文章目录
- 方法概述
-
- 漏洞挖掘方法分类
-
- 静态分析技术
- 动态分析技术
- 符号执行
-
- 符号执行的基本原理
- 符号执行的应用
- 漏洞挖掘-检测是否数组越界
- 污点分析
-
- 基本思想
- 污点分析核心要素
- 优缺点
- 词法分析
-
- 基本概念
- 漏洞挖掘实战
-
- 实践一:基于词法分析和逆向分析的可执行代码静态检测
- 实验一:基于IDA Pro分析给定的可执行文件是否存在溢出漏洞
-
- 第一步:通过IDA打开所生成的exe文件
- 第二步:定位敏感函数
- 实验二:使用Bugscam脚本来代替手工过程完成漏洞挖掘
- 数据流分析
-
- 基本概念
- 数据流分析方法分类
- 程序代码模型
- 基于数据流的漏洞分析流程
-
- 示例一:检测指针变量的错误使用
- 示例二:检测缓冲区溢出
- 模糊测试
-
- 基本概念
- 模糊测试分类
-
- 基于生成的模糊测试
- 基于变异的迷糊测试
- 模糊测试步骤
- 智能模糊测试
-
- 智能模糊测试具体的实现步骤
- 智能模糊测试的核心思想
- 模糊测试实践
-
- 使用工具
- 自己动手写Fuzzer
- AFL模糊测试框架
-
- AFL模糊测试框架
- AFL工作流程
- AFL安装
- AFL模糊测试
-
- 创建本次实验的程序
- 创建测试用例
- 启动模糊测试
- 分析crash
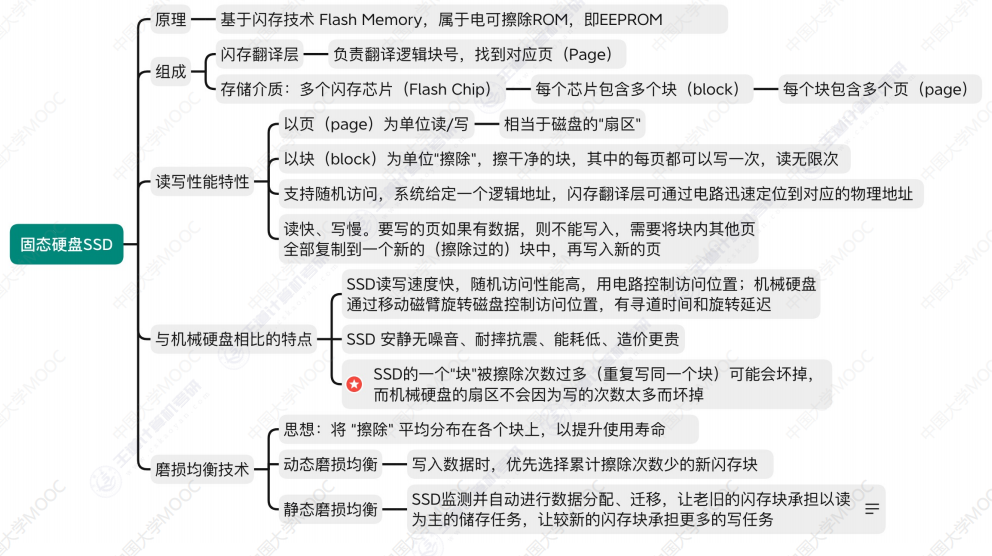
方法概述
漏洞挖掘方法分类
静态分析技术
方法:词法分析、数据流分析、控制流分析、模型检查、定理证明、符号执行、污点传播分析等。
不需要运行程序、分析效率高、资源消耗低
动态分析技术
方法:模糊测试、动态污点分析、动态符号执行等
需要运行程序、准确率非常高、误报率很低
符号执行和污点分析两类技术都分别支持静态分析和动态分析
符号执行
符号执行(Symbolic Execution)的基本思路是使用符号值替代具体值,模拟程序的执行。在模拟程序运行的过程中,符号执行引擎会收集程序中的语义信息,探索程序中的可达路径、分析程序中隐藏的错误。
动态符号执行结合了真实执行和传统符号执行技术的优点,在真实执行的过程中同时进行符号执行,可以在保证测试精度的前提下提升了执行效率。
符号执行的基本原理
符号执行三个关键点是变量符号化、程序执行模拟和约束求解。
变量符号化是指用一个符号值表示程序中的变量,所有与被符号化的变量相关的变量取值都会用符号值或符号值的表达式表示。
程序执行模拟最重要的是运算语句和分支语句的模拟:
- 对于运算语句,由于符号执行使用符号值替代具体值,所以无法直接计算得到一个明确的结果,需要使用符号表达式的方式表示变量的值。
- 对于分支语句,每当遇到分支语句,原先的一条路径就会分裂成多条路径,符号执行会记录每条分支路径的约束条件。最终,通过采用合适的路径遍历方法,符号执行可以收集到所有执行路径的约束条件表达式。
约束求解主要负责路径可达性进行判定及测试输入生成的工作。对一条路径的约束表达式,可以采用约束求解器进行求解:
- 如有解,该路径是可达的,可以得到到达该路径的输入
- 如无解,该路径是不可达的,也无法生成到达该路径的输入
符号执行有代价小、效率高的优点,然而由于程序执行的可能路径随着程序规模的增大呈指数级增长,从而导致符号执行技术在分析输入和输出之间关系时,存在一个路径状态空间的路径爆炸问题。由于符号执行技术进行路径敏感的遍历式检测,当程序执行路径的数量超过约束求解工具的求解能力时,符号执行技术将难以分析。
符号执行的应用
符号执行已经广泛应用在软件测试、漏洞挖掘和软件破解等。
在软件测试中,符号执行可以获得程序执行路径的集合、路径的约束条件和输出的符号表达式,可以使用约束求解器求解出满足约束条件的各个路径的输入值,用于创建高覆盖率的测试用例。符号执行与模糊测试的结合也是当前流行的软件测试技术。
