Python机器学习中的特征选择
- 特征选择方法
- 特征选择的Python库
- 使用Scikit-learn实现特征选择
- 方差
- 卡方检验
- ANOVA
- Lasso正则化
- 递归特征消除
- 使用Feature-engine进行特征选择
- 单变量特征选择
- 相关性
- Python 中的更多特性选择方法
- 参考资料
任何数据科学项目的一个重要步骤是选择最具预测性的变量。特征选择的方法有很多种。有些扩展性很好,但只考虑单独的特性,有些计算成本极高,因此只适用于相对较小的数据集,还有一些处于中间位置。
Python 中还有各种特征选择算法的实现,利用了开源库。在一篇文章中涵盖所有这些内容,几乎是不可能的。相反,在本博客中,将介绍用于特性选择的Python库,突出显示每个库中可用的选择方法,然后演示一些特性选择实现。
有关其他功能选择方法的教程和分步代码实现,请查看课程《机器学习中的特征选择》或书籍《Python机器学习的特征选择》。
course: 机器学习中的特征选择:https://www.trainindata.com/p/feature-selection-for-machine-learning
book: Python机器学习中的特征选择:https://leanpub.com/feature-selection-in-machine-learning/
那么如何在Python中特征选择吗?
在进入演示之前,首先简短地回顾一下特征选择和可以用来找到最佳特征子集的不同方法。
特征选择方法
在特征选择中,从数据集中选择一个特征子集来训练机器学习算法。特征选择技术不同于降维,因为它们不会改变变量的原始表示,而只是选择一组较小的特征。通过减少特征的数量,可以提高机器学习模型的性能(即,避免过度拟合) ,同时减少训练时间和创建更多可解释的机器学习模型。
传统的特征选择方法分为过滤法、包装法和嵌入法。

过滤法(Filter methods)基于特征的特性,选择最佳特征,忽略它们与机器学习模型的交互。他们对特征进行排名,然后选择排名靠前的特征。排名方法通常使用卡方(chi-square)、方差分析(ANOVA)、相关性(correlation)和互信息(mutual information)等统计检验。
包装法(Wrapper methods)围绕预测模型搜索最相关的特征。它们生成多个特征子集,然后根据分类器或回归模型评估它们的性能。所选特征是来自返回最佳性能模型的子集的特征。
嵌入法(Embedded methods)将选择过程“嵌入”到预测模型的训练中。决策树中的Lasso 和feature importance是嵌入式方法的经典例子。线性模型的系数也可以用来选择重要特征。
在数据预处理过程中,特征选择和特征工程被广泛应用于数据科学。那么我们如何在Python中做到这一点呢?
特征选择的Python库
有3个Python库包含特征选择模块:Scikit-learn、MLXtend和Feature-engine。
- Scikit-learn 包含过滤法、包装法和嵌入法的算法,包括递归特征消除。
- MLXend 包含用于实现正向、反向和穷举搜索的transformers。
- Feature-engine包含了基于机器学习模型性能的特征选择方法、特征重组以及支持分类变量的特征选择技术。
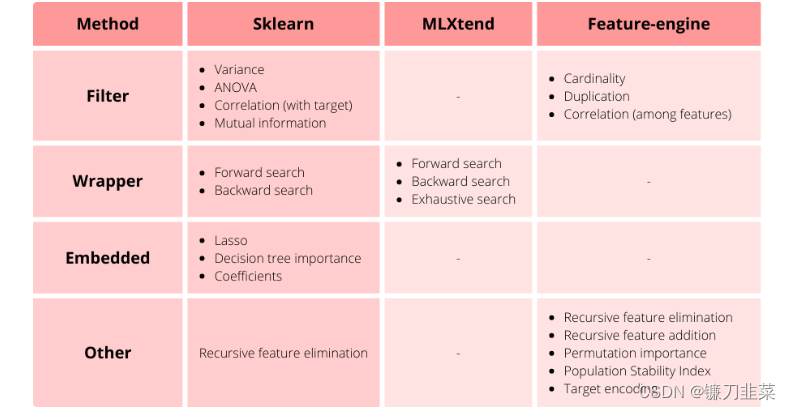
在本文中,我们将使用 Scikit-learn 和 Feature-engine 实现各种特征选择技术。
使用Scikit-learn实现特征选择
Scikit-learn 包含过滤法、包装法和嵌入法的算法,包括递归特征消除。在各种滤波方法中,我们可以利用特征的方差或基于方差分析来选择特征。我们来研究一下这些程序。
方差
通过Scikit-learn,可以通过观察特征的可变性(variability)来去除不相关的特征。标准差为零的特征是常数,可以删除。在这个示例中,我们将创建一个具有3个常量变量的玩具数据集,然后我们将使用 Scikit-learn 删除它们。
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.feature_selection import VarianceThreshold
# Toy dataset with redundant and constant features
X, y = make_classification(
n_samples=1000,
n_features=10,
n_classes=2,
random_state=10,
)
X = pd.DataFrame(X)
# Add constant features
X[[0, 5, 9]] = 1
# To remove constant features
sel = VarianceThreshold(threshold=0)
# fit finds the features with zero variance
X_t = sel.fit_transform(X)
X_t包含可变性大于0的预测因子。
卡方检验
当目标变量也是分类变量时,卡方检验适用于分类变量的选择。它根据检验返回的p值对特征进行排名,然后选择排名最高的特征。
注意Scikit-Learn的卡方功能没有执行预期的程序。这是一个已知的问题。而是使用scipy.stats.chi_contingency。
ANOVA
当目标变量为分类变量时,方差分析适用于连续变量的选择。探索如何使用ANOVA和Scikit-learn来选择特征。我们将使用乳腺癌数据集:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.feature_selection import SelectKBest
