又带来了可扩展、可解释,从预训练语言模型中高效提取知识图谱的新框架
来自加州大学圣迭戈分校(UCSD)、卡内基梅隆大学(CMU)等机构的研究者提出了一种自动知识抽取框架,可以从 BERT 或 RoBerta 等预训练语言模型中高效且可扩展地提取知识图谱。

知识图谱 (KG) 是表示知识的一种形式,通常由头尾实体及其关系的三元组构成。它被广泛应用在各个领域,包括搜索引擎、推荐系统、聊天机器人和医疗保健。传统的知识图谱是通过昂贵的众包(例如 WordNet, ConceptNet, ATOMIC)构建的。尽管最近的研究探索了使用文本挖掘技术来自动构建知识图谱,但由于需要庞大的语料库和复杂的处理流水线,这仍然是一项具有挑战性的任务。此外,文本挖掘的一个不可避免的缺点是抽取的关系仅限于所选语料库所涵盖的关系。例如,许多常识性的知识并不会在人类语言中被显式地表达,因此从语料库中提取它们并不是一件容易的事。自动构建包含有“任何关系”的知识图谱仍然是一个未经探索的领域。
随着神经网络的发展,越来越多的神经网络模型在不同领域的任务上取得优异的表现,例如使用 GPT-3 和 ChatGPT 进行语言建模,以及使用 bioBERT 进行医学预测。在训练过程中,这些模型可以将从数据中学到的知识隐式地存储在它们的参数中。例如,在大规模医疗记录上训练的医学模型可能已经获得了丰富的医学知识,使其能够准确预测疾病。同样,流行病预测模型可能已经从训练数据中隐含地学到了某些传播模式。
最近的研究试图利用语言模型作为知识库 (Language model as knowledge base)。例如,使用手动或自动生成的提示(例如,“奥巴马出生于 __”)来查询语言模型获得答案(例如,“夏威夷”)。但是,语言模型的知识仅仅隐式编码于参数,使得这样的知识库缺乏了知识图谱的优良属性,例如对知识进行复杂查询或是更新。这就引出了一个问题:我们能否自动从语言模型中获取知识图谱,从而结合两者的优点,即语言模型的灵活性和可扩展性,以及知识图谱的易于查询、可编辑性和可解释性?
为实现这一目标,我们提出了一种自动知识抽取框架,能够从 BERT 或 RoBerta 等预训练语言模型中高效且可扩展地提取知识图谱,从而构建一系列新的知识图谱(例如 BertNet、RoBertaNet),相比于传统的知识图谱,能够支持更广泛和可扩展的关系和实体。
-
论文地址:https://arxiv.org/abs/2206.14268
-
项目地址:https://github.com/tanyuqian/knowledge-harvest-from-lms
-
demo地址:https://lmnet.io/
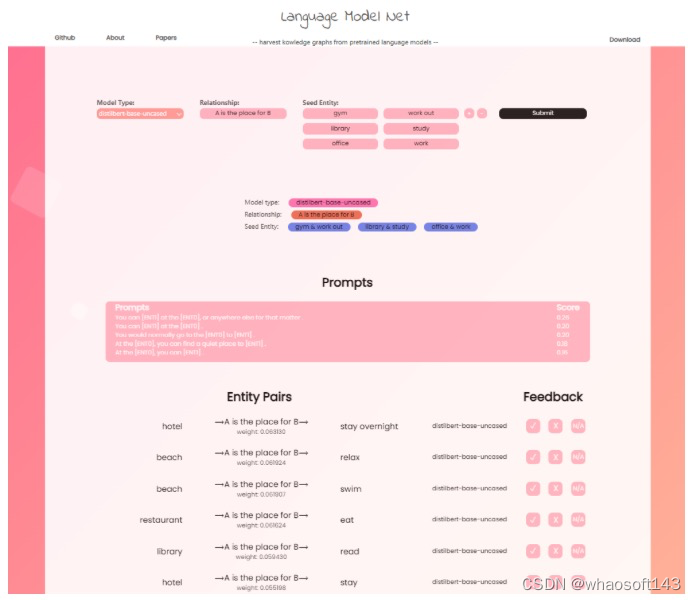
图1:项目demo的截图,用户可以自定义关系进行查询
从语言模型中获取知识图谱的框架
我们首先定义希望解决的问题:给定用户对于一个关系的描述,我们希望从语言模型中获取该关系的实体对。在我们的框架中,关系被描述为一个带有空槽的提示(prompt),并且通过一些示例实体 (seed entity tuple) 对进一步消除歧义。有了这些输入,我们的框架可以输出实体对列表以及它们对应的置信度(可参考图1中demo的效果)。
兼容性分数
在我们深入介绍抽取知识所需的两个主要阶段之前,我们先介绍提示和实体对之间的兼容性分数。
![]()
以 BERT 为例,评分函数中的第一项表示将实体对 (h, t) 填充到提示 p 中的空槽的预测概率。通常,这个联合条件概率是以自回归方式计算的。此外,我们还想确保每一步的概率不会太低,这就是对分数第二项的直观理解。一个具体的例子如图 2 所示,其中 p=”A is the place for B”,h=”library”,t=”study”。我们还介绍了如何处理 h=“study room” 的多单词 (multi-token) 实体。
