线性表即“把所有数据按照顺序(线性)的存储结构方式,存储在物理空间”。
线性表又分为
- 顺序表
- 链表
- 单向链表
- 双向链表
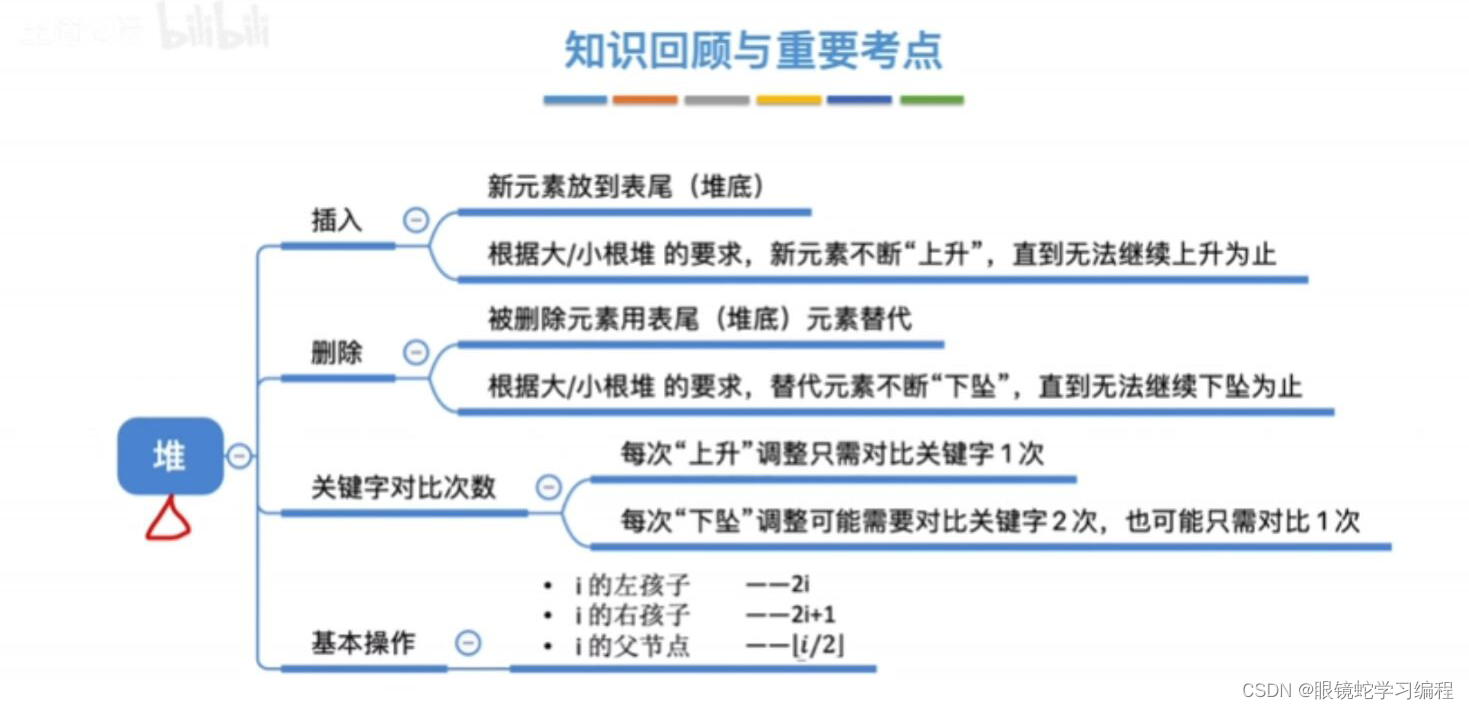
一、顺序表
数据依次存储在连续的物理空间中,就比如数组。
顺序表存储数据时,会提前申请一整块足够大小的内存,然后将数据依次存储起来,元素的存储空间在内存中是连续存在的。
顺序表的优点:
- 内存地址连续,数组元素进行遍历时,速度快。
- 根据下标,查找指定位置的元素时,速度快。(时间复杂度为 O(1) )
顺序表的缺点:
- 长度固定,使用前需要预估长度。
- 插入删除元素时,时间复杂度相对较高。(时间复杂度为 O(n) )
二、链表
与顺序表不同,链表不限制数据的物理存储位置,使用链表存储的数据元素,其物理存储位置是随机的。
链表中每个数据的存储都由以下两部分组成:

- 数据元素本身,其所在的区域称为数据域;
- 指向直接后继元素的指针,所在的区域称为指针域
链表的优点:
- 使用链表结构,不需要提前预估长度,可以克服数组需要预先知道数据长度的缺点
- 链表使用不连续的内存空间,可以充分利用计算机内存空间,实现灵活的内存动态管理
链表的缺点:
- 链表相比于数组会占用更多的空间,因为链表中每个节点中,除了存放元素本身,还有存放指向其他节点的指针
- 不能随机读取元素(
RandomAccess) - 遍历和查找元素的速度比较慢
链表又分为:
- 单向链表
- 双向链表
- 循环链表
- 双向循环链表
(1)单向链表
1、单向链表的节点定义
//单向链表的节点定义
static class Node<E>{
E item;//元素值
Node<E> next;//后继节点(指针域)
public Node(E data){
this.item=data;
}
}2、链表的遍历
// 链表的遍历
@Override
public String toString() {
StringJoiner sj=new StringJoiner("->");
//从首元素开始遍历