在漏洞挖掘中,通过符号执行技术可以获得漏洞监测点的变量符号表达式,结合路径约束条件、变量符号表达式和漏洞分析规则,可以通过约束求解的方法来求解是否存在满足或违反漏洞分析规则的值。
符号执行还可以用于搜索特定目标代码的到达路径,进而计算该路径的输入,用在面向特定任务(比如代码破解)的程序分析中。
漏洞挖掘-检测是否数组越界
int a[10];
scanf("%d", &i);
if (i > 0) {
if (i > 10)
i = i % 10;
a[i] = 1;
}
- 在a[i]=1语句处存在可能数组越界的情况
访问越界的约束条件是x>=10 - 整段代码存在两个if分支,经过符号执行,知道到达a[i]=1语句处有2条路径:
路径约束条件为x>0∧x<=10,此时变量i的符号表达式为x;
路径约束条件为x>0∧x>10,此时变量i的符号表达式为x%10。 - 得到两个判定条件:
(x>0∧x<=10)∧(x>=10) --有解 x=10 满足越界条件** 存在漏洞**
(x>0∧x>10)∧x%10>=10)
污点分析
污点分析(Taint Analysis)通过标记程序中的数据(外部输入数据或者内部数据)为污点,跟踪程序处理污点数据的内部流程,进而帮助人们进行深入的程序分析和理解。
污点分析可以分为污点传播分析(静态分析)和动态污点分析(动态分析)。静态污点分析技术在检测时并不真正运行程序,而是通过模拟程序的执行过程来传播污点标记,而动态污点分析技术需要运行程序,同时实时传播并检测污点标记。
基本思想
首先,确定污点源,即污点分析的目标来源。通常来讲,污点源表示了程序外部数据或者用户所关心的程序内部数据,是需要进行标记分析的输入数据。
然后,标记和分析污点。对污点源在内存中进行标记、计算涉及到污点的执行过程。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iDM68DL4-1655857034243)(attachment:ad59398cd44ce5524b593fa029934299)]](https://img-blog.csdnimg.cn/d8f2574c518c4581bc4d050e7c25a1e7.png)
污点分析核心要素
- 污点源:是污点分析的目标来源(Source点),通常表示来自程序外部的不可信数据,包括硬盘文件内容、网络数据包等。
- 传播规则:是污点分析的计算依据,通常包括污点扩散规则和清除规则,其中普通赋值语句、计算语句可使用扩散规则,而常值赋值语句则需要利用清除规则进行计算。
- 污点检测:是污点分析的功能体现,其通常在程序执行过程中的敏感位置(Sink点)进行污点判定,而敏感位置主要包括程序跳转和系统函数调用等。
优缺点
污点分析的核心是分析输入参数和执行路径之间的关系,它适用于由输入参数引发漏洞的检测,比如SQL注入漏洞等。
污点分析技术具有较高的分析准确率,然而针对大规模代码的分析,由于路径数量较多,因此其分析的性能会受到较大的影响。
词法分析
基本概念
词法分析通过对代码进行基于文本或字符标识的匹配分析对比,以查找符合特定特征和词法规则的危险函数、API或简单语句组合。
主要思想是将代码文本与归纳好的缺陷模式(比如边界条件检查)进行匹配,以此发现漏洞。
优点:算法简单,检测性能较高
缺点:只能进行表面的词法检测,不能进行语义方面的深层次分析,因此可以检测的安全缺陷和漏洞较少,会出现较高的漏报和误报,尤其对于高危漏洞无法进行有效检测。
漏洞挖掘实战
实践一:基于词法分析和逆向分析的可执行代码静态检测
核心思想:根据二进制可执行文件的格式特征,从二进制文件的头部、符号表以及调试信息中提取安全敏感信息(识别危险函数),来分析文件中是否存在安全缺陷。
- 找到敏感函数,比如memcpy、strcpy等
- 回溯函数的参数
- 判断栈和操作参数的大小关系,以定位是否发生了溢出漏洞
