两个协议:
1、NTP(Network Time Protocal)–>广泛使用
机器周期向时间服务器获取准确时间
2、没有协议名称
−
>
->
−>没有广泛使用
时间服务器周期扫描所有机器,计算时间平均值;导致时间服务器负载大,不广泛使用
逻辑时钟(logical clock)
是一种次序时间,而非准确物理时钟(an ordering time,not exact time)
a.happened-before relation
假设a,b是同一进程(process)的两个事件(event),a在b前到达:a–>b
a
发送,
b
接收
a发送,b接收
a发送,b接收:
a
−
>
b
a->b
a−>b
a
−
>
b
,
b
−
>
c
a->b,b->c
a−>b,b−>c:
a
−
>
c
a->c
a−>c
b.若无法判断
a
−
>
b
a->b
a−>b还是
b
−
>
a
b->a
b−>a(即先后顺序未知):a,b是平行事件(concurrent)
逻辑时刻(logical timestamp)
记事件event的逻辑时刻(logical timestamp)为 C ( e v e n t ) C(event) C(event)。若 a − > b , 则 C ( a ) < C ( b ) a->b,则C(a)<C(b) a−>b,则C(a)<C(b)
如果没有中心结点如何计算逻辑时刻??:
1、对于进程
i
i
i,有事件发生时
C
i
=
C
i
+
1
C_i = C_i + 1
Ci=Ci+1
2、有消息(message)发送时,消息中带有
t
s
(
m
)
=
C
i
ts(m) = C_i
ts(m)=Ci
3、对于收到消息的进程
j
j
j,更新本地
C
j
=
m
a
x
{
C
j
,
t
s
(
m
)
}
C_j=max\{C_j,ts(m)\}
Cj=max{Cj,ts(m)},然后
C
j
=
C
j
+
1
C_j = C_j+1
Cj=Cj+1
例子:
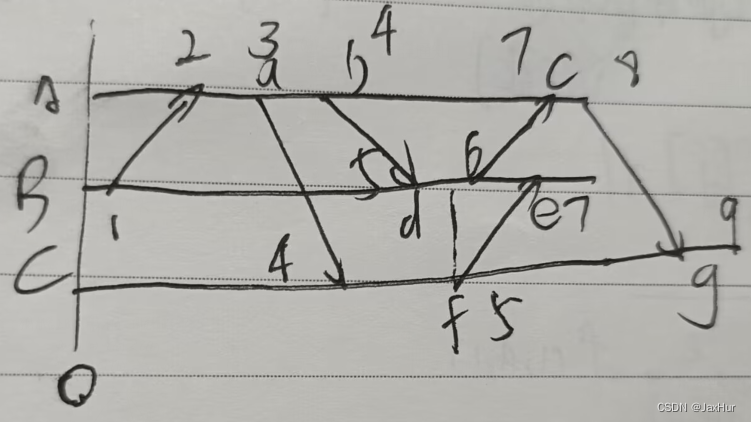
会产生问题:冲突
完全有序多播(totally ordered multicast)
对于员工奖励,是先增加1000元、再提成1%?还是先提成1%、再增加1000元?假如员工和经理都会向自己的服务器(员工服务器、经理服务器)发送更新。由于顺序的原因,员工服务器是先增加1000元、再提成1%,经理服务器是先提成1%、再增加1000元。最终两个服务器数据同步时,会发生冲突,怎么解决?
解决方案:根据公司规章制度来(业务逻辑),对于特殊员工,特殊接口对待
不同机器上时间戳不同,用逻辑时钟??
1、
a
−
>
b
,则推导出
C
(
a
)
<
C
(
b
)
a->b,则推导出C(a)<C(b)
a−>b,则推导出C(a)<C(b)
2、但是
C
(
a
)
<
C
(
b
)
,不能推导出
a
−
>
b
C(a)<C(b),不能推导出a->b
C(a)<C(b),不能推导出a−>b
 # 矢量时钟(Vector clock)
# 矢量时钟(Vector clock)
结论:???没有拍到
运行步骤:
1、对于每个进程
P
i
P_i
Pi,有向量
V
C
i
[
1
,
.
.
.
.
.
n
]
VC_i[1,.....n]
VCi[1,.....n],
n
n
n为总的进程数,所有元素初始化为0
2、
P
i
P_i
Pi发送消息
m
m
m,则
V
C
i
[
i
]
+
1
VC_i[i]+1
VCi[i]+1,以及发送的消息
m
m
m带上
V
C
i
VC_i
VCi作为消息的矢量时钟
V
t
(
m
)
Vt(m)
Vt(m)
3、进程
P
j
P_j
Pj从
P
i
P_i
Pi接收消息
m
m
m和矢量时间戳
t
s
(
m
)
ts(m)
ts(m) =Vt(m)???
