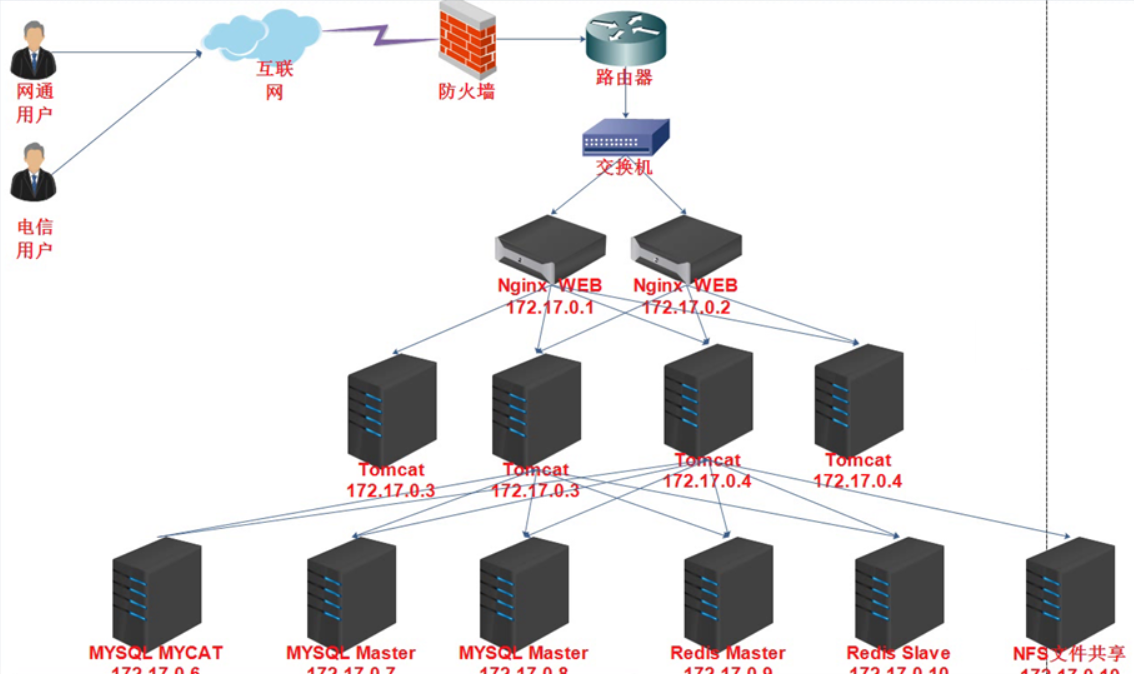
目录
1. 能干什么
2. 如何分析
3. 各字段解释
1. 能干什么
使用 explain+sql 的方式,分析查询语句的性能瓶颈。
① 表的读取顺序;② 数据读取操作的操作类型;③ 哪些索引可以使用;④ 哪些索引被实际使用;⑤ 表之间的引用;⑥ 每张表有多少行被优化器查询。
2. 如何分析
先看一下,执行下面每一条 SQL 后各自对应的结果。
EXPLAIN SELECT * FROM USER WHERE NAME = "刘德华"
EXPLAIN SELECT * FROM USER WHERE NAME = "栈老师"
EXPLAIN SELECT * FROM USER WHERE ID = 1
EXPLAIN SELECT * FROM USER WHERE ID = 5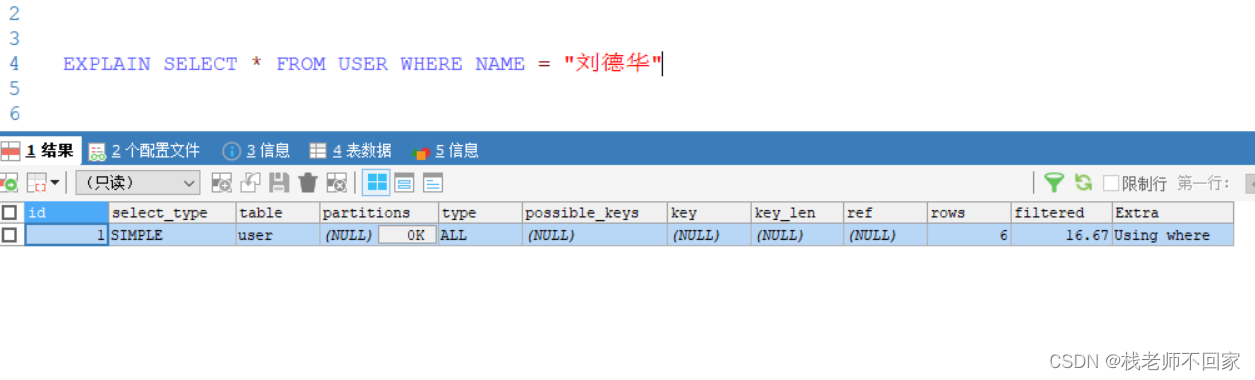
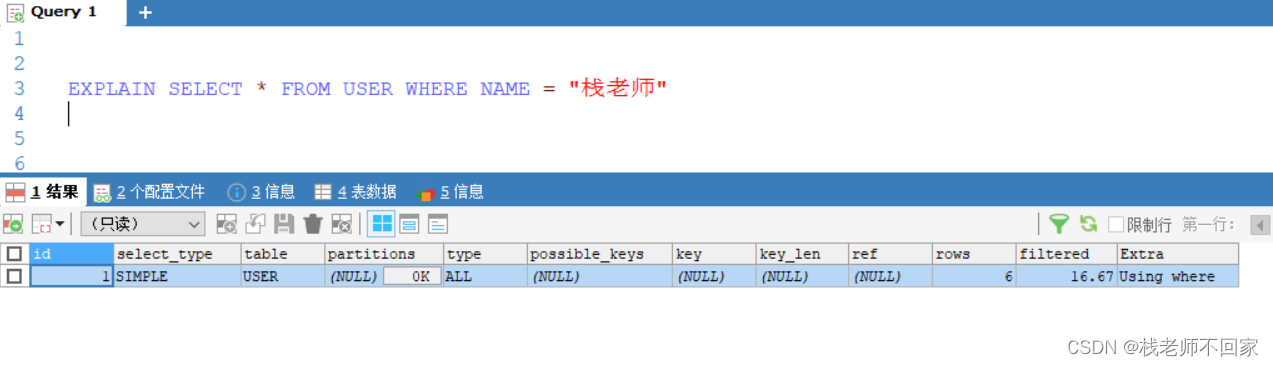
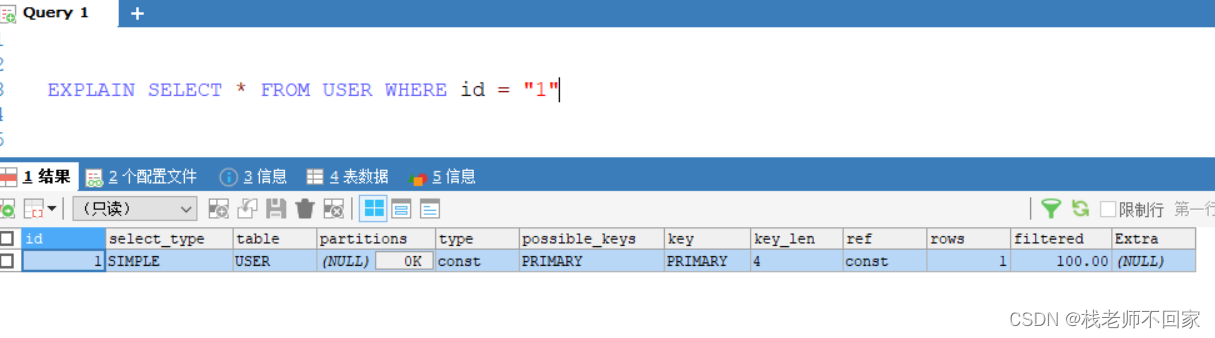
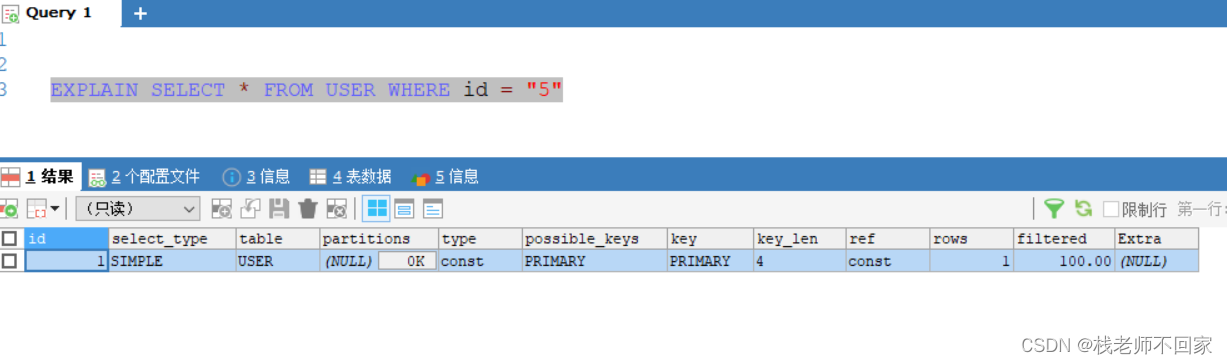
先进行一下简单的分析,从执行计划中可以看出:
① 依据索引查的话,type 和 ref 的值都为 const,而依据名字查时,type 的值是 all,代表全表查找,ref 为空;
② 索引查询相关的 key 列都是 primary,并且 key 的长度正是索引的长度(int 类型为 4);
③ row 代表找到数据之前,扫描的行数,索引查询的 row 为 1,名字查询的 row 为 6,因为它要进行全表扫描,扫描 6 条数据;
④ filtered = 100 * 最终记录数 / 扫描记录数,显然,filter 越大性能越好。对于索引查询,我们最终查到了一条数据,它也只扫描了一次,所以最终的 filtered 就是 100,名字查询的 filter = 100 * 1 / 6 = 16.67。
