解决最新工艺贵,且良率低,或者超大芯片到达物理极限的问题的。Intel 在fab 技术和制定业界标准上都强,EMIB, HBM 的3D 封装, AIB 的总线, Foveros,CXL 这些都是Intel 的出品。
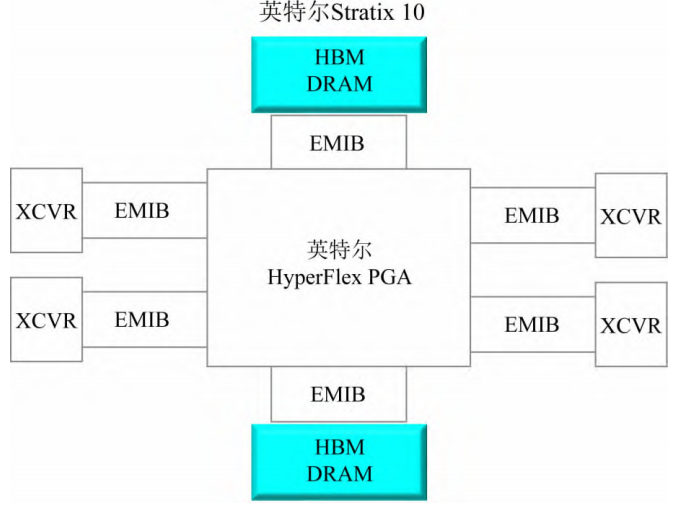
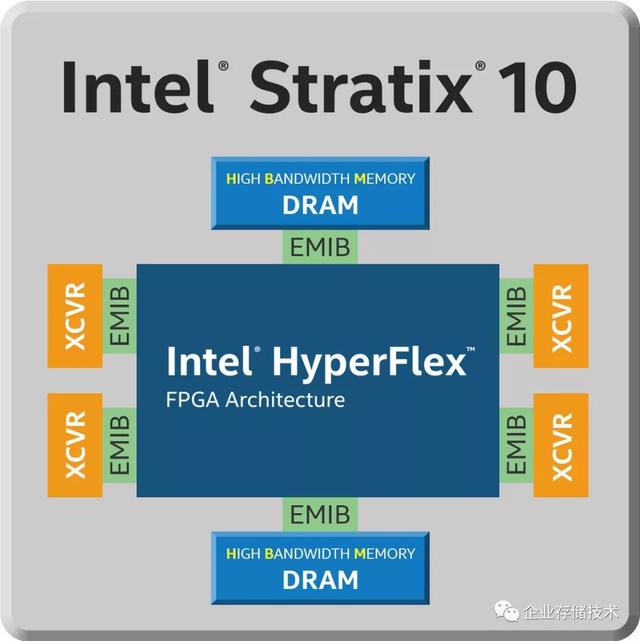
2.3.1 Altera Stratix 10 FPGA
Stratix 10 是Intel 第一款使用EMIB 的设计,中心是FPGA die,周围是6 个chiplet。4 个高速transceiver chiplet 和2 个高带宽memory chiplet。这6 个chiplet,是来自三个不同fab 的6 个不同工艺chiplet,用来证明不同fab 之间的强大互操作性。
2.3.2 Lakefield SoC
Stratix 10 是用的EMIB(2.5D 封装技术), Lakefield 亲孩子,就是用上了3D 封装,当然Intel 重新给它了一个名字Foveros。

Lakefield 有两个技术有趣点,一是不同核的big.little 混合架构,二是chiplet 设计,一个compute die,一个base die。Base die,主要是I/O 功能,性能不敏感,因此可以用22nm 工艺,而混合了大小CPU 核,IPU,GPU 的compute die,会持续演进,用7nm,5nm 工艺。
Big.Little 是一种处理器架构,用于提高设备的能效。它通过将较大的“大核”(也称为“性能核”)和较小的“小核”(也称为“能效核”)结合在一起,旨在在需要高性能时使用大核,而在需要较低功耗时使用小核。这种架构有助于提高设备的效率,因为它可以根据当前的工作负载动态地切换到不同的处理器核心,以更有效地使用能源。
2.4 Xlinix
Xilinx 是一家半导体公司,专门生产可编程逻辑器件(PLD),包括可编程逻辑门阵列(FPGA)和可编程序列器(CPLD)。Xilinx 的产品被广泛应用于电信、自动化、工业、消费电子和其他领域。
讲chiplet FPGA 公司必须有名字。FPGA 公司因其属性和高利润性,一直是各种先进工艺的率先使用者。而FPGA 一开始采用Chiplet 方案,就是为了打破fab 的物理限制,做超大芯片。
讲真,其实所有AISC(为特定应用而设计的专用集成电路) 的新应用领域,都是从FPGA 的设计开始的。2011 Virtex-7 2000T 就是4 个die 的chiplet 设计。Xilinx 号称提供业界唯一的同构和异构的3D IC。
Virtex系列的器件不仅代表着Xilinx的最高水准,往往也是整个FPGA业界最好的器件。这个系列的器件一般应用于高速联网(10G~100G)、便携雷达和ASIC原型验证等领域,这些领域的特点是对资源数量和性能要求高,但是对功耗和成本不怎么敏感。与Virtex-6 FPGA相比,Virtex-7系列的系统性能翻了一番、功耗降低一半、速度提升30%、其重点在于容量扩大2.5倍、多达200万个逻辑单元、串行宽带达1.9Tbps、线速高达28Gbps、其EasyPath降低成本解决方案,从而将这一业界最成功的 FPGA 架构推到了全新的高度。
2.5 Marvell Mochi