for(Node<E> n=first;n!=null;n=n.next) {
sj.add(n.item.toString());
}
return sj.toString();
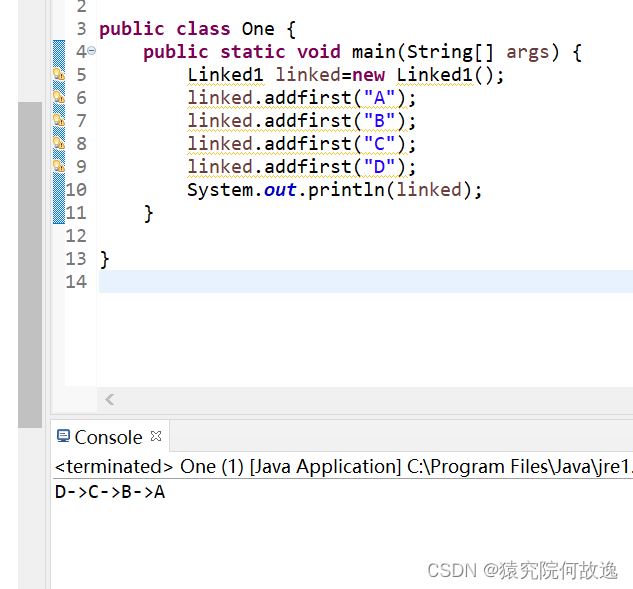
}3、头插法
其主要思想为在原链表的头部添加一个新元素,我们只需要创建出一个新元素,然后让这个新元素的后继节点指向原来的头结点。
public class Linked<E>{
//头节点
Node<E> first;
//尾节点
Node<E> last;
//添加新元素(头插法)
public void addfirst(E item){
final Node<E> newfirst=new Node<E>(item);//创建出新的头节点
final Node<E> f=first;//将原来的头节点存储起来
first=newfirst;//将新创建的新的节点赋给头节点
if(f==null) {
last=newfirst;//如果这个链表为空时,它的头节点和尾节点都为所要添加的这个新节点
}else {
newfirst.next=f;//如果链表不为空,则新节点的后继节点指向原来的头节点
}
}
}
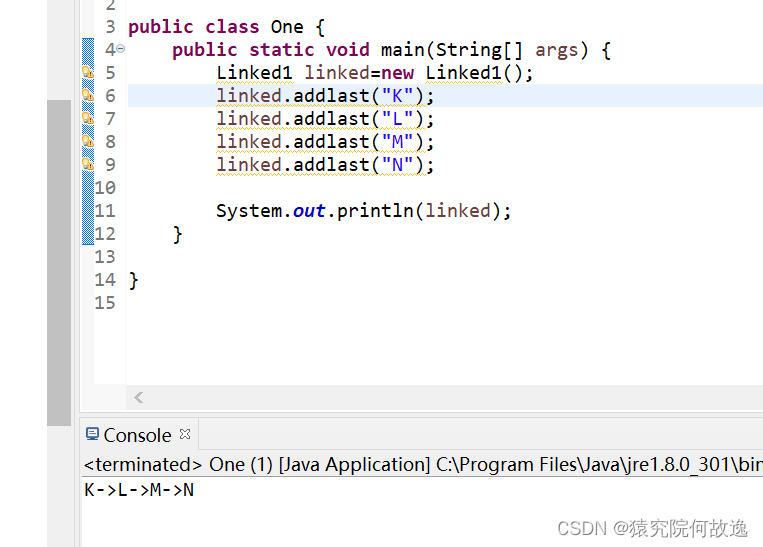
4、尾插法
其主要思想是在原链表的尾部添加一个节点,使得原来的尾节点的后继节点指向新添加的这个新节点
// 尾插法
public void addlast(E item) {
final Node<E> newlast=new Node<E>(item);
final Node<E> l=last;//将原来的尾节点存储起来
last=newlast;//将创建的新的节点赋给尾节点
if(l==null) {
first=newlast;
}else {
l.next=newlast;//如果链表不为空,则原尾结点的后继节点指向新节点
}
}
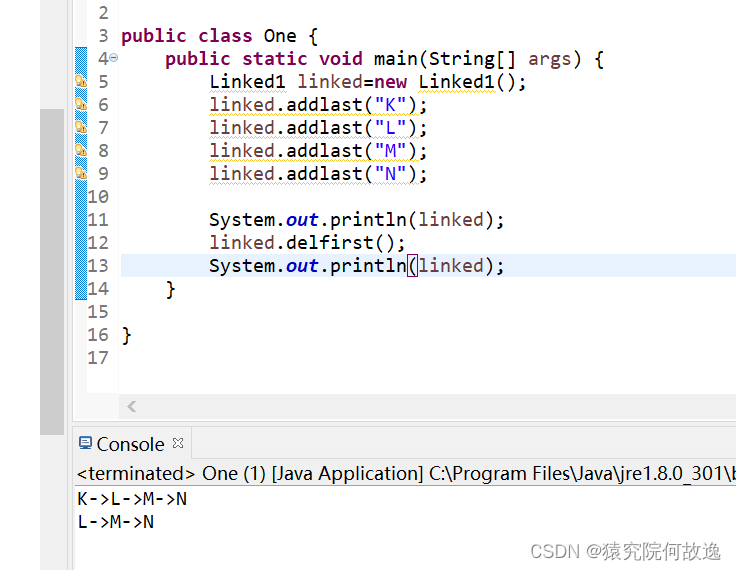
5、删除头结点
其主要思想是删除旧的头节点,再将旧的头节点的后继节点作为新的头节点
