1、栈
1.1、栈的概念及结构
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。__进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。__栈中的数据元素遵守__后进先出(先进后出)__LIFO(Last In First Out)的原则。
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据也在栈顶。
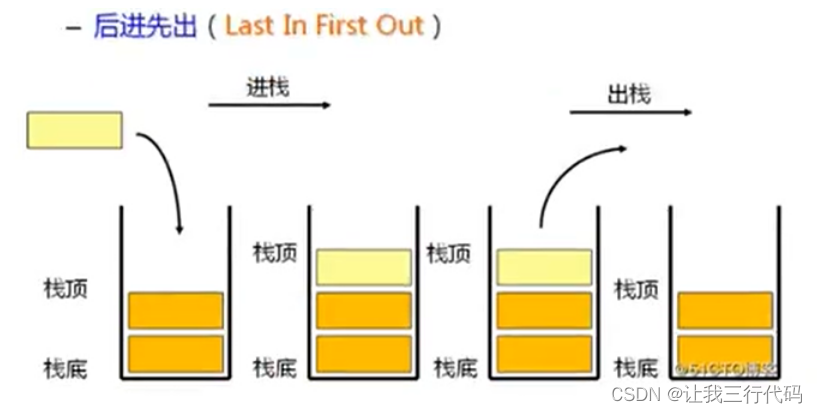
栈(stack)是一种特殊的线性表,是限定仅在一端(通常是表尾)进行插入和删除操作的线性表。
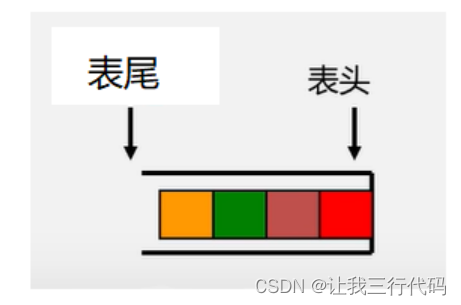
栈是仅在表尾进行插入、删除操作的线性表。
表尾(即an端)称为栈顶Top;表头(即a1端)称为栈底Base。
例如:
栈 S = (a1,a2,a3…an)
总结:表尾对应栈顶,表头对应栈底。
栈有两种:数组栈,链表栈。

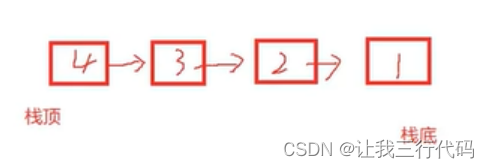
链式栈:
- 如果是用尾做栈顶,尾插尾删,要设计成双向链表,否则删除数据效率低。
- 如果是用头做栈顶,头插头删,要设计成单向链表。
两种都可以,非要选一种,数组栈结构稍微好一点。
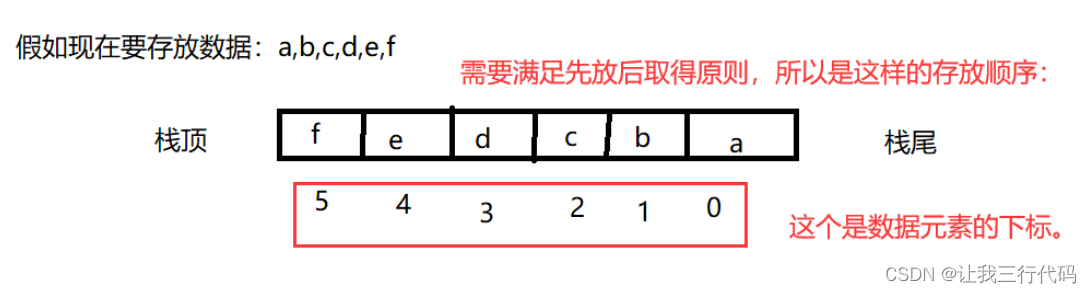
数组栈存放数据的方式:
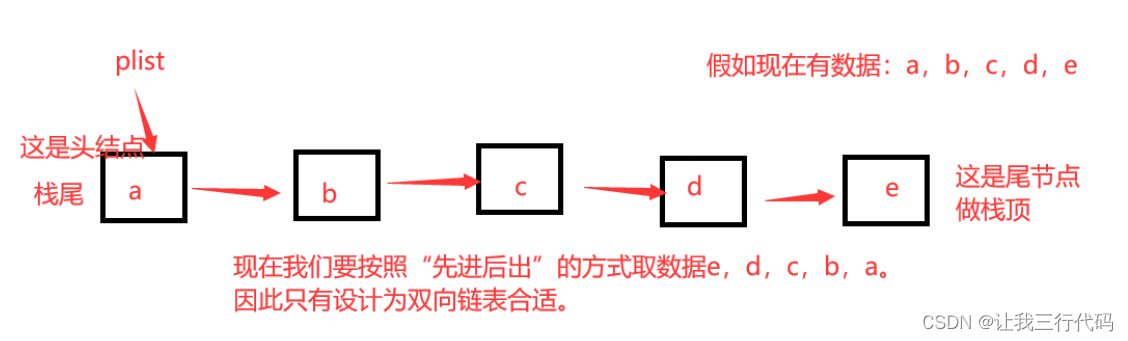
链式栈存放数据的方式:
-
尾做栈顶:
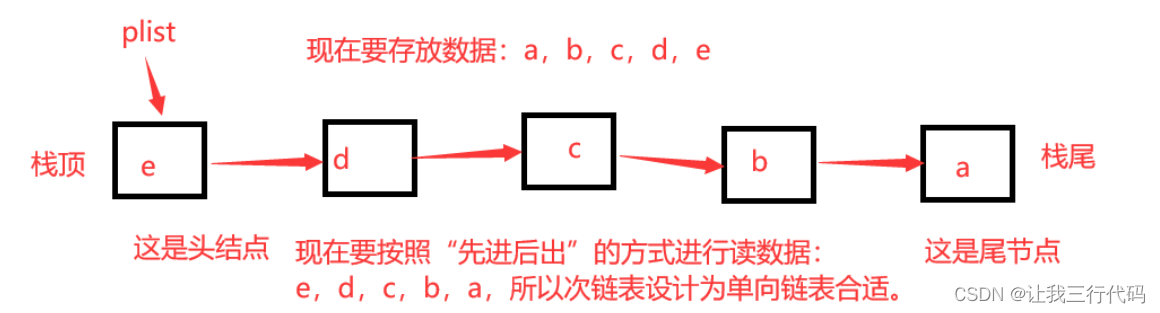
-
头做栈顶
总结:栈和队列时线性表的子集,是插入金额删除位置受限的线性表。
1.2、栈的思考题
问:假设与3个元素a,b,c。入栈顺序是a,b,c。
则它们的出栈出栈顺序有几种可能?