实验一:基于IDA Pro分析给定的可执行文件是否存在溢出漏洞
对于findoverflow.exe,是通过vc6代码生成的Release版本:
#include <stdio.h>
#include <string.h>
void makeoverflow(char *b){
char des[5];
strcpy(des,b);
}
void main(int argc,char *argv[]){
if(argc>1) {
if(strstr(argv[1],"overflow")!=0)
makeoverflow(argv[1]);
} else
printf("usage: findoverflow XXXXX\n");
}
第一步:通过IDA打开所生成的exe文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aIdr58ac-1655857034246)(attachment:7ddd3d97d4a4808d78cfd78667678a03)]](https://img-blog.csdnimg.cn/149a7266fb844eb9a22113d8c642ab53.png)
通过该视图,可见,主要有一个main函数,在该函数中可能有跳转,调用了sub_401000函数、_strstr函数和_printf函数。此外,还定义了两个字符串常量,aUsageFindoverf,在其上点右键->Text view,可以看到:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gB0RNL7T-1655857034248)(attachment:5bf72c22dafd8a0f4fc6301a2c185af5)]](https://img-blog.csdnimg.cn/26ac847bbe9747aebf3df1145cbeda5b.png)
打开main函数汇编代码如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p4czVax5-1655857034249)(attachment:6d4227e5df153af22f4dfbd77a95109f)]](https://img-blog.csdnimg.cn/f07c28a932544b10b8504fdbba8f2b66.png)
注意:通常在IDA的反汇编中,arg_x表示函数参数x的位置,var_8表示局部变量的位置;[]是内存寻址,[x+arg_x]通常表示的就是arg_x的地址值。
由release和debug生成的汇编代码是截然不同的,release版本非常简洁,执行效率优先,debug版本则严格按照语法结构,而且增加了很多方便调试的附加信息。
第二步:定位敏感函数
在主函数中,Printf函数无任何格式化参数存在,因此,敏感函数的可能在于sub_401000函数中,打开该函数的代码如图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5D0MbBCs-1655857034251)(attachment:f25857d5f6215bcb986f3acd66bcec2e)]](https://img-blog.csdnimg.cn/8a0c11985e04430084b56a16ff735a36.png)
- 一个输入参数arg_0,一个局部变量var_8。
- 通过“lea edx, [esp+8+var_8]”和“mov edi, edx”可知,向目标寄存器存储了目标字符串的地址,为局部变量var_8;
- 通过“mov edi,[esp+10h+arg_0]”以及后面的“mov esi, edi”,可知,将函数的输入参数作为源字符串。
那么到底是否发生了溢出呢?
