安装
pip install lxml
导入
from lxml import etree
xpath使用路径表达式提取html文档中的元素或元素集,然后元素通过沿路径path或步steps来选取数据
XPath常用语法格式
| 表达式 | 描述 |
|---|---|
| div | 选取div元素的所有子元素 |
| /div | 选取根元素div |
| ul//li | 选取ul元素下的所有li子元素 |
| //@class | 选取所有具有class属性的元素 |
| ul/li/[1] | 选取ul元素下的第一个li子元素 |
| //div[@id=‘t2’] | 选取id属性为t2的所有div元素 |
| //li[@class=‘box’] | 选取class属性为box的li子元素 |
| /div/ui/li[@class=‘top’] | 选取根元素div下ul元素下的class属性为top的li子元素 |
| //li/a/@href | 获取li元素下所有a元素的href值 |
| //li/a/text() | 获取li元素下所有a元素的文本内容 |
使用xpath匹配数据实践
爬取彼岸图4k高清动漫壁纸 https://pic.netbian.com/4kdongman/
爬取第一页的图片
import requests
from lxml import etree
import os
url = 'https://pic.netbian.com/4kdongman/index.html'
r = requests.get(url)
r.encoding='gbk'
html = etree.HTML(r.text)# <Element html at 0x11647c63ec8>
img_urls = html.xpath("//div[@class='slist']/ul/li/a/@href")# ['/tupian/32274.html', '/tupian/32257.html', ...
for img_url in img_urls:
# 第二层url
img_url = 'https://pic.netbian.com' + img_url
rr = requests.get(url=img_url)
rr.encoding='gbk'
img_html = etree.HTML(rr.text)
img_name = img_html.xpath("//a[@id='img']/img/@title")[0]
# 高清图片的src
img_src = 'https://pic.netbian.com' + img_html.xpath("//a[@id='img']/img/@src")[0]
rimg = requests.get(url = img_src)
# 可以改文件夹的名字
folder_name = 'dongman'
if not os.path.exists(folder_name):
os.mkdir(folder_name)
# 保存图片
with open(f'{folder_name}/{img_name}.jpg','wb') as f:
f.write(rimg.content)
print(img_name)
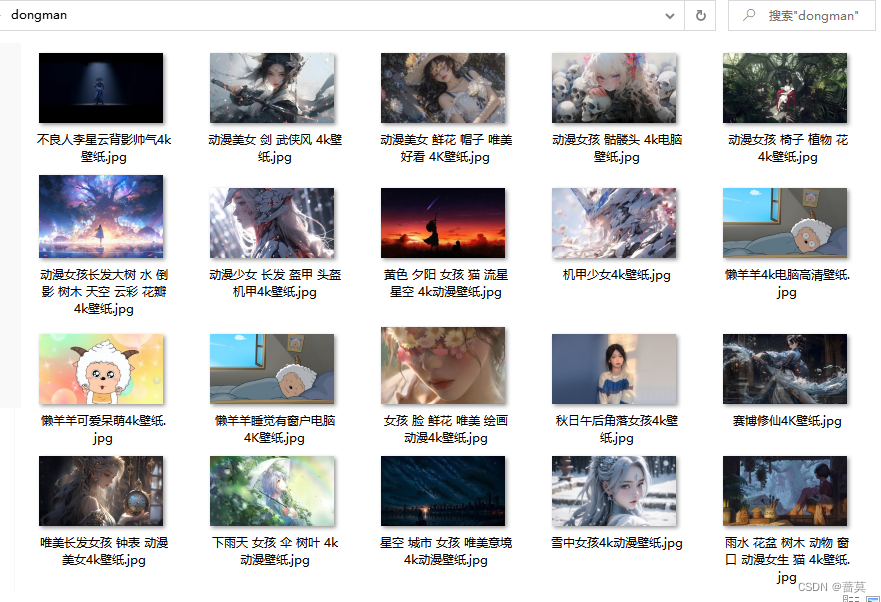
批量爬取多页图片