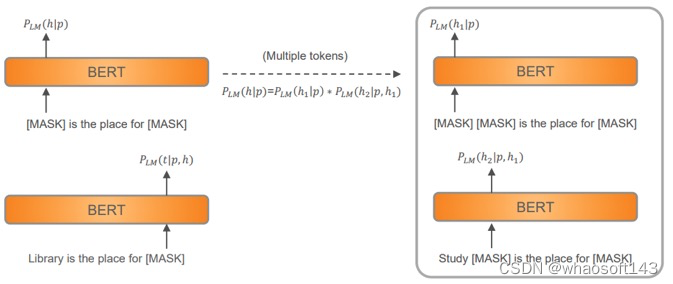
图2:兼容性分数的计算示例
有了这个兼容性分数,我们接下来介绍从语言模型中获取知识图谱的流程(图 3),它可以分为两个主要阶段:提示构建 和 实体对搜索。
第一阶段:提示构建
语言模型的一个已知的问题是它们对于提示非常敏感。有时,即使措辞上的细微差别也会导致预测结果发生巨大变化。为此,我们希望生成初始输入提示的多个同义改写,并使用它们来约束语言模型的输出。
在具体实现中,我们迭代地对实体元组和提示进行采样,拼装成一个语句并对其进行同义改写(具体来说,我们使用了GPT-3的API)。该过程如图2的左侧所示。生成的提示可能存在语义漂移,因此我们使用一个提示与所有示例实体对之间的平均兼容性分数进行加权,并且在所有提示中使用 softmax进一步归一化权重,这样我们就可以得到一个带有权重的提示集合,作为对一个关系更可靠的描述。
第二阶段:实体对搜索
我们在接下来这一阶段的目标是搜索实体对。搜出的实体对应该与加权提示集拥有较高的兼容性。
如果直接穷举搜索实体对,搜索空间将会过于庞大。作为一种近似的方法,我们在搜索实体对时只考虑最小单步概率(兼容性函数的左侧一项,简写为MLL)而不是完整的函数。这个近似的评分函数让我们可以在搜索时进行高效的剪枝。
作为一个例子:当我们想搜索100个实体对的时候,我们需要维护一个容量为100的最小堆,保存目前为止搜到的MLL最小的100个实体对。堆顶的元素可以作为接下来搜索的一个阈值,因为这是目前搜索到的第100大的MLL。在接下来的搜索中,一旦我们发现在任何一步的概率低于这个阈值,我们都能立刻放弃接下来的搜索,因为接下来搜到的实体的MLL都会小于这个值。如果直到完整搜索出一个实体对都没有被剪枝,我们就弹出堆顶的元素并且把新搜到的实体对的MLL推入堆。
一旦我们收集了足够数量的实体对,我们会用完整的一致性评分函数重新排序,并将其视为置信度。根据置信度,我们尝试使用不同的截断方法来获得最终的知识图谱:(1) 50%: 取搜出实体对置信度排名前一半的。(2)base-k: 对于不同的关系,有效的实体对数量应该是不同的。例如,对于“capital of”这个关系,正确的实体对不应该超过200个,因为全世界国家的数量只有这些。我们设计了一种针对关系的截断方法:取排名第k位的实体对的置信度,乘以百分之10,并且只保留置信度比这个数值更大的实体对。我们将这样获得的知识图谱加上base-k的下标。
抽取出的知识图谱
不同于传统的知识图谱,一旦接受到新的查询,BertNet就可以被扩展。本质上,BertNet的大小没有极限。为了评价我们的框架,我们将这个框架用于ConceptNet的关系集合,以及一个作者们创作的新颖关系集合(例如:capable but not good at),构建出相应的知识图谱。

表1:不同知识图谱的统计结果
仅仅使用语言模型作为知识的来源,并且不使用任何训练数据的情况下,我们的框架可以抽取出准确并且多样的知识(表中其他知识图谱构建方法和我们的设置不同,因此数值无法被直接比较)。通过选取不同的截断方法,我们还展示了RobertaNet的大小和准确率的权衡。
总结
在这项工作中,我们提出了一个从语言模型自动抽取知识图谱的框架。它可以处理任意用户输入的关系,并且以高效和可扩展的方式进行知识抽取。我们在两组关系上构建了知识图谱,证明了语言模型不加以外界资源就已经是一个非常有效的知识来源。我们的框架还可以作为对于语言模型的符号解释,为分析语言模型的知识储备提供了工具。 whaosoft aiot http://143ai.com