文章目录
- 一.PASCAL数据集简介
- 1.图像分割
一.PASCAL数据集简介
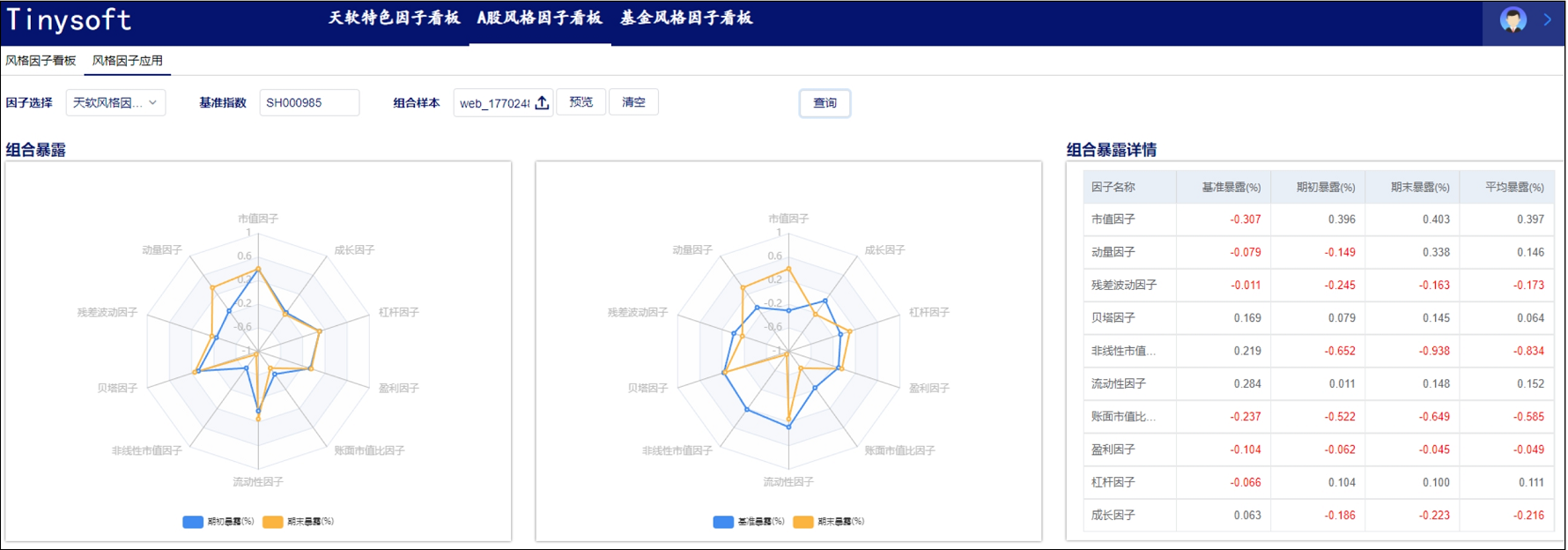
Pascal VOC2012数据集主要是针对视觉任务中监督学习提供标签数据,它有四个大类别,可以细分为二十个小类别:
- Person:person
- Animal:bird, cat, cow, dog, horse, sheep
- Vehicle:aeroplane, bicycle, boat, bus, car, motorbike, train
- Indoor:bottle, chair, dining table, potted plant, sofa, tv/monitor
主要有四个大类别,分别是人、常见动物、交通车辆、室内家具用品。主要为图像分类、对象检测识别、图像分割三类任务服务。
1.图像分割
图像分割:对每个对象与类别生成像素级别的分割标签,确定像素是为目标20个分类或者背景。

Pascal VOC2012的文件结构如下:

- Annotations:里面是图像对应的XML标注信息描述,每张图像有一个与之对应同名的描述XML文件,XML前面部分声明图像数据来源,大小等元信息
- ImageSets: 里面是标注类别的每个文件列表信息
- Action:是所有具有Action标注信息图像文件名的txt文件列表
- Layout:中的txt文件表示包含Layout标注信息的图像文件名列表
- Main:文件夹中包含20个类别每个类别一个txt文件,每个txt文件都是包含该类别的图像文件名称列表
- Segmentation:则是包含语义分割信息图像文件的列表
- JPEGImages: 所有的原始图像文件,格式必须是JPG格式,这个要特别注意!如果你打算使用VOC2012格式生成数据,那么原始图像格式在采样时候请用JPG格式保存,避免后期生成使用tensorflow工具生成的时候出错。
- SegmentationClass: 所有分割的图像标注,分割图像安装每个类别标注的数据
- SegmentationObject: 所有分割的图像标注,分割图像安装每个类别每个对象不同标注的数据
ImageSets中的main中针对每个类别都有三个文件夹,分别为:
- CLASSNAME_train.txt
- CLASSNAME_trainval.txt
- CLASSNAME_val.txt
以CLASSNAME = aeroplane为例,main中的三个文件分别为:
- aeroplane_train.txt
- aeroplane_trainval.txt
- aeroplane_val.txt
每个类别txt文件里面的内容格式为:图像文件名 + 空格 + 标记,以aeroplane_train.txt中的举例如下:
- 2008_000290 0
- 2008_000291 1
- 2008_000297 -1
其中2008_000290、2008_000291、2008_000297表示三张图像文件名
- 0 表示图像中包含aeroplane对象但是难识别样本
- 1 表示图像中包含aeroplane
- -1 表示图像中不包含aeroplane
<?xml version="1.0" encoding="utf-8"?>
<annotation>
<folder>VOC2007</folder>
<filename>test100.mp4_3380.jpeg</filename>
<size>
<width>1280</width>
<height>720</height>
<depth>3</depth>
</size>
<object>
<name>gemfield</name>
<bndbox>
<xmin>549</xmin>
<xmax>715</xmax>
<ymin>257</ymin>
<ymax>289</ymax>
</bndbox>
<truncated>0</truncated>
<difficult>0</difficult>
</object>
<object>
<name>civilnet</name>
<bndbox>
<xmin>842</xmin>
<xmax>1009</xmax>
<ymin>138</ymin>
<ymax>171</ymax>
</bndbox>
<truncated>0</truncated>
<difficult>0</difficult>
</object>
<segmented>0</segmented>
</annotation>
在这个xml例子中:
- bndbox是一个轴对齐的矩形,它框住的是目标在照片中的可见部分;
- truncated表明这个目标因为各种原因没有被框完整(被截断了),比如说一辆车有一部分在画面外;occluded是说一个目标的重要部分被遮挡了(不管是被背景的什么东西,还是被另一个待检测目标遮挡);
- difficult表明这个待检测目标很难识别,有可能是虽然视觉上很清楚,但是没有上下文的话还是很难确认它属于哪个分类;标为difficult的目标在测试成绩的评估中一般会被忽略。