答案:5种可能。下面解释:
(1)c、b、a。原因:入栈顺序为a、b、c,然后依次取出。
(2)a、b、c。原因:a先入栈,然后出栈,之后b入栈,b出栈,最后c入栈,c出栈。
(3)a、c、b。原因:a先入栈,然后出栈,之后b、c入栈,最后,c、b出栈。
(4)b、a、c。原因:a、b先入栈,之后b、a出栈,最后c入栈,c出栈。
(5)b、c、a。原因:a、b先入栈,之后b出栈,然后c入栈,最后c、a出栈。
2、顺序栈的实现(用数组实现)
栈主要有以下几个接口函数
- 初始化栈(StackInit)
- 销毁(StackDestroy)
- 栈顶插入数据(StackPush)
- 栈顶删除数据(StackPop)
- 取栈顶数据(StackTop)
- 统计栈种元素个数(StackSize)
- 判断栈是否为空(StackEmpty)
2.1、定义结构体和main函数
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>
typedef int SLDataType;
typedef struct Stack
{
SLDataType* a;
int top; //栈顶
int capacity;
};
main函数
#include "stack.h"
int main()
{
ST st;
return 0;
}
2.2、初始化栈
//初始化栈
void StackInit(ST* ps)
{
assert(ps);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
2.3、销毁
//销毁
void StackDestory(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
2.4、栈顶插入数据
//栈顶插入数据
void StackPush(ST* ps, SLDataType x)
{
assert(ps);
if (ps->top == ps->capacity)
{
int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;
SLDataType* tmp = (SLDataType*)realloc(ps->a, sizeof(SLDataType) * newcapacity);
if (tmp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
ps->a = tmp;
ps->capacity = newcapacity;
}
ps->a[ps->top] = x;
ps->top++;
}
2.5、栈顶删除数据
//栈顶删除数据
void StackPop(ST* ps)
{
assert(ps);
assert(ps->top > 0);
ps->top--;
}
2.6、取栈顶元素
//取栈顶数据
SLDataType StackTop(ST* ps)
{
assert(ps);
assert(ps->top > 0);
return ps->a[ps->top - 1];
}
2.7、统计栈中元素个数
//统计栈中元素个数
int StackSize(ST* ps)
{
return ps->top;
}
2.8、判断栈是否为空
//判断栈是否为空
bool StackEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
}
3、全代码展示
这里使用三个文件:
- stack.h:用于结构体、各种函数接口的声明
- stack.c:用于各种函数接口的定义。
- test.c:用于创建链表,实现链表。
3.1、stack.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top; //栈顶
int capacity;
}ST;
void StackInit(ST* ps);
void StackDestroy(ST* ps);
void StackPush(ST* ps, STDataType x);
void StackPop(ST* ps);
STDataType StackTop(ST* ps); //取栈顶的数据
int StackSize(ST* ps); //统计栈里面有多少个数据
bool StackEmpty(ST* ps);
3.2、stack.c
#include "stack.h"
void StackInit(ST* ps)
{
assert(ps);
ps->a = NULL;
//初始化时,top给的是0,意味着top指向栈顶数据的下一个。
//初始化时,top给的是-1,意味着top指向栈顶数据。
ps->top = 0;
ps->capacity = 0;
}
void StackDestroy(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
void StackPush(ST* ps, STDataType x)
{
assert(ps);
if (ps->top == ps->capacity)
{
int newCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
STDataType* tmp = realloc(ps->a, sizeof(STDataType) * newCapacity);
if (tmp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
ps->a = tmp;
ps->capacity = newCapacity;
}
ps->a[ps->top] = x;
ps->top++;
}
//删除数据
void StackPop(ST* ps)
{
assert(ps);
assert(ps->top > 0);
ps->top--;
}
STDataType StackTop(ST* ps) //取栈顶的数据
{
assert(ps);
assert(ps->top > 0);
return ps->a[ps->top-1];
}
int StackSize(ST* ps) //统计栈里面有多少个数据