通过“sub esp 8”可以知道栈大小为8,因此,函数的局部变量var_8的大小最大就是8。这样的话,可以得到sub_401000函数的代码结构大致如下:
Sub_401000(arg_0)
{
Char var_8[8];
Strcpy(var_8, arg_0);
}
如果输入的字符串的长度大于8,就可能发生溢出了——需要验证。
为什么是8,而不是源代码里的5?
打开DOS对话框,运行示例程序,如果不给任何参数的话,会提示:usage: findoverflow XXXXX
如果输入参数,比如:findoverflow ssssssssss。却可以运行成功。
这是为什么呢?回顾逆向的反汇编代码,可以知道:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1F6slTmE-1655857034252)(attachment:41ea5fae271f7eebaacef024c2f16dd3)]](https://img-blog.csdnimg.cn/bc3caa79da0a4cb2abfd0dc04a4ca5e4.png)
由于程序需要先判断是否包含子串overflow,因此,需要构造的输入需要满足这个条件。
输入:findoverflow overflow,此时出现缓冲区溢出的弹出窗口了。
基于此溢出漏洞,就可以进行漏洞的利用了。
实验二:使用Bugscam脚本来代替手工过程完成漏洞挖掘
Bugscam是一个IDA工具的idc脚本的轻量级的漏洞分析工具,通过检测栈溢出漏洞的strcpy,sprintf危险函数的位置,然后根据这些函数的参数,确定是否有缓冲区溢出漏洞。
下载网址:https://sourceforge.net/projects/bugscam/
- 将Bugscam文件解压放到任意地方,然后修改globalvar.idc文件中头行的bugscam_dir为你的bugscam目录的全路径(路径不能含有中文)。
- 启动ida,加载任意一个x86程序文件(本例为idc.exe),然后打开脚本文件
run_analysis.idc,运行即可,等待分析完毕,最后的分析报告结果保存在reports目录中的html文件中。
#include <stdio.h>
#include <windows.h>
void vul(char*bu1){
char a[200];
lstrcpy(a,bu1);
printf("%s",a);
return; }
void main(){
char b[1024];
memset(b,'l',sizeof(b));
vul(b); }
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a9F6ri4R-1655857034253)(attachment:1e9f22982a27978274eacd6f9cd9e27a)]](https://img-blog.csdnimg.cn/2c9b184ad4534c6e914d81956a4ded12.png)
其中,Severity是威胁等级,越高说明漏洞危险级别越高。本例的程序中,lstrcpyA函数存在溢出漏洞,地址401010处的代码可能将向目标203字节的区域写入1024字节的数据。
数据流分析
基本概念
数据流分析是一种用来获取相关数据沿着程序执行路径流动的信息分析技术,分析对象是程序执行路径上的数据流动或可能的取值。
按照分析程序路径的深度,将数据流分析分为过程内分析和过程间分析。
数据流分析方法分类
过程内分析只针对程序中函数内的代码进行分析,又分为:
- 流不敏感分析(flow insensitive):按代码行号从上而下进行分析;
- 流敏感分析(flow sensitive):首先产生程序控制流图(Control FLow Graph,CFG),再按照CFG的拓扑排序正向或逆行分析;
- 路径敏感分析(path sensitive):不仅考虑到语句的先后顺序,还会考虑语句可达性,即会沿实际可执行到路径进行分析。
过程间分析则考虑函数之间的数据流,即需要跟踪分析目标数据在函数之间的传递过程。
- 上下文不敏感分析:忽略调用位置和函数取值等函数调用的相关信息。
- 上下文敏感分析:对不同调用位置调用的同意函数加以区分。
程序代码模型