1.更新
V
C
j
VC_j
VCj,对于
V
C
j
VC_j
VCj的每个元素
V
C
j
[
k
]
=
m
a
x
{
V
C
j
[
k
]
,
t
s
(
m
)
[
k
]
}
VC_j[k] = max\{VC_j[k],ts(m)[k]\}
VCj[k]=max{VCj[k],ts(m)[k]}
2.
V
C
j
[
j
]
+
1
VC_j[j]+1
VCj[j]+1
举例:

解释:P0,P1,P2初始均为(0,0,0)。
首先
P
1
P_1
P1发生事件
a
a
a,更新
V
C
0
[
0
]
=
0
+
1
VC_0[0] = 0+1
VC0[0]=0+1,且发送消息
t
s
(
m
)
=
(
1
,
0
,
0
)
ts(m) = (1,0,0)
ts(m)=(1,0,0),同时
P
1
P_1
P1发生事件
c
c
c,更新
V
C
1
[
0
]
=
0
+
1
VC_1[0] = 0+1
VC1[0]=0+1,没有发送消息;然后
P
1
P_1
P1发生事件
d
d
d,接收来自
P
0
P_0
P0的消息
m
m
m,更新
V
C
1
[
k
]
=
m
a
x
{
V
C
1
[
k
]
,
t
s
(
m
)
[
k
]
}
VC_1[k] = max\{VC_1[k],ts(m)[k]\}
VC1[k]=max{VC1[k],ts(m)[k]},然后
V
C
1
[
1
]
+
1
VC_1[1]+1
VC1[1]+1。接下来是一个道理
讨论:在大型网络中,那种时钟合适(物理、逻辑、矢量)??
解答:同步是为了进行数据同步,保证数据一致性,在超大型网路中,数据同步需求低(Oracle最多支持9个数据副本同步);在小批量网络中,矢量时钟最合适,逻辑时钟具有发生冲突的根本矛盾。
mutual exclusion
三大要求:
1.safety:只有一个进程在给定时间进入临界区工作
2.liveness:请求进入与退出都会成功—即每个进程不会一直待在临界区内
3.fairness:先来后到,先请求先服务
进程根据token进入临界区工作
有中心结点
由中心结点进行调度,

无中心结点
基于逻辑环ring-based solution
谁有token令牌谁进入工作
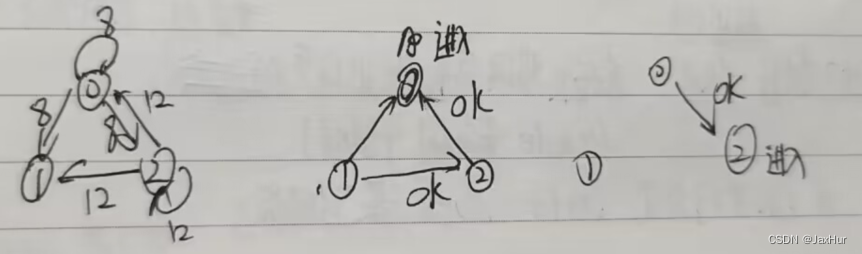
RA算法(Ricart-Agrawala)基于多播(muticast)
·进程
P
i
P_i
Pi想进入临界区时,向其它所有进程发送REQUEST广播消息
·进程
P
j
P_j
Pj收到进程
P
i
P_i
Pi的请求。
若进程
P
j
P_j
Pj没有请求临界区、也没有正在执行临界区,则立即返回REPLY消息。
若进程
P
j
P_j
Pj正在请求临界区,但其时间戳大于进程
P
i
P_i
Pi的请求,则立即返回REPLY消息。
否则,进程
P
j
P_j
Pj延迟返回REPLY)消息,并设置〖RD】[风=1,其中RD数组记录了所有被延迟发送返回消息的进程;直至
P
j
P_j
Pj自己完成后再发送
选举算法election algorithms
有一个leader或coordinator(尽管存在单点故障(single point of failure)、瓶颈(bottleneck)等问题。
如何动态选举出一个特殊进程作为leader (选举算法解决了单点故障问题)
没有前领导人,谁触发选举不重要
假设:
1、每个进程均有相应的优先级(权值),一般按照编号来)
2、优先级最高的成为leader
暴力枚举(Bully)
思想:谁的 ID 最大或最小谁来当老大(一般选择 ID 大的)。
规则:1.leader不响应或相应超时,则触发选举
2.从ID小的开始向上选举
3.故障结点复活了,是否抢回leader位---->否,可以容忍一些
优先级大的结点一直当leader,持续高负荷工作,内存碎片增加,工作效率降低
Ring(基于环)
message绕环一圈,就有了全局的信息,知道有哪些结点,将最大编号的作为leader
RA算法参考:https://blog.csdn.net/happy990/article/details/95032371