from sklearn.model_selection import train_test_split
# load dataset
breast_cancer = load_breast_cancer()
X = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
y = breast_cancer.target
# Separate data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# Rank and select features
sel = SelectKBest(score_func = f_classif, k=10).fit(X_train, y_train)
# remove features
X_train_t = sel.transform(X_train)
X_test_t = sel.transform(X_test)
使用SelectKBest,我们指定要选择的特性的数量。这是一个任意值,但可以通过交叉验证优化。
Lasso正则化
Lasso可以将线性模型的一些系数缩小到0,从而选择开箱即用的特征。在这里,将展示如何使用分类和回归数据集使用Lasso选择特征。
从导入库、函数和类开始:
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer, fetch_california_housing
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import Lasso, LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
接下来,从Scikit learn导入乳腺癌数据集,以预测肿瘤是良性还是恶性。这是一个分类数据集。接下来,我们将把数据分成训练集和测试集:
breast_cancer = load_breast_cancer()
X = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
y = breast_cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
从Scikit-Learn进行标准化:
scaler = StandardScaler()
scaler.fit(X_train)
接下来,选择使用Logistic回归作为分类器的特征,并使用LASSO正则化:
selector = SelectFromModel(
LogisticRegression(C=0.5, penalty='l1', solver='liblinear', random_state=10))
selector.fit(scaler.transform(X_train), y_train)
通过执行selector.get_support(),我们获得了具有非零系数的特征的布尔值矢量:
array([False, True, False, False, False, False, False, True, True,
False, True, False, False, False, False, True, False, False,
False, True, True, True, True, True, True, False, True,
True, True, False])
可以像下面这样确定要删除的一组特性的名称:
removed_feats = X_train.columns[(selector.estimator_.coef_ == 0).ravel().tolist()]
如果我们执行removed_feats,我们将获得以下数组,其中包含将被删除的功能:
Index(['mean radius', 'mean perimeter', 'mean area', 'mean smoothness',
'mean compactness', 'mean concavity', 'mean fractal dimension',
'texture error', 'perimeter error', 'area error', 'smoothness error',
'concavity error', 'concave points error', 'symmetry error',
'worst compactness', 'worst fractal dimension'],
dtype='object')
我们可以像下面这样从训练和测试集中移除这些特性:
X_train_selected = selector.transform(scaler.transform(X_train))
X_test_selected = selector.transform(scaler.transform(X_test))
如果我们现在执行x_train_selected.shape,x_test_selected.shape,我们将获得数据集的形状:((426,14),(143,14))。
继续并更改惩罚值©以查看结果是否更改。C的最佳值,也就是最佳特征子集,可以用交叉验证来确定。
递归特征消除
递归特征消除是一个连续的过程,在每次迭代之后去除一个特征,并且在每次消除之后重新评估特征的重要性。在 Scikit-learn 中,我们可以使用 RFE 或 RFECV 实现递归特征消除。
让我们使用随机森林的重要性递归地选择特征。我们将使用乳腺癌数据集,并将数据分为训练数据集和测试数据集。应仅根据训练数据选择特征。