3. 各字段解释
1. id
:
select
查询的序列号,包含一组数字,表示查询中执行
select
子句或操作表的顺序。
2. select_type:代表查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询,取值范围如下:
simple
:简单的
select
查询,查询中不包含子查询或者
UNION
primary
:查询中若包含任何复杂的子部分,最外层查询则被标记为
primary
derived
:在
FROM
列表中包含的子查询被标记为
DERIVED (
衍生
)
,
MySQL
会递归执行这些
子查询
,
把结果放在临时表里。
subquery
:在
SELECT
或
WHERE
列表中包含了子查询
depedent subquery
:在
SELECT
或
WHERE
列表中包含了子查询,子查询基于外层
uncacheable subquery
:无法使用缓存的子查询
union
:若第二个
SELECT
出现在
UNION
之后,则被标记为
UNION
;若
UNION
包含在
FROM
子句的子查询中,外层
SELECT
将被标记为:
DERIVED
union result
:从
UNION
表获取结果的
SELECT
3. table
:这个数据是基于哪张表的。
4. type:是查询的访问类型。是较为重要的一个指标,结果值从最好到最坏依次是:
system > const > eq_ref > ref > range > index > ALL。
system
:表只有一行记录(等于系统表),这是
const
类型的特列,平时不会出现,这个也
可以忽略不计。
const
:表示通过索引一次就找到了,
const
用于比较
primary key
或者
unique
索引。因为
只匹配一行数据,所以很快。如将主键置于
where
列表中,
MySQL
就能将该查询转换为一个
常量。
eq_ref
:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一
索引扫描。
ref
:非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,它返回
所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫
描的混合体。
range
:只检索给定范围的行,使用一个索引来选择行。
key
列显示使用了哪个索引一般就是
在
where
语句中出现了
between
、
<
、
>
、
in
等的查询这种范围扫描索引扫描比全表扫描要
好,因为它只需要开始于索引的某一点,而结束语另一点,不用扫描全部索引。
index
:出现
index
是
sql
使用了索引但是没用索引进行过滤,一般是使用了覆盖索引或者是
利用索引进行了排序分组。
all
:将遍历全表以找到匹配的行。
5. possible_keys
:显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索
引,则该索引将被列出,但不一定被查询实际使用。
6. key
:实际使用的索引。如果为
NULL
,则没有使用索引。
7. key_len
:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。
key_len
显示的值为索引字段的最大可能长度,并非实际使用长度。
8. ref
:显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。
9. rows
:显示
MySQL
认为它执行查询时必须检查的行数,越少越好。
10. Extra:其他的额外重要的信息。