数据流分析使用的程序代码模型主要包括程序代码的中间表示以及一些关键的数据结构,利用程序代码的中间表示可以对程序语句的指令语义进行分析。
抽象语法树。是程序抽象语法结构的树状表现形式,其每个内部节点代表一个运算符,该节点的子节点代表这个运算符的运算分量。通过描述控制转移语句的语法结构,抽象语法树在一定程度上也描述了程序的过程内代码的控制流结构。
举例,对于表达式“1+3*(4-1)+2”,其抽象语法树为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iKM4px80-1655857034254)(attachment:eb993a57d6c3f8ac0783346a45173a47)]](https://img-blog.csdnimg.cn/16b8d65018634010a49ba3b37cf43265.png)
三地址码。三地址码(Three address code,TAC)是一种中间语言,由一组类似于汇编语言的指令组成,每个指令具有不多于三个的运算分量。每个运算分量都像是一个寄存器。
通常的三地址码指令包括下面几种:
x = y op z :表示 y 和 z 经过 op 指示的计算将结果存入 x
x = op y :表示 y 经过操作 op 的计算将结果存入 x
x = y :表示赋值操作
goto L :表示无条件跳转
if x goto L :表示条件跳转
x = y[i] :表示数组赋值操作
x = &y 、 x = *y :表示对地址的操作
param x1, param x2, call p:表示过程调用 p(x1, x2)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9GkkKqfX-1655857034255)(attachment:6fbf143721383084d76afb912e74ad50)]](https://img-blog.csdnimg.cn/d61f000746e540e1984fa9ab53034178.png)
控制流图。控制流图(Control FLow Graph,CFG)通常是指用于描述程序过程内的控制流的有向图。控制流由节点和有向边组成。节点可以是单条语句或程序代码段。有向边表示节点之间存在潜在的控制流路径。
(a)有一个if-then-else语句;(b)有一个while循环;
© 有两个出口的自然环路;(d)有两个入口的循环。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dXl1sJim-1655857034256)(attachment:8a9ccd6ebfc59baf5cd5e82893b3f1b8)]](https://img-blog.csdnimg.cn/db84eeee44454344bba488df3b0504b5.png)
调用图。调用图(Call Graph,CG)是描述程序中过程之间的调用和被调用关系的有向图,满足如下原则:对程序中的每个过程都有一个节点;对每个调用点都有一个节点;如果调用点c调用了过程p,就存在一条从c的节点到p的节点的边。
基于数据流的漏洞分析流程
基于数据流的漏洞分析技术是通过分析软件代码中变量的取值变化和语句的执行情况,来分析数据处理逻辑和程序的控制流关系,从而分析软件代码的潜在安全缺陷。基于数据流的漏洞分析的一般流程为:
- 首先,进行代码建模,将代码构造为抽象语法树或程序控制流图;
- 然后,追踪获取变量的变化信息,根据漏洞分析规则检测安全缺陷和漏洞。
基于数据流的漏洞分析非常适合检查因控制流信息非法操作而导致的安全问题,如内存访问越界、常数传播等。由于对于逻辑复杂的软件代码,其数据流复杂,并呈现多样性的特点,因而检测的准确率较低,误报率较高。
示例一:检测指针变量的错误使用
int contrived(int *p, int *w, int x) {
int *q;
if (x) {
kfree(w); // w free
q = p;
}else
q=w;
return *q; // p use after free
}
int contrived_caller(int *w, int x, int *p) {
kfree(p); // p free
[...]
int r = contrived(p, w, x);
[...]