// 删除头结点
public void delfirst() {
final Node<E> f=first;//先保存头节点
final Node<E> next=f.next;//拿到头节点的后继节点
f.item=null;//删除旧的头节点
f.next=null;
first=next;//设置新的头节点
if(next==null) {
//单向链表为空,则尾结点为null
last=null;
}
}
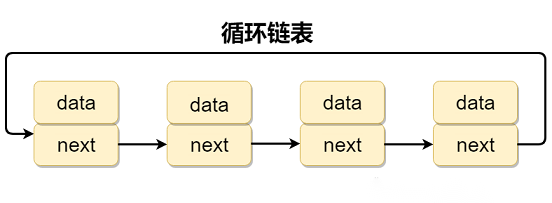
(2)循环链表
循环链表 其实是一种特殊的单链表,和单链表不同的是循环链表的尾结点不是指向
null,而是指向链表的头结点。
(3) 双向链表
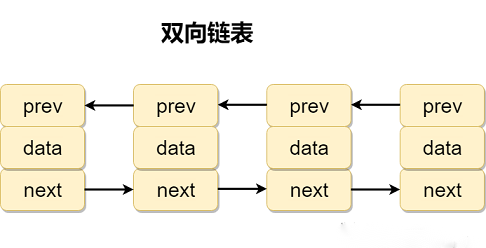
1、双向链表的节点类
static class Node<E>{
E item;//数据域
Node<E> prev;//前驱节点
Node<E> next;//后继节点
// 构造方法
public Node(E element,Node<E> prev,Node<E> next) {
this.item=element;
this.next=next;
this.prev=prev;
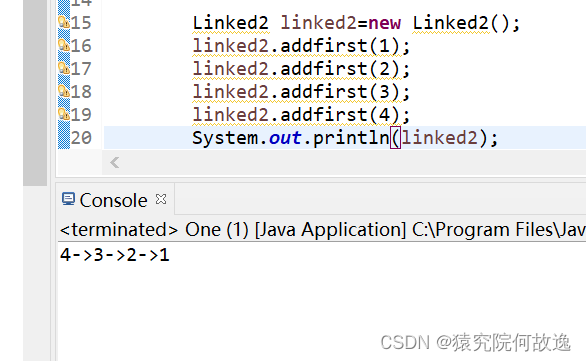
}2、双向链表的头插法
双向链表在头插法时,其新加入的节点的前驱节点指向null,后继节点指向原来的头节点
Node<E> first;
Node<E> last;
int size=0;
public void addfirst(E item) {
final Node<E> f=first;
final Node<E> newfirst=new Node<E>(item,null,f);
first=newfirst;
if(f==null) {
last=newfirst;
}else {
newfirst.next=f;
}
size++;
}
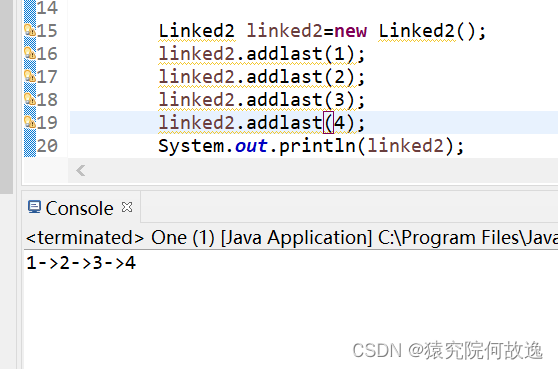