Marvell 提出Mochi 概念,最大的驱动力是降低成本,模块化芯片设计,像LEGO(一种拼装玩具) 那样,提高模块的重用性。借助基本模块的重用,还能在保持灵活性的同时,加快新产品的上市时间。

2015 年当时的Marvell CEO Sehat Sutardja 估计到2018 年开一个Mask 的价格是$10million (我也不知道这个价格,是不是对,知道的同志们,可以吱一声),因此要有25M 的出货量的产品,ROI 才合算。不知道大家对25M 这个数字是否有感觉,但是基本上,服务器(约12M),4G 基站(约7M),汽车(86M)这种市场就不用考虑最新工艺了。
- _M 是指芯片产品的出货量。芯片是微电子技术中用于执行特定功能的一种集成电路。芯片产品的出货量通常以百万个(M)为单位统计。因此,XXM 可能指百万个芯片的出货量。这些数字可以用来与其他产品的出货量进行比较,以及为评估市场需求、产品生产能力和 ROI 等方面提供参考。
- ROI 指的是投资回报率,即预期投资收益与实际投资成本之比。这意味着 Marvell 公司希望通过销售 25M 个产品来收回其在生产这些产品的成本。
Marvell 采用了Kandou Glasswing IP 作为die-to-die 的接口, 而Kandou 依然非常活跃在chiplet 的互联标准组织中。但是这个chiplet 互联标准,是一个新生态的核心标准,竞争者众多。
2.6 HBM
HBM 从设计开始就是3D 封装的,因此有些讨论chiplet 的文章,并不包括HBM。但是在我看来,凡是采取多die 封装的,都算是chiplet 的范畴。Memory die 也是chiplet,而且memory 公司卖Known good die 的历史蛮长。
2016 年 AMD Radeon R9 Fury X 是第一个采用HBM 的芯片。Nvidia 紧随其后。Fujitsu 的PostK supercomputer 设计,也采用了CPU die 与HBM 一起封装的设计,因此A64FX 芯片的管脚,要比一般的芯片精简不少。
三、国内Chiplet历史与现状
3.1 华为海思
3.1.1 Hi16xx和晟腾910
华为海思是一家中国的半导体公司,主要生产芯片和系统解决方案,它是国内最早尝试Chiplet的厂商之一。2014年,华为海思与台积电合作的64位Arm架构服务器处理器Hi16xx,采用台积电异构CoWoS 3D IC封装工艺,将16nm逻辑芯片与28nm I/O芯片集成在一起,实现了具有成本效益的系统解决方案,可以视为早期Chiplet实践。
海思因为其属性,公开消息并不多。往往是因为合作伙伴,需要展示自己的技术突破,海思才被迫营业,站台示众。这个海思1616 就是这样挂在TSMC 的网站上的。
晟腾910 的8 个chiplet 设计,融合了HBM die,逻辑部分与I/O 部分分离,两个dummy die,超大总die size 等特点。也算是业界标杆性设计。
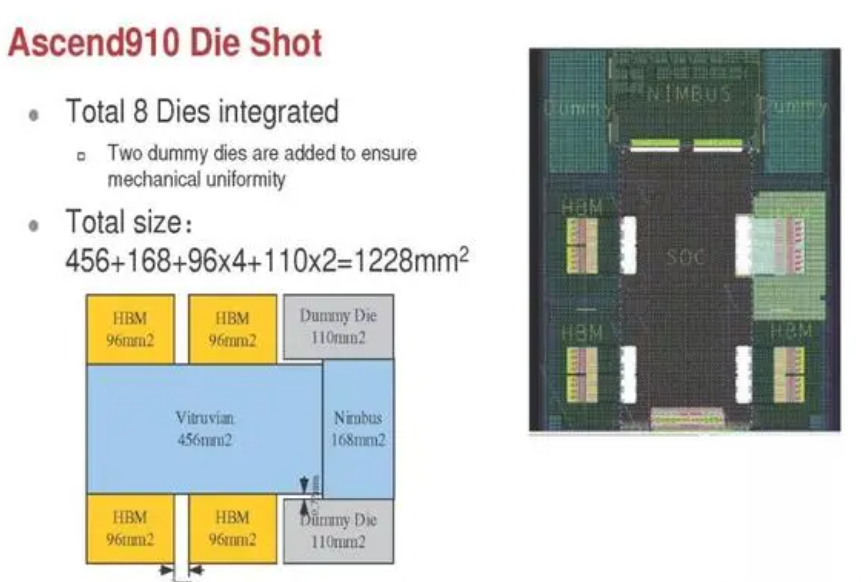
3.1.2 基于 Chiplet 技术的 7nm 鲲鹏 920 处理器