{
return ps->top;
}
bool StackEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
}
3.3、test.c
#include "stack.h"
void TestStack()
{
ST st;
StackInit(&st);
StackPush(&st, 1);
StackPush(&st, 2);
StackPush(&st, 3);
StackPush(&st, 4);
StackPush(&st, 5);
StackPush(&st, 6);
//遍历栈元素
while (!StackEmpty(&st))
{
printf("%d ", StackTop(&st));
StackPop(&st);
}
StackDestroy(&st);
}
int main()
{
TestStack();
return 0;
}
4、链栈的实现(用链表实现栈)
链栈的实现(用链表实现栈)
前面说过链栈的实现有两种方式:
- 链表头做栈顶,这样只需要单链表即可。
- 链表尾做栈顶,这样需要双向链表。
这里我们就以单链表的形式实现链表。
以单链表的形式实现链表,链表的结构如下:
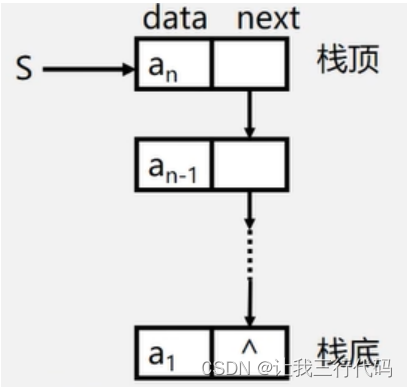
这个样的链表有如下特性:
- 链表的头指针就是栈顶。
- 不需要头结点。
- 基本不存在栈满的情况(需要结点就立即申请即可)。
- 空栈相当于头指针指向NULL。
- 插入和删除仅在栈顶处执行。
栈主要是用数组实现,链栈稍微少一点,所以这里直接放全代码,不在一个接口一个接口的分析了。
以下是个人写的版本
4.1、stack.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>
typedef int SLDataType;
typedef struct Stack
{
struct Stack* Next;
SLDataType data;
}ST;
//销毁
void StackDestory(ST** pps);
//插入数据
void StackPush(ST** pps, SLDataType x);
//删除数据
void StackPop(ST** pps);
//取栈顶元素
SLDataType StackTop(ST** pps);
//统计栈里面有多少个数据
int StackSize(ST** pps);
//判断栈是否为空
bool StackEmpty(ST** pps);
4.2、stack.c
#include "stack.h"
//插入数据
void StackPush(ST** pps, SLDataType x)
{
//先扩容
ST* newnode = (ST*)malloc(sizeof(ST));
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
newnode->data = x;
newnode->Next = *pps;
*pps = newnode;
}
//销毁
void StackDestory(ST** pps)
{
ST* cur = *pps;
while (cur)
{
ST* next = cur->Next;
free(cur);
cur = next;
}
*pps = NULL;
}
//删除栈顶
void StackPop(ST** pps)
{
assert(*pps != NULL);
ST* next = (*pps)->Next;
free(*pps);
*pps = next;
}
//取栈顶元素
SLDataType StackTop(ST** pps)
{
assert(*pps != NULL);
return (*pps)->data;
}
//统计栈里面有多少个数据
int StackSize(ST** pps)
{
assert(*pps != NULL);
int count = 0;
ST* cur = *pps;
while (cur)
{
count++;
cur = cur->Next;
}
return count;
}
//判断栈是否为空
bool StackEmpty(ST** pps)
{
assert(pps);
return *pps == NULL;
}
4.3、test.c
#include "stack.h"
int main()
{
ST* st = NULL;
StackPush(&st, 1);
StackPush(&st, 2);
StackPush(&st, 3);
StackPush(&st, 4);
StackPush(&st, 5);
StackPush(&st, 7);
ST** cur = &st;
while (*cur)
{
st = *cur;
printf("%d ", StackTop(&st));
StackPop(&st);
}
StackDestory(&st);
return 0;
}
5、栈与递归
递归的定义:
- 若一个对象部分的包含它自己,或用它自己给自己定义,则称这个对象是递归的。
- 若一个过程直接的或间接的调用自己,则称这个过程是递归的过程。
以下三种情况常常用到递归方法
- 递归定义的数学函数。
- 阶乘函数。
- 斐波那契数列。
- 具有递归特性的数据结构。
- 二叉树。
- 广义表。
- 可递归求解的问题。
- 迷宫问题。
- Hanoi塔问题。
递归问题————使用分治法求解
__分治法:__对于一个较为复杂的问题,能够分解成几个相对简单的且解法相同或类似的子问题来求解。
使用分治法的三个条件:
- 能将一个问题转变为一个新问题,而新问题与原问题的解法相同或类同,不同的仅是处理的对象,且这些对象是变化有规律的。
- 可以通过上述转化而使问题简化。
- 必须有一个明确的递归出口,或称为递归边界。
我们再来分析函数递归掉调用过程:
调用前,系统完成:
- 将实参,返回地址等传递给被调用函数。
- 为被调用函数的局部变量分配存储区。
- 将控制转移到被调用函数。
调用后,系统完成:
- 保存被调用函数的计算结果。
- 释放被调用函数的数据区。
- 依照被调用函数保存的返回地址将控制转移到调用函数。