3、双向链表的尾插法
双向链表的尾插法,其新加入的节点前驱节点指向原尾结点,后继节点指向null
public void addlast(E item) {
final Node<E> l=last;
final Node<E> newlast=new Node<E>(item,l,null);
last=newlast;
if(l==null) {
first=newlast;
}else {
l.next=newlast;
}
size++;
}
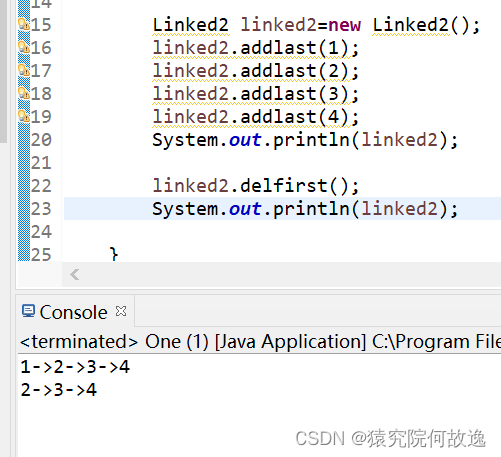
4、删除头节点
// 删除链表头节点
public void removeFirst() {
// 获取头结点
final Node<E> f = first;
// 获取头结点的下一个节点
final Node<E> next = f.next;
// 清空头结点
f.item = null;
f.next = null; // help GC
// 设置链表的头结点
first = next;
if (next == null)
last = null;
else
next.prev = null;
// 链表长度自减
size--;
}
5、 删除尾结点
// 删除链表尾节点
public void removeLast() {
// 获取尾节点
final Node<E> l = last;
// 获取尾节点的“上一个元素”
final Node<E> prev = l.prev;
// 清空尾节点
l.item = null;
l.prev = null; // help GC
// 设置链表的尾节点
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
// 链表长度自减
size--;
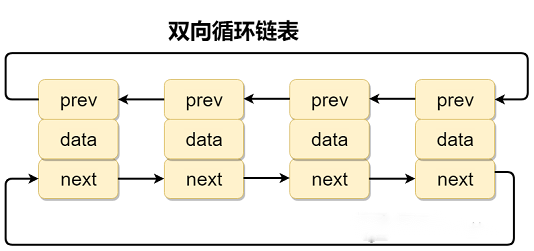
}(4)双向循环链表
双向循环链表 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。