title: Nvidia计算卡扫盲
sidebarDepth: 4
layout: AtmLayout
GPU
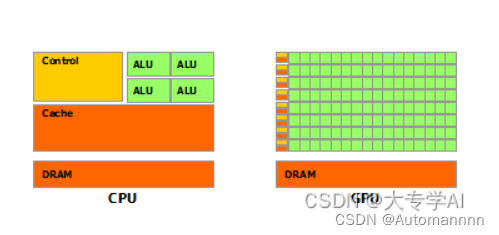
- 大的方面来讲, 由显存+计算单元组成;
显存
- GPU板卡上的DRAM
- 容量大,速度慢,CPU和GPU都可以访问
计算单元
-
Streaming Multiprocessor,执行计算,
-
每个SM都有自己的控制单元,寄存器,缓存,指令流水线
-
每个SM包含多个CUDA核心,又称为Streaming Processor,一个CUDA核心,相当于一个微型CPU;
英伟达显卡分类
- 英伟达开发出了五大产品系列,分别是
GeForce,Quadro,Tesla,GRID,NVS,
GeForce,主流消费级显卡
- 主要用于高性价比的家庭娱乐
- 代号有
GT,GTX,GTS,RTX;命名规则参考参考文档 - 常见型号有:
GTX1050,GTX1050ti,GTX1060,GTX1070,GTX1080,GTX1080ti,RTX2060,RTX2070,RTX2080,RTX2080ti,RTX3080,RTX3090,RTX4080,RTX4090
Quadro,专业级显卡
- 主要针对设计,建模,视觉分析领域,高计算性能,低功耗,低延迟
- 常见型号有:
Quadro K620,Quadro K1200,Quadro K2200,Quadro K4000,Quadro K4200,Quadro K5000,Quadro K5200,Quadro P400,Quadro P600,Quadro P1000,Quadro P2000,Quadro P4000,Quadro P5000,Quadro P6000
Tesla, 深度学习卡
- 主要用于深度学习
- 常见型号有:
Tesla K40, Tesla K80, Tesla P4, Tesla P40, Tesla P100, Tesla V100, Tesla T4, Tesla M40, Tesla M60, A40, A100, A800
NVS
- 主要用于多屏显示
- 常见型号有:
NVS 310, NVS 315, NVS 510, NVS 810, NVS 510M, NVS 810M
GRID
- 主要用于虚拟化技术
- 常见型号有:
GRID K1, GRID K2 , GRID M60-1Q, GRID M60-2Q
N卡性能指标
架构
- 从推出时间来看,
Tesla<Fermi<Kepler<Maxwell<Pascal<Volta<Turing<Ampere - Pascal系列的GPU代号为GP,最后一位数字越小,意味着这颗核心的地位越高。*
- GP100>GP102>GP104>GP106;GP100主要用于科学计算,GP102开始民用核心;
- GP102的完整规格是6个GPC,可以理解为6核GPU,GP104是4核,GP106是双核
- 同代号中,CUDA核心越高,则其性能越高;
- 同一款GPU,可能有多种流处理器规格,也就是多种CUDA核心,老黄的刀法好是说他阉割GPU的技艺特别高超;
流处理器
- Streaming Processor, N卡称为CUDA核心
- 流处理器,代表了并行处理的能力。理论上来说,CUDA核心决定了计算速度的上限。(个人猜测)
- 以Tesla P40为例,其含有
计算性能
Fp64,双精度计算性能
- 双精度主要用于HPC(High Performance Computing)领域
- 深度学习使用FP32跟FP16就以足够;
FP32,单精度计算性能
- 浮点数使用32位表示,具有较高的精度和动态范围
- 通常训练神经网络模型的时候,默认使用的数据类型就是单精度FP32
FP16,半精度计算性能
- 浮点数使用16位表示,减少存储空间和计算开销;
- 按照理论来说,可以跑机器学习等任务;但是会出现精度溢出和舍入误差
- FP16在图像处理有更大优势
INT8,整型算力
- 使用固定的小数点位置表示数值,数据量相对较小,计算速度可以更快
- 元宇宙(虚拟数字人),人脸识别等利用训练完毕的模型进行推理的业务适用于整型精度算力
Tesla性能指标整理
- 整数运算单位:TOPS, 万亿次整数运算每秒;
- 浮点数运算单位: TFLOPS,万亿次浮点数运算每秒;
- 下表部分内容由chatgpt整理,不保证100%正确率,仅供参考;
| 显卡名称 | 架构 | 架构代号 | CUDA核心 | fp64 | fp32 | fp16 | int8 | 单精度性能量表 | 某宝价位 |
|---|---|---|---|---|---|---|---|---|---|
| Tesla M40 | Maxwell | GM200 | 3072 | 0.2 | 7 | / | / | 0.58 | 600左右 |
| Tesla M4 | Maxwell | GM206 | 1024 | / | 2.2 | / | / | 0.18 | / |
| Tesla P100 | Pascal | GP100 | 3584 | 4.7 | 9.3 | 18.7 | / | 0.77 | 1100左右 |
| Tesla P40 | Pascal | GP102 | 3840 | 0.36 | 12 | / | 47 | 1 | 900左右 |
| Tesla P4 | Pascal | GP104 | 2560 | / | 5.5 | / | 22 | 0.45 | 400左右 |
| Tesla V100 | Volta | GV100 | 5120 | 7 | 14 | 112 | / | 1.16 | 9000左右 |
| T4 | Turing | TU104 | 2560 | / | 8.1 | 65.7 | 130.5 | 0.67 | 5400左右 |
| Tesla A10 | Ampere | GA102 | 9216 | / | 31.2 | 62.5 | 250 | 2.6 | 10500左右 |
| Tesla A100 | Ampere | GA100 | 6912 | 19.5 | 156 | 312 | 13 | 135000左右 | |
| RTX 2080 Ti | Turing | TU102 | 4352 | 0.4 | 13.45 | 26.9 | 227 | 1.12 | 2500左右 |
粗略衡量指标
-
模型推理时,单精度情况下,上表中,除了A系架构,主流显卡均差距不大;
-
A系架构,只有A100有显著提升;其他有所提升,但还是在同一个数量级;
-
与2080Ti的对比上,除了int8整型有较为明显的速度提升(4倍多),单精度与版精度相差不大;换言之,跑图适合换,但是大模型换的性价比较低;
-
就训练而言,可选择的不多,P100,V100,A100,个人开发者几乎玩不了;
参考文档
nvidia gpu架构
AMD和Nvidia显卡系列相关对比
GPU架构解析 + CUDA编程基础
芯片算力和精度(int8、fp16、双精度、单精度等等)是怎样的关系?
如何快速判断一张显卡的性能-N卡篇
tesla显卡天梯图
…