华为推出的鲲鹏 920 是业界领先的 ARM-based 处理器,该处理器采用 7nm 制造工艺,基于 ARM 架构 授权,由华为公司自主设计完成,通过优化分支预测算法、提升运算单元数量、改进内存子系统架构等 一系列微架构设计,大幅提高处理器性能。典型主频下,SPECint Benchmark 评分超过 930,超出业 界标杆 25%。同时,能效比优于业界标杆 30%。鲲鹏 920 以更低功耗为数据中心提供更强性能。该处 理器创建了相干缓存子系统以将多核集成到单个小芯片中,同时开发了专用并行小型 IO 块,以实现二 维封装解决方案的高带宽芯片间连接
3.2 芯原股份
除华为之外,国内其他诸多半导体公司也有了惊喜的进步。如芯原股份有望是业内首批推出商用Chiplet的公司,近年来一直致力于Chiplet技术和产业的推进。基于“IP芯片化,IP as a Chiplet”和“芯片平台化,Chiplet as a Platform”两大设计理念,芯原推出了基于Chiplet架构所设计的高端应用处理器平台,目前该平台12nm SoC版本已完成流片和验证,正在进行Chiplet版本的迭代。
3.3 芯动科技
在Chiplet领域已耕耘多年的芯动科技,推出的首款高性能服务器级显卡GPU“风华1号”就使用了Innolink Chiplet技术,将不同功能不同工艺制造的Chiplet进行模块化封装,成为一个异构集成芯片。Innolink是自主研发的Chiplet的标准通信协议,在摩尔定律趋近失效,先进工艺的成本高昂的市场状况下,开拓了新的技术路线,为高性能计算,5G,元宇宙,游戏,云服务等应用提供异构集成的基础连接技术。Innolink Chiplet具有自主知识产权,填补了国内的异构集成技术空白,打破了国外核心技术垄断,成功应用于国产GPU及其他高性能计算芯片,为国产高性能芯片的发展提供了一条新的道路。
2022年4月,芯动科技又率先推出国产自主研发物理层兼容UCIe标准的IP解决方案——Innolink™ Chiplet。据悉,这是国内首套跨工艺、跨封装的Chiplet(芯粒)连接解决方案,且已在先进工艺上量产验证成功。
3.4 寒武纪
寒武纪在2021年11月发布了其第三代云端AI芯片思元370,基于7nm制程并且是其首款基于Chiplet技术的AI芯片,在一颗芯片中封装2颗AI计算芯粒(MLU-Die),每一个MLU-Die具备独立的AI计算单元、内存、IO以及MLU-Fabric控制和接口,通过MLU-Fabric保证两个MLU-Die间的高速通讯,可以通过不同MLU-Die组合规格多样化的产品,实现不同算力、内存和编解码器的组合。
3.5 摩尔精英
摩尔精英也在探索建立一个SiP的平台,通过严选的SiP芯片、借力现有的KGD裸片过渡,统一芯片生产和品质控制,建立一站式Chiplet研发、生产、销售协作平台,从而能让更多的芯片企业享受到SiP设计和柔性生产的服务。
参考资料:
一文看懂Chiplet小芯片:AMD、英特尔、华为海思都在研究! (baidu.com)
Chiplet:概念的崛起、产业及相关公司梳理 来源:慧博关于“摩尔定律”即将走向终结的讨论越来越热烈,“后摩尔时代”似乎就要来了。那么一个问题随之而来: 在现有的工艺... - 雪球 (xueqiu.com)
Chiplet生逢其时,中国半导体企业如何借此破局?| 芯片行业观察|台积电|chiplet_网易订阅 (163.com)
分析丨Chiplet国内红火发展背后的冷思考|台积电|芯片|chiplet|半导体_网易订阅 (163.com)
Innolink Chiplet赋能国产高性能GPU - 知乎 (zhihu.com)