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import RFE
from sklearn.model_selection import train_test_split
# load dataset
breast_cancer = load_breast_cancer()
X = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
y = breast_cancer.target
# Separate data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
clf = RandomForestClassifier(n_estimators=10, random_state=10)
sel_ = RFE(
clf,
n_features_to_select=8,
step=2,
)
sel_.fit(X_train, y_train)
X_train_selected = sel_.transform(X_train)
X_test_selected = sel_.transform(X_test)
结果由具有所选特征的 Numpy 数组组成。
使用Feature-engine进行特征选择
Feature-engine包含许多类,它们基于递归特征消除或添加、特征重组、种群稳定性指数、平均目标值、基数等方法来选择特征。查看 Feature-engine 的文档了解更多细节。
单变量特征选择
Feature-engine包括基于每个类别或箱的目标变量平均值和单个特征分类器或回归器性能度量的单变量特征选择方法。
在单特征模型性能中,针对每个特征训练机器学习模型,仅将该特征作为输入,并基于该模型性能对特征进行排序。
让我们根据使用交叉验证的单特征模型性能选择特征:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.tree import RandomForestClassifier
from feature_engine.selection import SelectBySingleFeaturePerformance
# load dataset
breast_cancer = load_breast_cancer()
X = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
y = breast_cancer.target
# Separate data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
sel = SelectBySingleFeaturePerformance(
estimator=RandomForestClassifier(random_state=10),
scoring='roc_auc',
cv=3,
threshold=None,
)
X_train_t = sel.fit_transform(X_train, y_train)
X_test_t = sel.transform(X_test)
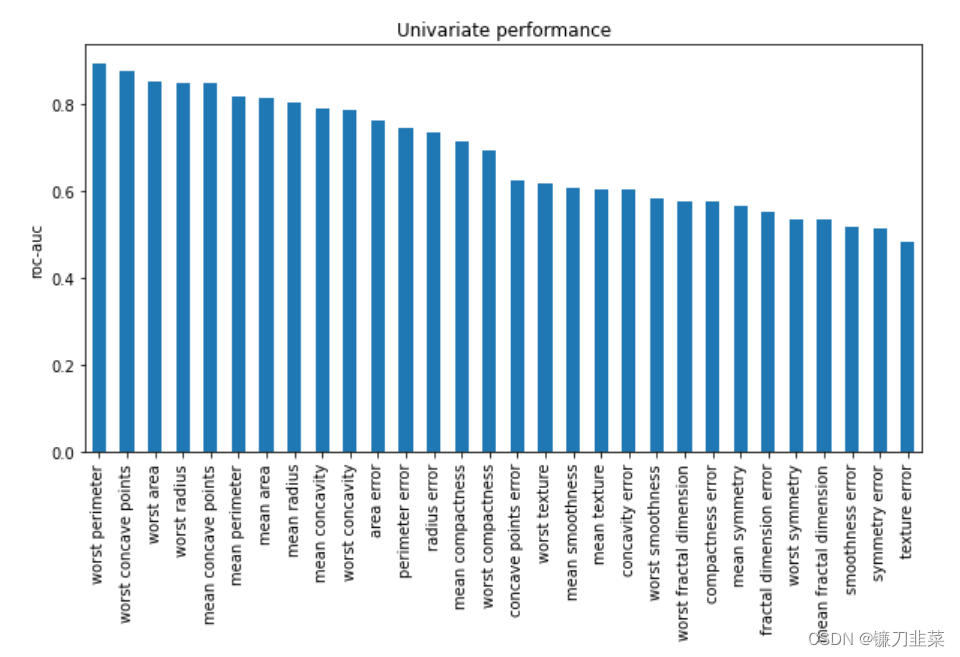
基于单个特征分类器,我们可以对特征进行可视化处理,探索特征的重要性:
pd.Series(sel.feature_performance_).sort_values(
ascending=False).plot.bar(figsize=(10, 5))
plt.ylabel('roc-auc')
plt.title('Univariate performance')
相关性
当训练线性或逻辑回归等线性模型时,多重共线性可能会影响模型性能。因此,删除相关特征可能很有用。
Feature-engine 包含基于特征相关性选择特征的算法。SmartCorrelationSelector 找到相关的特征组,然后保留缺少数据点较少、基数(cardinality )或可变性(variability)较高,或模型派生重要性较高的特征组。
如何找到相关的功能?我们可以使用pandas.corr方法。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme()
from sklearn.datasets import make_classification
# Toy dataset with correlated features
X, y = make_classification(
n_samples=1000,
n_features=10,
n_redundant=7,
n_classes=2,
random_state=10,
)
X = pd.DataFrame(X)
# the default correlation method of pandas.corr is pearson
corrmat = X_train.corr(method='pearson')
# we can make a heatmap with seaborn
sns.heatmap(corrmat, annot=True)
plt.show()

Python 中的更多特性选择方法
- course: Feature Selection for Machine Learning
- book: Feature Selection in Machine Learning with Python
参考资料
[1] Feature selection in machine learning with Python