Pytorch单机多卡分布式训练
数据并行:
DP和DDP
这两个都是pytorch下实现多GPU训练的库,DP是pytorch以前实现的库,现在官方更推荐使用DDP,即使是单机训练也比DP快。
-
DataParallel(DP)
- 只支持单进程多线程,单一机器上进行训练。
- 模型训练开始的时候,先把模型复制到四个GPU上面,然后把数据分配给四个GPU进行前向传播,前向传播之后再汇总到卡0上面,然后在卡0上进行反向传播,参数更新,再将更新好的模型复制到其他几张卡上。

-
DistributedDataParallel(DDP)
-
支持多线程多进程,单一或者多个机器上进行训练。通常DDP比DP要快。
-
先把模型载入到四张卡上,每个GPU上都分配一些小批量的数据,再进行前向传播,反向传播,计算完梯度之后再把所有卡上的梯度汇聚到卡0上面,卡0算完梯度的平均值之后广播给所有的卡,所有的卡更新自己的模型,这样传输的数据量会少很多。
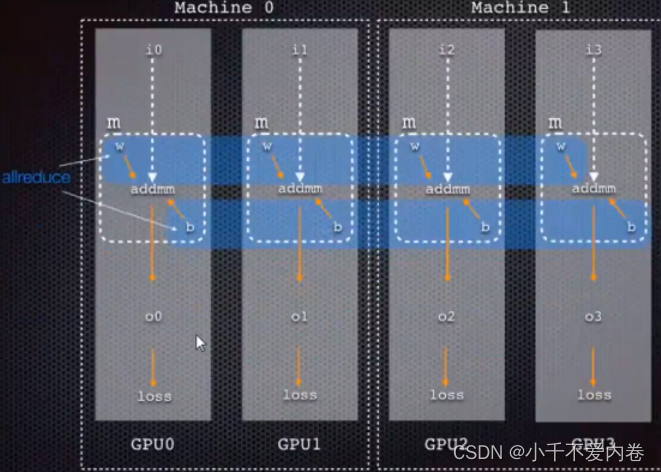
-
DDP代码写法
-
初始化
import torch.distributed as dist import torch.utils.data.distributed # 进行初始化,backend表示通信方式,可选择的有nccl(英伟达的GPU2GPU的通信库,适用于具有英伟达GPU的分布式训练)、gloo(基于tcp/ip的后端,可在不同机器之间进行通信,通常适用于不具备英伟达GPU的环境)、mpi(适用于支持mpi集群的环境) # init_method: 告知每个进程如何发现彼此,默认使用env:// dist.init_process_group(backend='nccl', init_method="env://") -
设置device
device = torch.device(f'cuda:{args.local_rank}') # 设置device,local_rank表示当前机器的进程号,该方式为每个显卡一个进程 torch.cuda.set_device(device) # 设定device -
创建dataloader之前要加一个sampler
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))]) data_set = torchvision.datasets.MNIST("./", train=True, transform=trans, target_transform=None, download=True) train_sampler = torch.utils.data.distributed.DistributedSampler(data_set) # 加一个sampler data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=256, sampler=train_sampler) -
torch.nn.parallel.DistributedDataParallel包裹模型(先to(device)再包裹模型)
net = torchvision.models.resnet101(num_classes=10) net.conv1 = torch.nn.Conv2d(1, 64, (7, 7), (2, 2), (3, 3), bias=False) net = net.to(device) net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[device], output_device=[device]) # 包裹模型 -
真正训练之前要set_epoch(),否则将不会shuffer数据
for epoch in range(10): train_sampler.set_epoch(epoch) # set_epoch for step, data in enumerate(data_loader_train): images, labels = data images, labels = images.to(device), labels.to(device) opt.zero_grad() outputs = net(images) loss = criterion(outputs, labels) loss.backward() opt.step() if step % 10 == 0: print("loss: {}".format(loss.item())) -
模型保存
if args.local_rank == 0: # local_rank为0表示master进程 torch.save(net, "my_net.pth") -
运行
if __name__ == "__main__": parser = argparse.ArgumentParser() # local_rank参数是必须的,运行的时候不必自己指定,DDP会自行提供 parser.add_argument("--local_rank", type=int, default=0) args = parser.parse_args() main(args) -
运行命令
python -m torch.distributed.launch --nproc_per_node=2 多卡训练.py # --nproc_per_node=2表示当前机器上有两个GPU可以使用
完整代码
import os
import argparse
import torch
import torchvision
import torch.distributed as dist
import torch.utils.data.distributed
from torchvision import transforms
from torch.multiprocessing import Process
def main(args):
# nccl: 后端基于NVIDIA的GPU-to-GPU通信库,适用于具有NVIDIA GPU的分布式训练
# gloo: 后端是一个基于TCP/IP的后端,可在不同机器之间进行通信,通常适用于不具备NVIDIA GPU的环境。
# mpi: 后端使用MPI实现,适用于具备MPI支持的集群环境。
# init_method: 告知每个进程如何发现彼此,如何使用通信后端初始化和验证进程组。 默认情况下,如果未指定 init_method,PyTorch 将使用环境变量初始化方法 (env://)。
dist.init_process_group(backend='nccl', init_method="env://") # nccl比较推荐
device = torch.device(f'cuda:{args.local_rank}')
torch.cuda.set_device(device)
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.MNIST("./", train=True, transform=trans, target_transform=None, download=True)
train_sampler = torch.utils.data.distributed.DistributedSampler(data_set)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=256, sampler=train_sampler)
net = torchvision.models.resnet101(num_classes=10)
net.conv1 = torch.nn.Conv2d(1, 64, (7, 7), (2, 2), (3, 3), bias=False)
net = net.to(device)
net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[device], output_device=[device])
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(params=net.parameters(), lr=0.001)
for epoch in range(10):
train_sampler.set_epoch(epoch)
for step, data in enumerate(data_loader_train):
images, labels = data
images, labels = images.to(device), labels.to(device)
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
if step % 10 == 0:
print("loss: {}".format(loss.item()))
if args.local_rank == 0:
torch.save(net, "my_net.pth")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# must parse the command-line argument: ``--local_rank=LOCAL_PROCESS_RANK``, which will be provided by DDP
parser.add_argument("--local_rank", type=int, default=0)
args = parser.parse_args()
main(args)
参考:
https://zhuanlan.zhihu.com/p/594046884
https://zhuanlan.zhihu.com/p/358974461








![[异构图-论文阅读]Heterogeneous Graph Transformer](https://img-blog.csdnimg.cn/e8c4750d1ade4944b74a82cb7a93be59.png)