return *w; // w use after free
}
在检测指针变量的错误使用时,我们关心的是变量的状态。左侧代码可能出现use-after-free漏洞。
漏洞分析规则。下面是用于检测指针变量错误使用的检测规则:
v 被分配空间 ==> v.start
v.start: {kfree(v)} ==> v.free
v.free: {*v} ==> v.useAfterFree
v.free: {kfree(v)} ==> v.doubleFree
代码建模。这里我们采用路径敏感的数据流分析,控制流图如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zg2px3Mb-1655857034257)(attachment:48972ef60673cc4a87055e8dc83c0c82)]](https://img-blog.csdnimg.cn/c3bdd4ec7fad4f02b3c1ddcadbc83ba6.png)
漏洞分析。分析过程从函数contrived_caller的入口点开始,可知调用函数contrived的时候p的状态为p.free。分析函数contrived中的两条路径:
- 1->2->3->4->6:在进行到6时,6的前置条件是p.free、w.free、q.free,此时语句return *q将触发use-after-free规则并设置q.useAfterFree状态。然后返回到函数contrived_caller的4,其前置条件为p.useAfterFree、w.free,此时语句return *w设置w.useAfterFree。因此,存在use-after-free漏洞。
- 1->2->5->6:该路径是安全的。
示例二:检测缓冲区溢出
在检测缓冲区溢出时,我们关心的是变量的取值,并在一些预定义的敏感操作所在的程序点上,对变量的取值进行检查。下面是一些记录变量的取值的规则。
char s[n]; // len(s) = n
strcpy(des, src); // len(des) > len(src)
strncpy(des, src, n); // len(des) > min(len(src), n)
s = "foo"; // len(s) = 4
strcat(s, suffix); // len(s) = len(s) + len(suffix) - 1
fgets(s, n, ...); // len(s) > n
模糊测试
基本概念
- 模糊测试(Fuzzing)是一种自动化或半自动化的安全漏洞检测技术,通过向目标软件输入大量的畸形数据并监测目标系统的异常来发现潜在的软件漏洞。
- 模糊测试属于黑盒测试的一种,它是一种有效的动态漏洞分析技术,黑客和安全技术人员使用该项技术已经发现了大量的未公开漏洞。
- 它的缺点是畸形数据的生成具有随机性,而随机性造成代码覆盖不充分导致测试数据覆盖率不高。
模糊测试分类
基于生成的模糊测试
它是指依据特定的文件格式或者协议规范组合生成测试用例,该方法的关键点在于既要遵守被测程序的输入数据的规范要求,又要能变异出区别于正常的数据。
基于变异的迷糊测试
它是指在原有合法的测试用例基础上,通过变异策略生成新的测试用例。变异策略可以是随机变异策略、边界值变异策略、位变异策略等等,但前提条件是给定的初始测试用例是合法的输入。
模糊测试步骤
- 确定测试对象和输入数据
由于所有可被利用的漏洞都是由于应用程序接受了用户输入的数据造成的,并且在处理输入数据时没有首先过滤非法数据或者进行校验确认。对模糊测试来说首要的问题是确定可能的输入数据,畸形输入数据的枚举对模糊测试至关重要。
- 生成模糊测试数据
一旦确定了输入数据,接着就可以生成模糊测试用的畸形数据。根据目标程序及输入数据格式的不同,可相应选择不同的测试数据生成算法。
- 检测模糊测试数据
检测模糊测试数据的过程首先要启动目标程序,然后把生成的测试数据输入到应用程序中进行处理。
- 监测程序异常
在模糊测试过程中,一个非常重要但却经常被忽视的步骤是对程序异常的监测。实时监测目标程序的运行,就能追踪到引发目标程序异常的源测试数据。
- 确定可利用性
一旦监测到程序出现的异常,还需要进一步确定所发现的异常情况是否能被进一步利用。这个步骤不是模糊测试必需的步骤,只是检测这个异常对应的漏洞是否可以被利用。这个步骤一般由手工完成,需要分析人员具备深厚的漏洞挖掘和分析经验。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lr6sr6ph-1655857034259)(attachment:cacf4f48856672f612de79e96a8c0962)]](https://img-blog.csdnimg.cn/0428b295f604431996aee9f0d4219282.png)
除了最后一步确定可利用性外,所有其它的四个阶段都是必须的。
尽管模糊测试对安全缺陷和漏洞的检测能力很强,但并不是说它对被测软件都能发现所有的错误,原因就是它测试样本的生成方式具有随机性。
智能模糊测试
- 模糊测试方法是应用最普遍的动态安全检测方法,但由于模糊测试数据的生成具有随机性,缺乏对程序的理解,测试的性能不高,并且难以保证一定的覆盖率。
- 为了解决这个问题,引入了基于符号执行、污点传播分析等可进行程序理解的方法,在实现程序理解的基础上,有针对性的设计测试数据的生成,从而实现了比传统的随机模糊测试更高的效率,这种结合了程序理解和模糊测试的方法,称为智能模糊测试(smart Fuzzing)技术。
智能模糊测试具体的实现步骤
- 反汇编
智能模糊测试的前提,是对可执行代码进行输入数据、控制流、执行路径之间相关关系的分析。为此,首先对可执行代码进行反汇编得到汇编代码,在汇编代码的基础上才能进行上述分析。
- 中间语言转换
从汇编代码中直接获取程序运行的内部信息,工作量较大,为此,需要将汇编代码转换成中间语言,由于中间语言易于理解,所以为可执行代码的分析提供了一种有效的手段。
- 采用智能技术分析输入数据和执行路径的关系
这一步是智能模糊测试的关键,它通过符号执行和约束求解技术、污点传播分析、执行路径遍历等技术手段,检测出可能产生漏洞的程序执行路径集合和输入数据集合。例如,利用符号执行技术在符号执行过程中记录下输入数据的传播过程和传播后的表达形式,并通过约束求解得到在漏洞触发时执行的路径与原始输入数据之间的联系,从而得到触发执行路径异常的输入数据。
- 利用分析获得的输入数据集合,对执行路径集合进行测试
采用上述智能技术获得的输入数据集合进行安全检测,使后续的安全测试检测出安全缺陷和漏洞的机率大大增加。与传统的随机模糊测试技术相比,这些智能模糊测试技术的应用,由于了解了输入数据和执行路径之间的关系,因而生成的输入数据更有针对性,减少了大量无关测试数据的生成,提高了测试的效率。此外,在触发漏洞的同时,智能模糊测试技术包含了对漏洞成因的分析,极大减少了分析人员的工作量。
智能模糊测试的核心思想
在于以尽可能小的代价找出程序中最有可能产生漏洞的执行路径集合,从而避免了盲目地对程序进行全路径覆盖测试,使得漏洞分析更有针对性。
智能模糊测试技术的提出,反映了软件安全性测试由模糊化测试向精确化测试转变的趋势。是典型的技术融合的漏洞挖掘测试方法。
模糊测试实践
使用工具
用来实现Fuzzing测试的工具叫做Fuzzer。
成品的Fuzzer工具很多,许多是非常优秀的。Fuzzer根据测试类型可以分为很多类,常见的分类包括:文件型Fuzzer、网络型Fuzzer、接口型Fuzzer等。
下方工具可以生成多个文件测试用例,发现了Office2003的典型漏洞。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cOBjWXbJ-1655857034260)(attachment:51ffe1ce3d9c9227a5be06267f46733b)]](https://img-blog.csdnimg.cn/6f6b5ed8e3274feeb04bbfd00f01755a.png)
自己动手写Fuzzer
使用模糊测试工具在很多时候不能解决所有问题:
- 比如:被测试的目标程序对测试数据有一定的要求,而实际的Fuzzer不能灵活调整发送的测试数据;被测试的目标程序过于简单或者难,而现有的Fuzzer程序不能提供适合的测试。
- 作为漏洞发掘者我们最好能学会编写一个Fuzzer,这样就可以随时随地的进行安全测试。而事实上,目前的多数漏洞挖掘过程,是需要自己手动编写Fuzzer来完成。
对于目标的可执行文件overflow.exe文件,是由如下程序生成的exe程序:
#include <stdio.h>
#include <string.h>
void overflow(char *b){
char des[50];
strcpy(des,b);
}
void main(int argc,char *argv[]){
if(argc>1) {
overflow(argv[1]);
} else
printf("usage: overflow XXXXX\n");
}
书写Fuzzer。在明确了输入的要求和暴力测试的循环条件后,可以写出如下的代码:
void main(int argc,char *argv[]){
char *testbuf=" "; char buf[1024];
memset(buf,0,1024);
if(argc>1) {
for(int i=20;i<50;i=i+2) {
testbuf=new char[i];
memset(testbuf,'c',i);
memcpy(buf,testbuf,i);
ShellExecute(NULL,"open",argv[1],buf,NULL,SW_NORMAL);
delete testbuf;}
}
else printf("Fuzzing X \n其中X为被测试目标程序所在路径");
}
通过一个for循环(循环次数根据实际情况去设计)构造不同的字符串作为输入,通过“ShellExecute(NULL,"open",argv[1],buf,NULL,SW_NORMAL); “来实现对目标程序的模糊测试。
上述Fuzzer的调用格式为:Fuzzing X 。X表示目标程序。
请完成上述实验并进行结果验证。
AFL模糊测试框架
AFL模糊测试框架
- AFL是一款基于覆盖引导(Coverage-guided)的模糊测试工具,它通过记录输入样本的代码覆盖率,从而调整输入样本以提高覆盖率,增加发现漏洞的概率。
- AFL主要用于C/C++程序的测试,被测程序有无程序源码均可,有源码时可以对源码进行编译时插桩,无源码可以借助QEMU的User_Mode模式进行二进制插桩。
- 支持多平台(ARM、X86、X64)、多系统(Linux、BSD、Windows、MacOS),性能高。
AFL工作流程
- 从源码编译程序时进行插桩,以记录代码覆盖率;
- 选择一些输入文件作为初始测试集加入输入队列;
- 将队列中的文件按策略进行“突变”;
- 如果经过变异文件更新了覆盖范围,则保留在队列中;
- 循环进行,期间触发了crash(异常结果)的文件会被记录下来。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZVNN8Puz-1655857034262)(attachment:44936da4faf41a7e6095e54730362d1a)]](https://img-blog.csdnimg.cn/a570b4fefb5d4fcaa52e2447939ce64d.png)
AFL安装
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8lLnoaQ8-1655857034263)(attachment:767dfe02556cda1812d7d3d2825a380c)]](https://img-blog.csdnimg.cn/c351071cbc8d41f487baa50f784ce969.png)
AFL模糊测试
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FV029f0p-1655857034265)(attachment:26d5986914d6d2687da4a849a6d87acf)]](https://img-blog.csdnimg.cn/e3bb3c624fdc474d93aa29b841fdf8ea.png)
以一个白盒模糊测试为例。
创建本次实验的程序
新建文件夹demo,并创建实验的程序Test.c,该代码编译后得到的程序如果被传入“deadbeef”则会终止,如果传入其他字符会原样输出。
使用afl的编译器编译,可以使模糊测试过程更加高效。
命令:afl-gcc -o test test.c
编译后会有插桩符号,使用下面的命令可以验证这一点。
命令:readelf -s ./test | grep afl
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7dnOj8Fy-1655857034266)(attachment:fefb53ad23e06ec65fc9ed36fd0685d5)]](https://img-blog.csdnimg.cn/d3f2528b28db4ce39c2ab952c25719aa.png)
创建测试用例
首先,创建两个文件夹in和out,分别存储模糊测试所需的输入和输出相关的内容。
命令:mkdir in out
然后,在输入文件夹中创建一个包含字符串“hello”的文件。
命令:echo hello> in/foo
foo就是我们的测试用例,里面包含初步字符串hello。AFL会通过这个语料进行变异,构造更多的测试用例。
启动模糊测试
运行如下命令,开始启动模糊测试(@@表示目标程序需要从文件读取输入):
命令:afl-fuzz -i in -o out -- ./test @@
分析crash
观察fuzzing结果,如有crash,定位问题。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NZq3QDyJ-1655857034267)(attachment:01dd17ced6e0b96b2a219c3146416f4a)]](https://img-blog.csdnimg.cn/4ca431be35b94e28a0014cbd9b9d33f3.png)
- 在out文件夹的crashes子文件夹里面是产生crash的样例,hangs里面是产生超时的样例。
- 通常,得到crash样例后,可以将这些样例作为目标测试程序的输入,重新触发异常并跟踪运行状态,进行分析、定位程序出错的原因或确认存在的漏洞类型。
可以说漏洞挖掘是网安和白帽嘿客等专业人员的必备技能了,如果你想在除了上班之后再利用空余时间挖挖漏洞赚赚外快,这是个非常好的选择。我这里有一套自用的网络安全(白帽嘿客)的全套学习籽料,需要的可以给我留言,我看到后就会发你,如果你等不及我回复,可以直接点击链接领取【282G】网络安全&黑客技术零基础到进阶全套学习大礼包,免费分享! ,也可以扫描下方二维码领取(记得备注好来意哦~)。

由于篇幅有限,仅展示部分籽料,需要的可以扫描上方二维码或者点击链接领取哦!
【282G】网络安全&黑客技术零基础到进阶全套学习大礼包,免费分享!